






论文标题
KSOD:Knowledge Supplement for LLMs On Demand
论文地址
https://arxiv.org/pdf/2503.07550
作者背景
北京大学计算机学院,多媒体信息处理
前言
微调是一种改变大模型表现的低资源手段,但当拿它做知识注入时,很可能遇上“新知识学不好,旧知识也忘了”的尴尬处境,相关研究表明,其原因在于微调新知识容易让模型变得“张口就来”:不基于原有的知识回答问题,或者基于原有的幻觉回答问题
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
https://arxiv.org/pdf/2405.05904
谷歌24年论文
所以,如果我们希望通过微调让大模型学习新知识,需要仔细挑选训练数据,以求在学会新知识的同时原本的通用能力不要下降。
对此,本文提出了一种名为KSOD的LLM知识迭代框架,分为知识识别、知识验证和知识补充三个步骤,本文对此展开介绍
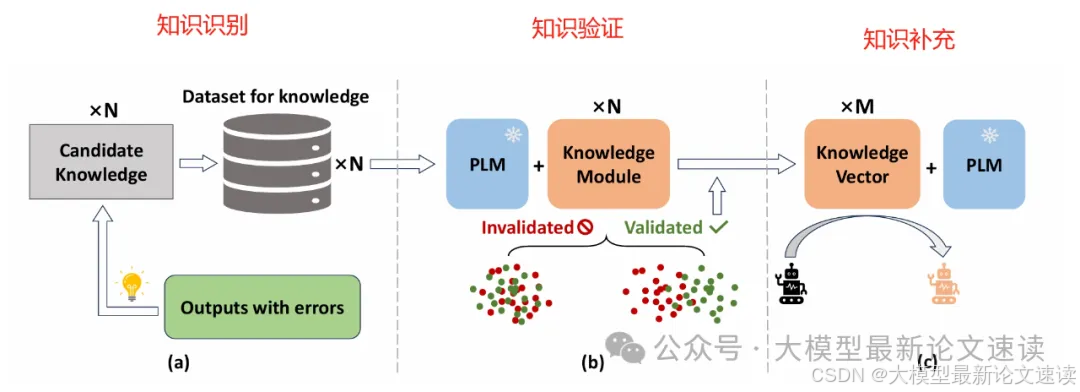
知识识别
对于需要进行知识迭代的LLM,首先收集它所犯的知识性错误样例,并在GPT/DeepSeek等强力大模型的帮助下进行点评、识别所缺少的知识

找到需要加强的知识后,通过手动或自动检索,确定大致包含这些知识的数据集
注:基于知识而非基于任务构造数据,泛化性更强
知识验证
知识识别阶段得到的数据集会有多种,知识验证阶段的目标便是从中挑选出可用的部分
不过在一开始,每个数据集都被用来训练一个lora模块(知识模块)
回顾lora原理:
- 在原始模型的部分参数旁边增加并行旁路
- 独立的参数模块,推理是与原始参数相加
那么存在以下推论:
- 如果lora模块学习的是没用的东西,参数变化会很小,lora模块计算出来向量的信息量就很小(对不同类别的新知识表示更趋同)
- 如果lora模块学习的是有用的东西,参数变化相对更大,lora模块计算出来的向量信息量就更大(对不同类别的新知识表示更泾渭分明)
作者在llama和qwen两个模型上,使用不同类型的数据进行lora训练,结果支持以上观点(本案例是模型缺乏语法类知识)
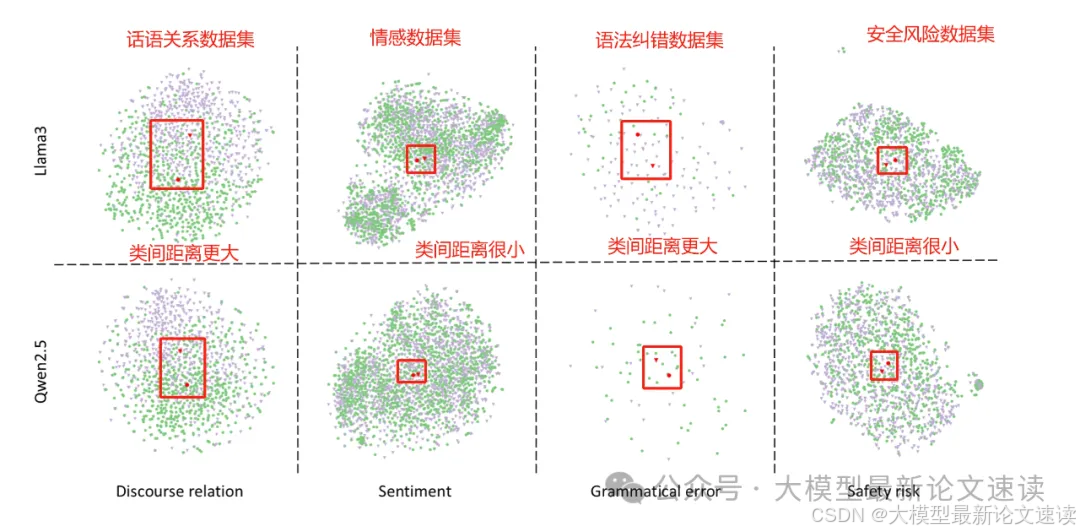
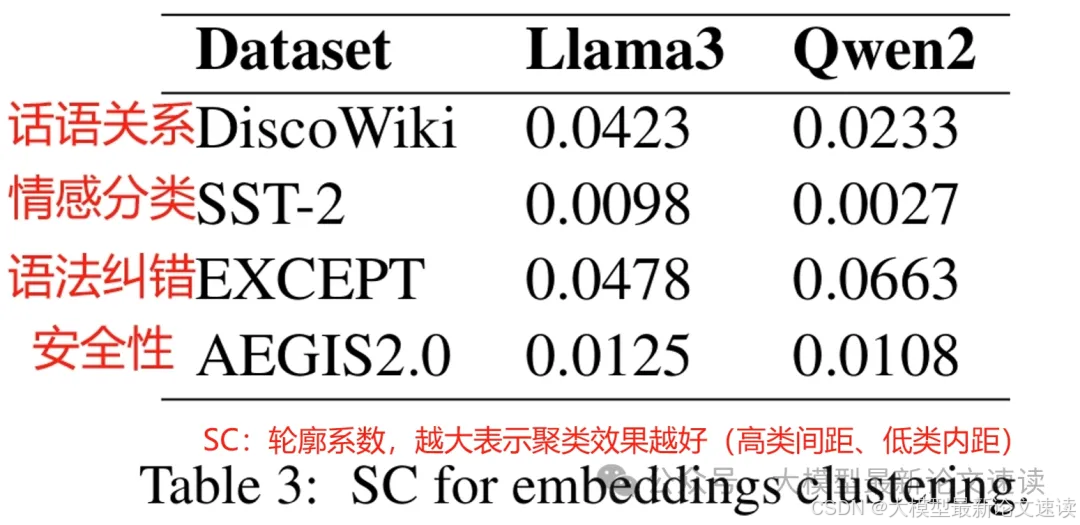
最终,只选择轮廓系数更高的数据集作为知识注入候选
知识补充
这一步很简单,将通过知识验证的lora模块merge到当前模型即可,测试效果如下
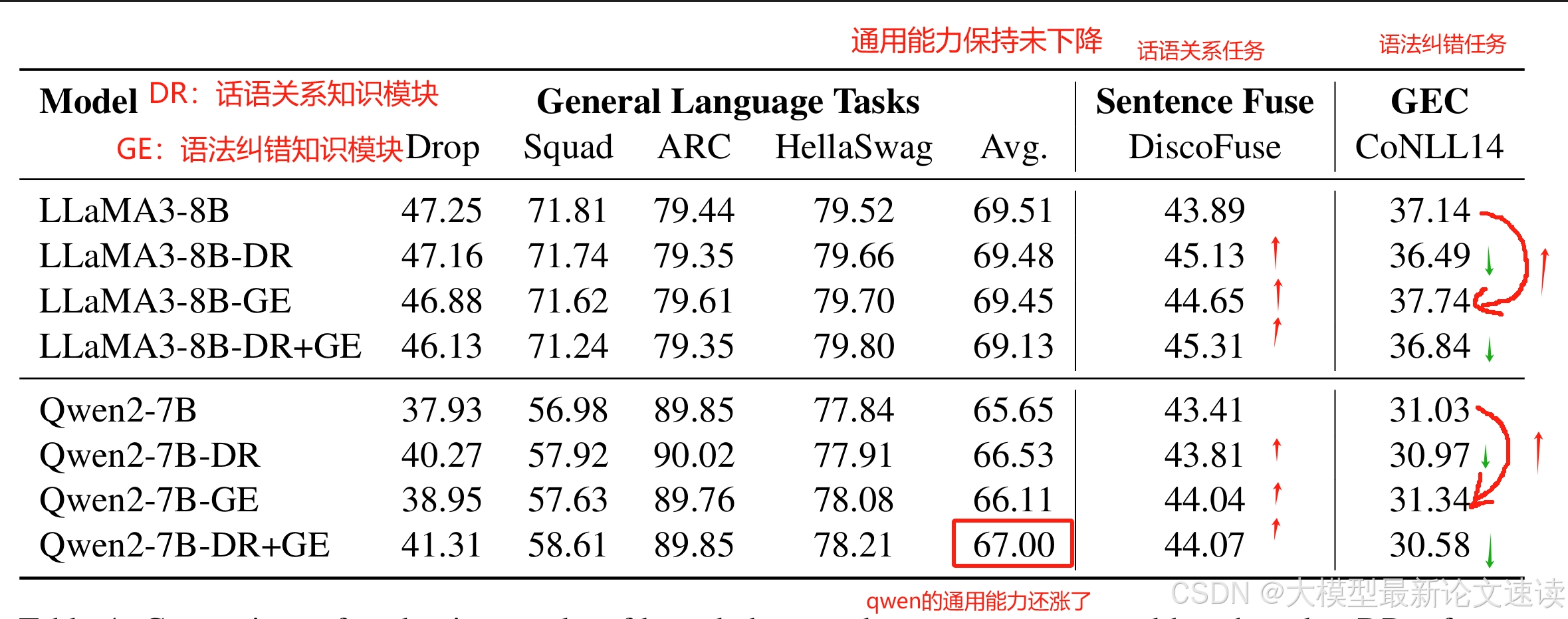
由图可知,经过选择后的知识模块可以提升特定任务的效果,并且维持模型原本的通用能力不变
话语关系和语法纠错都属于语法类知识,但前者的引入会导致语法纠错效果降低,这更说明了新知识的选择需要非常仔细严格,稍不注意就会产生负向效果
总结
本文存在以下不足:
- 学术界实验数据往往具有清晰的边界,能够更容易地找出特定任务的数据集;而在工业场景下,数据往往以业务单元为单位构造,还需要额外的数据治理工作
- 本文所涉及的“知识”都需要有一个类别标签,这样才能在知识验证环节通过类间的聚类特征判断知识的价值,这很难扩展到一些长篇的理论、算法、业务知识上去
本文的主要启发:
- 再次证明通过SFT注入知识的难度,并提供了一种新的数据筛选思路
- 提出了一种新颖的知识价值判断方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









