






Winograd算法是一种快速卷积算法,用于减少卷积运算中的乘法数量,代价是适当增加加法数量。首次将Winograd算法用于神经网络卷积运算的文章为参考文献[1]。
本文将基于该文章和几篇博文,介绍其基本原理。
1.一维卷积 F ( 2 , 3 ) F(2,3) F(2,3)
首先以卷积
F
(
2
,
3
)
F(2,3)
F(2,3)为例介绍Winograd算法如何实现一维卷积。
F
(
2
,
3
)
F(2,3)
F(2,3)表示卷积核大小为
3
×
1
3\times1
3×1,被卷积的向量大小为
2
+
3
−
1
=
4
2+3-1=4
2+3−1=4。将卷积核的权重记为
w
i
w_{i}
wi,则
F
(
2
,
3
)
F(2,3)
F(2,3)的卷积核对应的列向量为
w
=
[
w
0
w
1
w
2
]
=
[
w
0
,
w
1
,
w
2
]
T
.
w=\left[ \begin{array}{c} w_0\\ w_1\\ w_2 \end{array} \right]= \left[ w_0,w_1,w_2 \right]^T.
w=⎣⎡w0w1w2⎦⎤=[w0,w1,w2]T.
同时,记被卷积的向量为
k
=
[
k
0
k
1
k
2
k
3
]
=
=
[
k
0
,
k
1
,
k
2
,
k
3
]
T
.
k=\left[ \begin{array}{c} k_0\\ k_1\\ k_2\\ k_3 \end{array} \right]==\left[ k_0,k_1,k_2,k_3 \right]^T.
k=⎣⎢⎢⎡k0k1k2k3⎦⎥⎥⎤==[k0,k1,k2,k3]T.
一维卷积即卷积核在上述长度为4的被卷积的向量上滑动,分为下列两步。
1.1.第一步
被卷积向量的前3个元素与卷积核卷积,相关元素标红如下
[
k
0
,
k
1
,
k
2
,
k
3
]
T
.
\left[ \red{k_0},\red{k_1},\red{k_2},k_3 \right]^T.
[k0,k1,k2,k3]T.
得到的卷积结果记为
r
0
=
[
k
0
,
k
1
,
k
2
]
[
w
0
w
1
w
2
]
=
k
0
w
0
+
k
1
w
1
+
k
2
w
2
.
r_0=\left[k_0,k_1,k_2\right] \left[ \begin{array}{c} w_0\\ w_1\\ w_2 \end{array} \right]= k_0w_0+k_1w_1+k_2w_2.
r0=[k0,k1,k2]⎣⎡w0w1w2⎦⎤=k0w0+k1w1+k2w2.
1.2.第二步
被卷积向量的后3个元素与卷积核卷积,相关元素标红如下
[
k
0
,
k
1
,
k
2
,
k
3
.
]
T
.
\left[ k_0,\red{k_1},\red{k_2},\red{k_3}. \right]^T.
[k0,k1,k2,k3.]T.
得到的卷积结果记为
r
1
=
[
k
1
,
k
2
,
k
3
]
[
w
0
w
1
w
2
]
=
k
1
w
0
+
k
2
w
1
+
k
3
w
2
.
r_1=\left[k_1,k_2,k_3\right] \left[ \begin{array}{c} w_0\\ w_1\\ w_2 \end{array} \right]= k_1w_0+k_2w_1+k_3w_2.
r1=[k1,k2,k3]⎣⎡w0w1w2⎦⎤=k1w0+k2w1+k3w2.
上述计算过程可以用矩阵向量相乘的形式表示:
[
r
0
r
1
]
=
[
k
0
k
1
k
2
k
1
k
2
k
3
]
[
w
0
w
1
w
2
]
=
[
k
0
w
0
+
k
1
w
1
+
k
2
w
2
k
1
w
0
+
k
2
w
1
+
k
3
w
2
]
.
(1)
\left[ \begin{array}{c} r_0\\ r_1 \end{array} \right]= \left[ \begin{array}{ccc} k_0 &k_1& k_2\\ k_1 &k_2 &k_3 \end{array} \right] \left[ \begin{array}{c} w_0\\ w_1\\ w_2 \end{array} \right]= \left[ \begin{array}{c} k_0w_0+k_1w_1+k_2w_2\\ k_1w_0+k_2w_1+k_3w_2 \end{array} \right]. \tag{1}
[r0r1]=[k0k1k1k2k2k3]⎣⎡w0w1w2⎦⎤=[k0w0+k1w1+k2w2k1w0+k2w1+k3w2].(1)
这就是卷积
F
(
2
,
3
)
F(2,3)
F(2,3)的矩阵表示形式,左边的矩阵大小为
2
×
3
2\times3
2×3,右边的列向量为
3
×
1
3\times1
3×1。实际上,对于一维卷积,均可以表示为类似的形式。即对于卷积
F
(
m
,
r
)
F(m,r)
F(m,r),均可以表示成大小为
m
×
r
m\times r
m×r的矩阵和大小为
r
×
1
r\times1
r×1的列向量的乘积。
对于上述的
F
(
2
,
3
)
F(2,3)
F(2,3),不难发现,需要的乘法数目为
2
×
3
=
6
2\times 3=6
2×3=6,加法数目为4个。Winograd算法通过将某些元素进行合并和复用,可以以增加加法为代价减少乘法数目。Winograd算法将式(1)中的结果改写为下列形式
[
k
0
w
0
+
k
1
w
1
+
k
2
w
2
k
1
w
0
+
k
2
w
1
+
k
3
w
2
]
=
[
m
0
+
m
1
+
m
2
m
1
−
m
2
−
m
3
]
.
\left[ \begin{array}{c} k_0w_0+k_1w_1+k_2w_2\\ k_1w_0+k_2w_1+k_3w_2 \end{array} \right]= \left[ \begin{array}{c} m_0+m_1+m_2\\ m_1-m_2-m_3 \end{array} \right].
[k0w0+k1w1+k2w2k1w0+k2w1+k3w2]=[m0+m1+m2m1−m2−m3].
其中,
m
0
=
(
k
0
−
k
2
)
w
0
m_0=(k_0-k_2)w_0
m0=(k0−k2)w0,
m
1
=
(
k
1
+
k
2
)
(
w
0
+
w
1
+
w
2
)
/
2
m_1=(k_1+k_2)(w_0+w_1+w_2)/2
m1=(k1+k2)(w0+w1+w2)/2,
m
2
=
(
k
2
−
k
1
)
(
w
0
−
w
1
+
w
2
)
/
2
m_2=(k_2-k_1)(w_0-w_1+w_2)/2
m2=(k2−k1)(w0−w1+w2)/2,
m
3
=
(
k
1
−
k
3
)
w
2
m_3=(k_1-k_3)w_2
m3=(k1−k3)w2。
显然,经过上述变换,乘法数目仅为4次,但是加法数目增加到11次(
w
0
+
w
2
w_0+w_2
w0+w2只需要计算一次)。除以2可以忽略,因为他可以通过简单的移位实现。
对于卷积
F
(
m
,
r
)
F(m,r)
F(m,r)而言,被卷积的向量长度为
m
+
r
−
1
m+r-1
m+r−1,需要的乘法数目也是
m
+
r
−
1
m+r-1
m+r−1。
下面我们将对一维卷积
F
(
2
,
3
)
F(2,3)
F(2,3)的Winograd算法用矩阵的形式表示。记下列3个矩阵:
A
T
=
[
1
1
1
0
0
1
−
1
1
]
,
G
=
[
1
0
0
1
/
2
1
/
2
1
/
2
1
/
2
−
1
/
2
1
/
2
0
0
1
]
,
B
T
=
[
1
0
−
1
0
0
1
1
0
0
−
1
1
0
0
1
0
−
1
]
.
\begin{array}{c} A^T= \left[ \begin{array}{cccc} 1 &1 &1 &0\\ 0 &1 &-1 &1 \end{array} \right],\\ G=\left[ \begin{array}{ccc} 1&0&0\\ 1/2&1/2&1/2\\ 1/2&-1/2&1/2\\ 0&0&1 \end{array} \right],\\ B^T=\left[ \begin{array}{cccc} 1&0&-1&0\\ 0&1&1&0\\ 0&-1&1&0\\ 0&1&0&-1 \end{array} \right]. \end{array}
AT=[10111−101],G=⎣⎢⎢⎡11/21/2001/2−1/2001/21/21⎦⎥⎥⎤,BT=⎣⎢⎢⎡100001−11−1110000−1⎦⎥⎥⎤.
则
F
(
2
,
3
)
F(2,3)
F(2,3)的Winograd算法可以表示为
R
=
[
r
0
r
1
]
=
A
T
[
(
G
w
)
⊙
(
B
T
k
)
]
.
(2)
R=\left[ \begin{array}{c} r_0\\ r_1 \end{array} \right]= A^T\left[(Gw)\odot(B^Tk)\right].\tag{2}
R=[r0r1]=AT[(Gw)⊙(BTk)].(2)
其中
⊙
\odot
⊙是矩阵点乘,即矩阵对应元素相乘。
2.二维卷积 F ( 2 × 2 , 3 × 3 ) F(2\times2,3\times3) F(2×2,3×3)
二维卷积的Winograd算法是基于一维Winograd算法的,其难点在于如何通过一维卷积的Winograd公式推导出一个通用的二维卷积Winograd公式。本节部分内容参考了参考文献[2]。
不同于一维卷积是用1维向量卷积核在1维向量上进行卷积,二维卷积是用2维卷积核在2维矩阵上进行卷积。对于二维卷积
F
(
m
×
n
,
r
×
s
)
F(m\times n,r\times s)
F(m×n,r×s),是用大小为
s
×
r
s\times r
s×r的卷积核在大小为
m
+
s
−
1
×
m
+
r
−
1
m+s-1\times m+r-1
m+s−1×m+r−1的矩阵上进行卷积。例如
F
(
2
×
2
,
3
×
3
)
F(2\times2,3\times3)
F(2×2,3×3)就是用大小为
3
×
3
3\times3
3×3的卷积核
w
=
[
w
0
,
0
w
0
,
1
w
0
,
2
w
1
,
0
w
1
,
1
w
1
,
2
w
2
,
0
w
2
,
1
w
2
,
2
]
=
[
w
0
w
1
w
2
w
3
w
4
w
5
w
6
w
7
w
8
]
,
w=\left[ \begin{array}{ccc} w_{0,0}&w_{0,1}&w_{0,2}\\ w_{1,0}&w_{1,1}&w_{1,2}\\ w_{2,0}&w_{2,1}&w_{2,2} \end{array} \right]= \left[ \begin{array}{ccc} w_{0}&w_{1}&w_{2}\\ w_{3}&w_{4}&w_{5}\\ w_{6}&w_{7}&w_{8} \end{array} \right],
w=⎣⎡w0,0w1,0w2,0w0,1w1,1w2,1w0,2w1,2w2,2⎦⎤=⎣⎡w0w3w6w1w4w7w2w5w8⎦⎤,
在大小为
4
×
4
4\times 4
4×4的矩阵(因为2+3-1=4)
k
=
[
k
0
,
0
k
0
,
1
k
0
,
2
k
0
,
3
k
1
,
0
k
1
,
1
k
1
,
2
k
1
,
3
k
2
,
0
k
2
,
1
k
2
,
2
k
2
,
3
k
3
,
0
k
3
,
1
k
3
,
2
k
3
,
3
]
=
[
k
0
k
1
k
2
k
3
k
4
k
5
k
6
k
7
k
8
k
9
k
10
k
11
k
12
k
13
k
14
k
15
]
k=\left[ \begin{array}{cccc} k_{0,0}&k_{0,1}&k_{0,2}&k_{0,3}\\ k_{1,0}&k_{1,1}&k_{1,2}&k_{1,3}\\ k_{2,0}&k_{2,1}&k_{2,2}&k_{2,3}\\ k_{3,0}&k_{3,1}&k_{3,2}&k_{3,3} \end{array} \right]=\left[ \begin{array}{cccc} k_{0}&k_{1}&k_{2}&k_{3}\\ k_{4}&k_{5}&k_{6}&k_{7}\\ k_{8}&k_{9}&k_{10}&k_{11}\\ k_{12}&k_{13}&k_{14}&k_{15} \end{array} \right]
k=⎣⎢⎢⎡k0,0k1,0k2,0k3,0k0,1k1,1k2,1k3,1k0,2k1,2k2,2k3,2k0,3k1,3k2,3k3,3⎦⎥⎥⎤=⎣⎢⎢⎡k0k4k8k12k1k5k9k13k2k6k10k14k3k7k11k15⎦⎥⎥⎤
上进行卷积。下图(来自参考文献[2])形象地表述了该卷积操作。
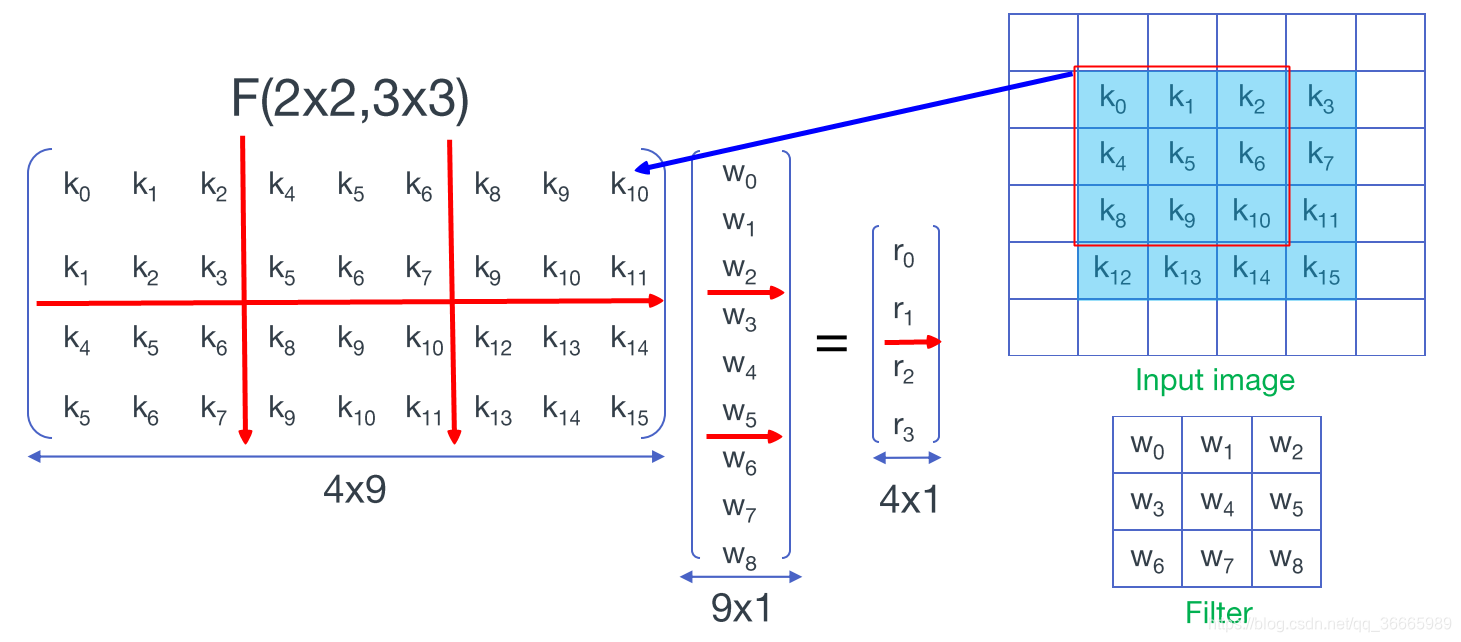
进一步,将矩阵进行分块。(图片来自于参考文献[2])
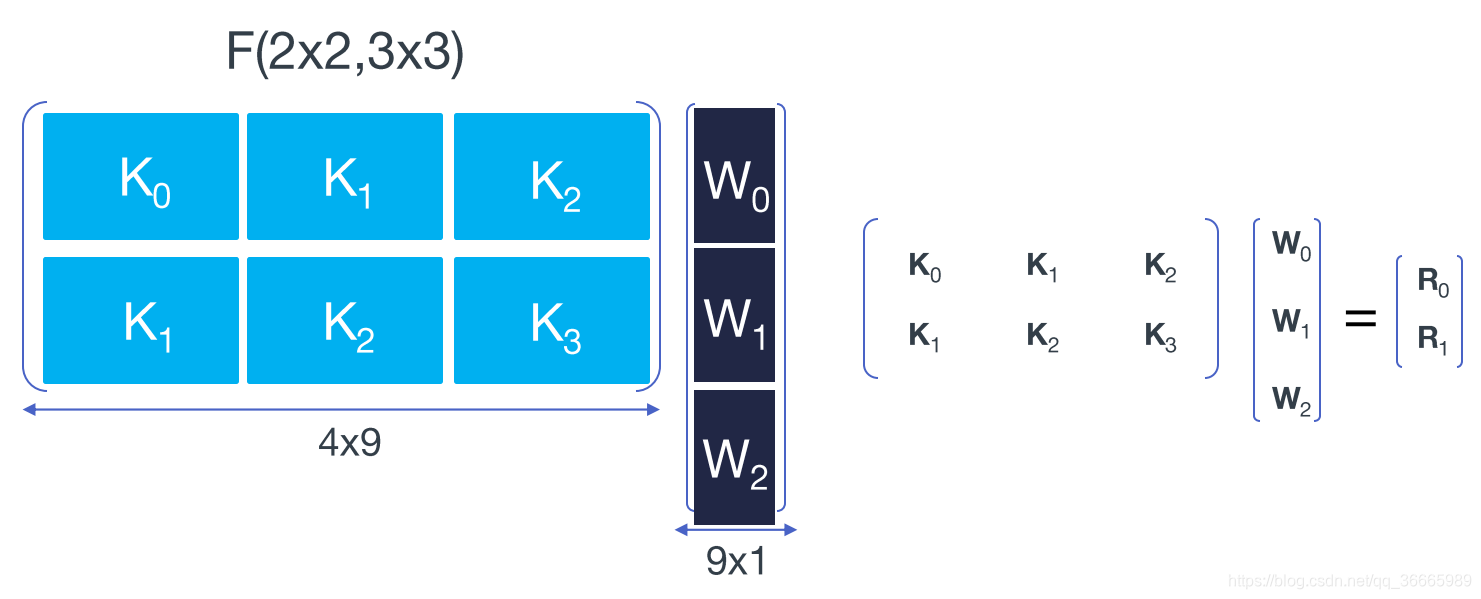 为了更加形象化,将上图中的式子重新记为
为了更加形象化,将上图中的式子重新记为
[
K
0
K
4
K
8
K
4
K
8
K
12
]
[
W
0
W
3
W
6
]
=
[
R
0
R
2
]
.
\left[ \begin{array}{ccc} K_0&K_4&K_8\\ K_4&K_8&K_{12} \end{array} \right] \left[ \begin{array}{c} W_0\\ W_3\\ W_6 \end{array} \right]= \left[ \begin{array}{c} R_0\\ R_2 \end{array} \right].
[K0K4K4K8K8K12]⎣⎡W0W3W6⎦⎤=[R0R2].
其中
K
K
K、
W
W
W和
R
R
R的下标用其包含的第一个
k
k
k、
w
w
w或者
r
r
r的下标来表示。进一步,有
[
r
0
r
1
r
2
r
3
]
=
[
R
0
R
2
]
=
[
K
0
W
0
+
K
4
W
3
+
K
8
W
6
K
4
W
0
+
K
8
W
3
+
K
12
W
6
]
.
\left[ \begin{array}{c} r_0\\ r_1\\ r_2\\ r_3 \end{array} \right]= \left[ \begin{array}{c} R_0\\ R_2 \end{array} \right]= \left[ \begin{array}{c} K_0W_0+K_4W_3+K_8W_6\\ K_4W_0+K_8W_3+K_{12}W_6 \end{array} \right].
⎣⎢⎢⎡r0r1r2r3⎦⎥⎥⎤=[R0R2]=[K0W0+K4W3+K8W6K4W0+K8W3+K12W6].
为得到
[
r
0
r
1
r
2
r
3
]
\left[\begin{array}{cc}r_0&r_1\\r_2&r_3\end{array}\right]
[r0r2r1r3],进一步改写为
[
r
0
r
1
r
2
r
3
]
=
[
R
0
T
R
2
T
]
=
[
(
K
0
W
0
+
K
4
W
3
+
K
8
W
6
)
T
(
K
4
W
0
+
K
8
W
3
+
K
12
W
6
)
T
]
=
[
(
K
0
W
0
)
T
+
(
K
4
W
3
)
T
+
(
K
8
W
6
)
T
(
K
4
W
0
)
T
+
(
K
8
W
3
)
T
+
(
K
12
W
6
)
T
]
.
\left[\begin{array}{cc}r_0&r_1\\r_2&r_3\end{array}\right]= \left[ \begin{array}{c} R^T_0\\ R^T_2 \end{array} \right]= \left[ \begin{array}{c} (K_0W_0+K_4W_3+K_8W_6)^T\\ (K_4W_0+K_8W_3+K_{12}W_6)^T \end{array} \right]= \left[ \begin{array}{c} (K_0W_0)^T+(K_4W_3)^T+(K_8W_6)^T\\ (K_4W_0)^T+(K_8W_3)^T+(K_{12}W_6)^T \end{array} \right].
[r0r2r1r3]=[R0TR2T]=[(K0W0+K4W3+K8W6)T(K4W0+K8W3+K12W6)T]=[(K0W0)T+(K4W3)T+(K8W6)T(K4W0)T+(K8W3)T+(K12W6)T].
对于
K
i
W
j
K_iW_j
KiWj而言,进行的是1维卷积
F
(
2
,
3
)
F(2,3)
F(2,3)。例如
K
8
W
3
K_8W_3
K8W3表示的是
K
8
W
3
=
[
k
8
k
9
k
10
k
9
k
10
k
11
]
[
w
3
w
4
w
5
]
.
K_8W_3= \left[ \begin{array}{ccc} k_8&k_9&k_{10}\\ k_9&k_{10}&k_{11} \end{array} \right] \left[ \begin{array}{c} w_3\\ w_4\\ w_5 \end{array} \right].
K8W3=[k8k9k9k10k10k11]⎣⎡w3w4w5⎦⎤.
那么根据1维卷积的式(2),可以表示为
K
8
W
3
=
A
T
[
(
G
[
w
3
w
4
w
5
]
)
⊙
(
B
T
[
k
8
k
9
k
10
k
11
]
)
]
.
K_8W_3=A^T \left[ (G \left[ \begin{array}{c} w_3\\w_4\\w_5 \end{array} \right]) \odot (B^T \left[ \begin{array}{c} k_8\\k_9\\k_{10}\\k_{11} \end{array} \right] ) \right].
K8W3=AT⎣⎢⎢⎡(G⎣⎡w3w4w5⎦⎤)⊙(BT⎣⎢⎢⎡k8k9k10k11⎦⎥⎥⎤)⎦⎥⎥⎤.
转置后有
(
K
8
W
3
)
T
=
[
(
[
w
3
,
w
4
,
w
5
]
G
T
)
⊙
(
[
k
8
,
k
9
,
k
10
,
k
11
]
B
)
]
A
.
(K_8W_3)^T= \left[ ( \left[ w_3,w_4,w_5 \right]G^T) \odot ( \left[ k_8,k_9,k_{10},k_{11} \right]B ) \right]A.
(K8W3)T=[([w3,w4,w5]GT)⊙([k8,k9,k10,k11]B)]A.
注意到
[
w
3
,
w
4
,
w
5
]
G
T
\left[w_3,w_4,w_5\right]G^T
[w3,w4,w5]GT是一个
1
×
4
1\times4
1×4的行向量,
[
k
8
,
k
9
,
k
10
,
k
11
]
B
\left[k_8,k_9,k_{10},k_{11}\right]B
[k8,k9,k10,k11]B也是是一个
1
×
4
1\times4
1×4的行向量。为了符号简单,我们记
μ
3
=
[
w
3
,
w
4
,
w
5
]
G
T
\mu_3=\left[w_3,w_4,w_5\right]G^T
μ3=[w3,w4,w5]GT,
v
8
=
[
k
8
,
k
9
,
k
10
,
k
11
]
B
v_8=\left[k_8,k_9,k_{10},k_{11}\right]B
v8=[k8,k9,k10,k11]B。因此有
[
r
0
r
1
r
2
r
3
]
=
[
(
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
)
A
(
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
)
A
]
=
[
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
]
A
\left[\begin{array}{cc}r_0&r_1\\r_2&r_3\end{array}\right]= \left[ \begin{array}{c} (\mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8)A\\ (\mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12})A \end{array} \right]= \left[ \begin{array}{c} \mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8\\ \mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12} \end{array} \right]A
[r0r2r1r3]=[(μ0⊙v0+μ3⊙v4+μ6⊙v8)A(μ0⊙v4+μ3⊙v8+μ6⊙v12)A]=[μ0⊙v0+μ3⊙v4+μ6⊙v8μ0⊙v4+μ3⊙v8+μ6⊙v12]A
上式中
[
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
]
\left[ \begin{array}{c} \mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8\\ \mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12} \end{array} \right]
[μ0⊙v0+μ3⊙v4+μ6⊙v8μ0⊙v4+μ3⊙v8+μ6⊙v12]是一个大小为
2
×
4
2\times4
2×4的矩阵。
经过观察发现,
[
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
]
\left[ \begin{array}{c} \mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8\\ \mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12} \end{array} \right]
[μ0⊙v0+μ3⊙v4+μ6⊙v8μ0⊙v4+μ3⊙v8+μ6⊙v12]与1维卷积式(1)有些相似,他好像可以看做一次卷积核为
μ
=
[
μ
0
,
μ
3
,
μ
6
]
T
\mu=\left[\mu_0,\mu_3,\mu_6\right]^T
μ=[μ0,μ3,μ6]T,被卷积向量为
v
=
[
v
0
,
v
4
,
v
8
,
v
12
]
T
v=\left[v_0,v_4,v_8,v_{12}\right]^T
v=[v0,v4,v8,v12]T的1维卷积。但可惜的是这里是点乘
⊙
\odot
⊙,并且
μ
i
\mu_i
μi和
v
j
v_j
vj的顺序好像反了。首先我们解决顺序的问题,因为改变点乘元素的顺序不影响结果,所以有
[
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
]
=
[
v
0
⊙
μ
0
+
v
4
⊙
μ
3
+
v
8
⊙
μ
6
v
4
⊙
μ
0
+
v
8
⊙
μ
3
+
v
12
⊙
μ
6
]
.
\left[ \begin{array}{c} \mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8\\ \mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12} \end{array} \right]= \left[ \begin{array}{c} v_0\odot \mu_0+v_4\odot \mu_3+v_8\odot \mu_6\\ v_4\odot \mu_0+ v_8\odot \mu_3+v_{12}\odot \mu_6 \end{array} \right].
[μ0⊙v0+μ3⊙v4+μ6⊙v8μ0⊙v4+μ3⊙v8+μ6⊙v12]=[v0⊙μ0+v4⊙μ3+v8⊙μ6v4⊙μ0+v8⊙μ3+v12⊙μ6].
再次强调一下矩阵的大小,
[
v
0
⊙
μ
0
+
v
4
⊙
μ
3
+
v
8
⊙
μ
6
v
4
⊙
μ
0
+
v
8
⊙
μ
3
+
v
12
⊙
μ
6
]
\left[ \begin{array}{c} v_0\odot \mu_0+v_4\odot \mu_3+v_8\odot \mu_6\\ v_4\odot \mu_0+ v_8\odot \mu_3+v_{12}\odot \mu_6 \end{array} \right]
[v0⊙μ0+v4⊙μ3+v8⊙μ6v4⊙μ0+v8⊙μ3+v12⊙μ6]是一个
2
×
4
2\times 4
2×4的矩阵,
v
i
⊙
μ
j
v_i\odot \mu_j
vi⊙μj是一个大小为
1
×
4
1\times 4
1×4的行向量,
v
i
v_i
vi和
μ
j
\mu_j
μj均是大小为
1
×
4
1\times 4
1×4的行向量。
目前,点乘元素顺序的问题解决了,接下来将点乘替换成元素相乘,以运用我们1维Winograd卷积公式。记
v
i
=
[
v
i
,
0
,
v
i
,
1
,
v
i
,
2
,
v
i
,
3
]
,
i
=
0
,
4
,
8
,
12
;
μ
j
=
[
μ
j
,
0
,
μ
j
,
1
,
μ
j
,
2
,
μ
j
,
3
]
,
j
=
0
,
3
,
6.
v_i=\left[v_{i,0}, v_{i,1}, v_{i,2}, v_{i,3}\right],i=0,4,8,12;\\ \mu_j=\left[\mu_{j,0}, \mu_{j,1}, \mu_{j,2}, \mu_{j,3}\right],j=0,3,6.
vi=[vi,0,vi,1,vi,2,vi,3],i=0,4,8,12;μj=[μj,0,μj,1,μj,2,μj,3],j=0,3,6.
于是
[
v
0
⊙
μ
0
+
v
4
⊙
μ
3
+
v
8
⊙
μ
6
v
4
⊙
μ
0
+
v
8
⊙
μ
3
+
v
12
⊙
μ
6
]
\left[ \begin{array}{c} v_0\odot \mu_0+v_4\odot \mu_3+v_8\odot \mu_6\\ v_4\odot \mu_0+ v_8\odot \mu_3+v_{12}\odot \mu_6 \end{array} \right]
[v0⊙μ0+v4⊙μ3+v8⊙μ6v4⊙μ0+v8⊙μ3+v12⊙μ6]可以表示成
[
v
0
,
0
μ
0
,
0
+
v
4
,
0
μ
3
,
0
+
v
8
,
0
μ
6
,
0
v
0
,
1
μ
0
,
1
+
v
4
,
1
μ
3
,
1
+
v
8
,
1
μ
6
,
1
v
0
,
2
μ
0
,
2
+
v
4
,
2
μ
3
,
2
+
v
8
,
2
μ
6
,
2
v
0
,
3
μ
0
,
3
+
v
4
,
3
μ
3
,
3
+
v
8
,
3
μ
6
,
3
v
4
,
0
μ
0
,
0
+
v
8
,
0
μ
3
,
0
+
v
12
,
0
μ
6
,
0
v
4
,
1
μ
0
,
1
+
v
8
,
1
μ
3
,
1
+
v
12
,
1
μ
6
,
1
v
4
,
2
μ
0
,
2
+
v
8
,
2
μ
3
,
2
+
v
12
,
2
μ
6
,
2
v
4
,
3
μ
0
,
3
+
v
8
,
3
μ
3
,
3
+
v
12
,
3
μ
6
,
3
]
.
\left[ \begin{array}{cccc} v_{0,0}\mu_{0,0}+v_{4,0}\mu_{3,0}+v_{8,0}\mu_{6,0} &v_{0,1}\mu_{0,1}+v_{4,1}\mu_{3,1}+v_{8,1}\mu_{6,1} &v_{0,2}\mu_{0,2}+v_{4,2}\mu_{3,2}+v_{8,2}\mu_{6,2} &v_{0,3}\mu_{0,3}+v_{4,3}\mu_{3,3}+v_{8,3}\mu_{6,3} \\ v_{4,0}\mu_{0,0}+ v_{8,0}\mu_{3,0}+v_{12,0}\mu_{6,0}&v_{4,1}\mu_{0,1}+ v_{8,1}\mu_{3,1}+v_{12,1}\mu_{6,1}&v_{4,2}\mu_{0,2}+ v_{8,2}\mu_{3,2}+v_{12,2}\mu_{6,2}&v_{4,3}\mu_{0,3}+ v_{8,3}\mu_{3,3}+v_{12,3}\mu_{6,3} \end{array} \right].
[v0,0μ0,0+v4,0μ3,0+v8,0μ6,0v4,0μ0,0+v8,0μ3,0+v12,0μ6,0v0,1μ0,1+v4,1μ3,1+v8,1μ6,1v4,1μ0,1+v8,1μ3,1+v12,1μ6,1v0,2μ0,2+v4,2μ3,2+v8,2μ6,2v4,2μ0,2+v8,2μ3,2+v12,2μ6,2v0,3μ0,3+v4,3μ3,3+v8,3μ6,3v4,3μ0,3+v8,3μ3,3+v12,3μ6,3].
至此,上述矩阵的每一列均可以看做(1)的形式,于是对每一列均采用1维Winograd算法,可以得到
[
v
0
⊙
μ
0
+
v
4
⊙
μ
3
+
v
8
⊙
μ
6
v
4
⊙
μ
0
+
v
8
⊙
μ
3
+
v
12
⊙
μ
6
]
=
A
T
[
(
G
[
μ
0
,
0
μ
3
,
0
μ
6
,
0
]
)
⊙
(
B
T
[
v
0
,
0
v
4
,
0
v
8
,
0
v
12
,
0
]
)
,
(
G
[
μ
0
,
1
μ
3
,
1
μ
6
,
1
]
)
⊙
(
B
T
[
v
0
,
1
v
4
,
1
v
8
,
1
v
12
,
1
]
)
,
(
G
[
μ
0
,
2
μ
3
,
2
μ
6
,
2
]
)
⊙
(
B
T
[
v
0
,
2
v
4
,
2
v
8
,
2
v
12
,
2
]
)
,
(
G
[
μ
0
,
3
μ
3
,
3
μ
6
,
3
]
)
⊙
(
B
T
[
v
0
,
3
v
4
,
3
v
8
,
3
v
12
,
3
]
)
]
=
A
T
[
(
G
[
μ
0
,
0
μ
3
,
0
μ
6
,
0
]
,
G
[
μ
0
,
1
μ
3
,
1
μ
6
,
1
]
,
G
[
μ
0
,
2
μ
3
,
2
μ
6
,
2
]
,
G
[
μ
0
,
3
μ
3
,
3
μ
6
,
3
]
)
⊙
(
B
T
[
v
0
,
0
v
4
,
0
v
8
,
0
v
12
,
0
]
,
B
T
[
v
0
,
1
v
4
,
1
v
8
,
1
v
12
,
1
]
,
B
T
[
v
0
,
2
v
4
,
2
v
8
,
2
v
12
,
2
]
,
B
T
[
v
0
,
3
v
4
,
3
v
8
,
3
v
12
,
3
]
)
]
=
A
T
[
(
G
[
μ
0
,
0
μ
0
,
1
μ
0
,
2
μ
0
,
3
μ
3
,
0
μ
3
,
1
μ
3
,
2
μ
3
,
3
μ
6
,
0
μ
6
,
1
μ
6
,
2
μ
6
,
3
]
)
⊙
(
B
T
[
v
0
,
0
v
0
,
1
v
0
,
2
v
0
,
3
v
4
,
0
v
4
,
1
v
4
,
2
v
4
,
3
v
8
,
0
v
8
,
1
v
8
,
2
v
8
,
3
v
12
,
0
v
12
,
1
v
12
,
2
v
12
,
3
]
)
]
.
(3)
\left[ \begin{array}{c} v_0\odot \mu_0+v_4\odot \mu_3+v_8\odot \mu_6\\ v_4\odot \mu_0+ v_8\odot \mu_3+v_{12}\odot \mu_6 \end{array} \right]\\ =A^T\left[ (G\left[\begin{array}{c}\mu_{0,0}\\ \mu_{3,0}\\ \mu_{6,0}\end{array}\right])\odot(B^T\left[\begin{array}{c}v_{0,0}\\ v_{4,0}\\ v_{8,0}\\ v_{12,0}\end{array}\right]), (G\left[\begin{array}{c}\mu_{0,1}\\ \mu_{3,1}\\ \mu_{6,1}\end{array}\right])\odot(B^T\left[\begin{array}{c}v_{0,1}\\ v_{4,1}\\ v_{8,1}\\ v_{12,1}\end{array}\right]), (G\left[\begin{array}{c}\mu_{0,2}\\ \mu_{3,2}\\ \mu_{6,2}\end{array}\right])\odot(B^T\left[\begin{array}{c}v_{0,2}\\ v_{4,2}\\ v_{8,2}\\ v_{12,2}\end{array}\right]), (G\left[\begin{array}{c}\mu_{0,3}\\ \mu_{3,3}\\ \mu_{6,3}\end{array}\right])\odot(B^T\left[\begin{array}{c}v_{0,3}\\ v_{4,3}\\ v_{8,3}\\ v_{12,3}\end{array}\right]) \right]\\ =A^T\left[ (G\left[\begin{array}{c}\mu_{0,0}\\ \mu_{3,0}\\ \mu_{6,0}\end{array}\right],G\left[\begin{array}{c}\mu_{0,1}\\ \mu_{3,1}\\ \mu_{6,1}\end{array}\right],G\left[\begin{array}{c}\mu_{0,2}\\ \mu_{3,2}\\ \mu_{6,2}\end{array}\right],G\left[\begin{array}{c}\mu_{0,3}\\ \mu_{3,3}\\ \mu_{6,3}\end{array}\right])\odot(B^T\left[\begin{array}{c}v_{0,0}\\ v_{4,0}\\ v_{8,0}\\ v_{12,0}\end{array}\right],B^T\left[\begin{array}{c}v_{0,1}\\ v_{4,1}\\ v_{8,1}\\ v_{12,1}\end{array}\right],B^T\left[\begin{array}{c}v_{0,2}\\ v_{4,2}\\ v_{8,2}\\ v_{12,2}\end{array}\right],B^T\left[\begin{array}{c}v_{0,3}\\ v_{4,3}\\ v_{8,3}\\ v_{12,3}\end{array}\right]) \right]\\ =A^T\left[ (G\left[ \begin{array}{cccc} \mu_{0,0}&\mu_{0,1}&\mu_{0,2}&\mu_{0,3}\\ \mu_{3,0}&\mu_{3,1}&\mu_{3,2}&\mu_{3,3}\\ \mu_{6,0}&\mu_{6,1}&\mu_{6,2}&\mu_{6,3} \end{array} \right])\odot(B^T\left[ \begin{array}{cccc} v_{0,0}&v_{0,1}&v_{0,2}&v_{0,3}\\ v_{4,0}&v_{4,1}&v_{4,2}&v_{4,3}\\ v_{8,0}&v_{8,1}&v_{8,2}&v_{8,3}\\ v_{12,0}&v_{12,1}&v_{12,2}&v_{12,3} \end{array} \right]) \right].\tag{3}
[v0⊙μ0+v4⊙μ3+v8⊙μ6v4⊙μ0+v8⊙μ3+v12⊙μ6]=AT⎣⎢⎢⎡(G⎣⎡μ0,0μ3,0μ6,0⎦⎤)⊙(BT⎣⎢⎢⎡v0,0v4,0v8,0v12,0⎦⎥⎥⎤),(G⎣⎡μ0,1μ3,1μ6,1⎦⎤)⊙(BT⎣⎢⎢⎡v0,1v4,1v8,1v12,1⎦⎥⎥⎤),(G⎣⎡μ0,2μ3,2μ6,2⎦⎤)⊙(BT⎣⎢⎢⎡v0,2v4,2v8,2v12,2⎦⎥⎥⎤),(G⎣⎡μ0,3μ3,3μ6,3⎦⎤)⊙(BT⎣⎢⎢⎡v0,3v4,3v8,3v12,3⎦⎥⎥⎤)⎦⎥⎥⎤=AT⎣⎢⎢⎡(G⎣⎡μ0,0μ3,0μ6,0⎦⎤,G⎣⎡μ0,1μ3,1μ6,1⎦⎤,G⎣⎡μ0,2μ3,2μ6,2⎦⎤,G⎣⎡μ0,3μ3,3μ6,3⎦⎤)⊙(BT⎣⎢⎢⎡v0,0v4,0v8,0v12,0⎦⎥⎥⎤,BT⎣⎢⎢⎡v0,1v4,1v8,1v12,1⎦⎥⎥⎤,BT⎣⎢⎢⎡v0,2v4,2v8,2v12,2⎦⎥⎥⎤,BT⎣⎢⎢⎡v0,3v4,3v8,3v12,3⎦⎥⎥⎤)⎦⎥⎥⎤=AT⎣⎢⎢⎡(G⎣⎡μ0,0μ3,0μ6,0μ0,1μ3,1μ6,1μ0,2μ3,2μ6,2μ0,3μ3,3μ6,3⎦⎤)⊙(BT⎣⎢⎢⎡v0,0v4,0v8,0v12,0v0,1v4,1v8,1v12,1v0,2v4,2v8,2v12,2v0,3v4,3v8,3v12,3⎦⎥⎥⎤)⎦⎥⎥⎤.(3)
为了更好观察上式,这里将
μ
\mu
μ和
v
v
v所表示的矩阵重写一遍。
[
μ
0
μ
3
μ
6
]
=
[
μ
0
,
0
μ
0
,
1
μ
0
,
2
μ
0
,
3
μ
3
,
0
μ
3
,
1
μ
3
,
2
μ
3
,
3
μ
6
,
0
μ
6
,
1
μ
6
,
2
μ
6
,
3
]
=
[
w
0
w
1
w
2
w
3
w
4
w
5
w
6
w
7
w
8
]
G
T
=
w
G
T
;
[
v
0
v
4
v
8
v
12
]
=
[
v
0
,
0
v
0
,
1
v
0
,
2
v
0
,
3
v
4
,
0
v
4
,
1
v
4
,
2
v
4
,
3
v
8
,
0
v
8
,
1
v
8
,
2
v
8
,
3
v
12
,
0
v
12
,
1
v
12
,
2
v
12
,
3
]
=
[
k
0
k
1
k
2
k
3
k
4
k
5
k
6
k
7
k
8
k
9
k
10
k
11
k
12
k
13
k
14
k
15
]
B
=
k
B
.
\left[ \begin{array}{c} \mu_0\\ \mu_3\\ \mu_6 \end{array} \right]= \left[ \begin{array}{cccc} \mu_{0,0}&\mu_{0,1}&\mu_{0,2}&\mu_{0,3}\\ \mu_{3,0}&\mu_{3,1}&\mu_{3,2}&\mu_{3,3}\\ \mu_{6,0}&\mu_{6,1}&\mu_{6,2}&\mu_{6,3} \end{array} \right]= \left[ \begin{array}{ccc} w_0&w_1&w_2\\ w_3&w_4&w_5\\ w_6&w_7&w_8 \end{array} \right]G^T=wG^T;\\ \left[ \begin{array}{c} v_0\\ v_4\\ v_8\\ v_{12} \end{array} \right]= \left[ \begin{array}{cccc} v_{0,0}&v_{0,1}&v_{0,2}&v_{0,3}\\ v_{4,0}&v_{4,1}&v_{4,2}&v_{4,3}\\ v_{8,0}&v_{8,1}&v_{8,2}&v_{8,3}\\ v_{12,0}&v_{12,1}&v_{12,2}&v_{12,3} \end{array} \right]= \left[ \begin{array}{cccc} k_0&k_1&k_2&k_3\\ k_4&k_5&k_6&k_7\\ k_8&k_9&k_{10}&k_{11}\\ k_{12}&k_{13}&k_{14}&k_{15} \end{array} \right]B=kB.
⎣⎡μ0μ3μ6⎦⎤=⎣⎡μ0,0μ3,0μ6,0μ0,1μ3,1μ6,1μ0,2μ3,2μ6,2μ0,3μ3,3μ6,3⎦⎤=⎣⎡w0w3w6w1w4w7w2w5w8⎦⎤GT=wGT;⎣⎢⎢⎡v0v4v8v12⎦⎥⎥⎤=⎣⎢⎢⎡v0,0v4,0v8,0v12,0v0,1v4,1v8,1v12,1v0,2v4,2v8,2v12,2v0,3v4,3v8,3v12,3⎦⎥⎥⎤=⎣⎢⎢⎡k0k4k8k12k1k5k9k13k2k6k10k14k3k7k11k15⎦⎥⎥⎤B=kB.
同时考虑(3),有
[
r
0
r
1
r
2
r
3
]
=
[
μ
0
⊙
v
0
+
μ
3
⊙
v
4
+
μ
6
⊙
v
8
μ
0
⊙
v
4
+
μ
3
⊙
v
8
+
μ
6
⊙
v
12
]
A
=
A
T
[
(
G
[
μ
0
,
0
μ
0
,
1
μ
0
,
2
μ
0
,
3
μ
3
,
0
μ
3
,
1
μ
3
,
2
μ
3
,
3
μ
6
,
0
μ
6
,
1
μ
6
,
2
μ
6
,
3
]
)
⊙
(
B
T
[
v
0
,
0
v
0
,
1
v
0
,
2
v
0
,
3
v
4
,
0
v
4
,
1
v
4
,
2
v
4
,
3
v
8
,
0
v
8
,
1
v
8
,
2
v
8
,
3
v
12
,
0
v
12
,
1
v
12
,
2
v
12
,
3
]
)
]
A
=
A
T
[
(
G
w
G
T
)
⊙
(
B
T
k
B
)
]
A
.
\begin{aligned} \left[\begin{array}{cc}r_0&r_1\\r_2&r_3\end{array}\right] &=\left[ \begin{array}{c} \mu_0\odot v_0+\mu_3\odot v_4+\mu_6\odot v_8\\ \mu_0\odot v_4+\mu_3\odot v_8+\mu_6\odot v_{12} \end{array} \right]A\\ &=A^T\left[ (G\left[ \begin{array}{cccc} \mu_{0,0}&\mu_{0,1}&\mu_{0,2}&\mu_{0,3}\\ \mu_{3,0}&\mu_{3,1}&\mu_{3,2}&\mu_{3,3}\\ \mu_{6,0}&\mu_{6,1}&\mu_{6,2}&\mu_{6,3} \end{array} \right])\odot(B^T\left[ \begin{array}{cccc} v_{0,0}&v_{0,1}&v_{0,2}&v_{0,3}\\ v_{4,0}&v_{4,1}&v_{4,2}&v_{4,3}\\ v_{8,0}&v_{8,1}&v_{8,2}&v_{8,3}\\ v_{12,0}&v_{12,1}&v_{12,2}&v_{12,3} \end{array} \right]) \right]A\\ &=A^T\left[ (GwG^T)\odot(B^TkB) \right]A. \end{aligned}
[r0r2r1r3]=[μ0⊙v0+μ3⊙v4+μ6⊙v8μ0⊙v4+μ3⊙v8+μ6⊙v12]A=AT⎣⎢⎢⎡(G⎣⎡μ0,0μ3,0μ6,0μ0,1μ3,1μ6,1μ0,2μ3,2μ6,2μ0,3μ3,3μ6,3⎦⎤)⊙(BT⎣⎢⎢⎡v0,0v4,0v8,0v12,0v0,1v4,1v8,1v12,1v0,2v4,2v8,2v12,2v0,3v4,3v8,3v12,3⎦⎥⎥⎤)⎦⎥⎥⎤A=AT[(GwGT)⊙(BTkB)]A.
上式是2维卷积的Winograd算法。注意到
(
G
w
G
T
)
(GwG^T)
(GwGT)和
(
B
T
k
B
)
(B^TkB)
(BTkB)均是
4
×
4
4\times4
4×4的矩阵,因此他们的点乘需要16次乘法,而常规的卷积运算需要
3
×
3
×
2
×
2
=
36
3\times3\times2\times2=36
3×3×2×2=36次乘法。
3. 1维卷积 F ( m , r ) F(m,r) F(m,r)和2维卷积 F ( m × n , r × s ) F(m\times n,r\times s) F(m×n,r×s)在Winograd算法下需要的乘法数目总结
根据[1]中给出的结论,对于1维卷积 F ( m , r ) F(m,r) F(m,r)的Winograd算法,其需要的乘法个数为 m + r − 1 m+r-1 m+r−1。对于2维卷积 F ( m × n , r × s ) F(m\times n,r\times s) F(m×n,r×s)的Winograd算法,其需要的乘法个数为 ( m + r − 1 ) × ( n + s − 1 ) (m+r-1)\times(n+s-1) (m+r−1)×(n+s−1)。当 n = m n=m n=m以及 s = r s=r s=r时,卷积 F ( m × m , r × r ) F(m\times m,r\times r) F(m×m,r×r)的Winograd算法需要的乘法个数为 ( m + r − 1 ) × ( m + r − 1 ) (m+r-1)\times(m+r-1) (m+r−1)×(m+r−1)。
4. 将2维卷积 F ( m × m , r × r ) F(m\times m,r\times r) F(m×m,r×r)的Winograd算法运用到神经网络的卷积
参考文献[1]中的Algorithm 1直接给出了将2维卷积
F
(
m
×
m
,
r
×
r
)
F(m\times m,r\times r)
F(m×m,r×r)的Winograd算法运用到神经网络的卷积的方法。

假设每张图片有
C
C
C个信道,mini-batch大小为
N
N
N(一次处理N张图片)。假设有
K
K
K个filter,每个filter有
C
C
C个卷积核。

如上图所示,每个filter有C个信道,每张图片也有C个信道,于是这C个信道对应的卷积核和像素矩阵一一对应卷积,即对于某个filter来说,当他操作于某张图片时,该filter的信道i对应的卷积核卷积该图片的信道i对应的像素矩阵(如图中蓝色箭头表示),C个信道做完卷积后,将结果相加。因此,一个filter作用于一张图片得到一个结果矩阵。图中我们有K个filter,作用于一个mini-batch的N个图片,得到
K
×
N
K\times N
K×N个结果矩阵。
要使用二维卷积
F
(
m
×
m
,
r
×
r
)
F(m\times m,r\times r)
F(m×m,r×r),则需要将每张图片的每个像素矩阵分割成多个相互重叠的子矩阵。这个子矩阵的大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1),相邻子矩阵之间重叠长度为
r
−
1
r-1
r−1。这样的分割可以使一个卷积核在一张像素图上的卷积变为该卷积核分别在多个大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1)的子矩阵上的卷积。这个大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1)的子矩阵在[1]中被称为1个tile。

上图给出了一个
3
×
3
3\times 3
3×3的卷积核在一个
6
×
6
6\times 6
6×6的像素矩阵上利用Winograd算法进行卷积的图示。
根据上面的图示分析可知,对于每一个信道,我们需要将每个像素矩阵分为若干个大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1)的子矩阵(tile),对于一个mini-batch中的N个像素矩阵进行这样分割,可以得到
P
P
P个大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1)的子矩阵(tile),这也是Algorithm 1中的
P
P
P。至此,对于
(
i
,
j
)
∈
{
0
,
1
,
2
,
…
,
K
−
1
}
×
{
0
,
1
,
…
,
P
−
1
}
(i,j)\in \{0,1,2,\dots,K-1\}\times \{0,1,\dots,P-1\}
(i,j)∈{0,1,2,…,K−1}×{0,1,…,P−1},要完成一个filter(
C
C
C个卷积核)与其对应的
C
C
C个通道的大小为
(
m
+
r
−
1
)
×
(
m
+
r
−
1
)
(m+r-1)\times(m+r-1)
(m+r−1)×(m+r−1)的子矩阵(tile)卷积运算,这样的运算需要
K
×
P
K\times P
K×P次。这也是为什么Algorithm 1的最后一个循环是基于K和P的。
再来看看上述一个操作里面多个通道相加对于二维卷积Winograd公式的影响。记通道索引为
i
i
i,也即卷积核的索引为
i
i
i,于是有
i
=
0
,
1
,
…
,
C
−
1
i=0,1,\dots,C-1
i=0,1,…,C−1。对应的卷积核矩阵记为
w
i
w_i
wi,该通道对应的像素子矩阵(tile)记为
k
i
k_i
ki。根据之前得到的Winograd公式,卷积的结果矩阵可以表示为
A
T
[
(
G
w
i
G
T
)
⊙
(
B
T
k
i
B
)
]
A
.
A^T\left[ (Gw_iG^T)\odot(B^Tk_iB) \right]A.
AT[(GwiGT)⊙(BTkiB)]A.
最终的卷积结果需要将
C
C
C个通道的卷积结果相加,即
∑
i
=
0
,
1
,
…
,
C
−
1
A
T
[
(
G
w
i
G
T
)
⊙
(
B
T
k
i
B
)
]
A
=
A
T
[
∑
i
=
0
,
1
,
…
,
C
−
1
(
G
w
i
G
T
)
⊙
(
B
T
k
i
B
)
]
A
.
\sum_{i=0,1,\dots,C-1}A^T\left[ (Gw_iG^T)\odot(B^Tk_iB) \right]A= A^T\left[\sum_{i=0,1,\dots,C-1} (Gw_iG^T)\odot(B^Tk_iB) \right]A.
i=0,1,…,C−1∑AT[(GwiGT)⊙(BTkiB)]A=AT⎣⎡i=0,1,…,C−1∑(GwiGT)⊙(BTkiB)⎦⎤A.
但是上式没有表现出不同filter和不同子矩阵(tile)的索引,为了进一步简化符号,并表明filter和子矩阵(tile)的索引,记
w
(
k
,
c
)
w^{(k,c)}
w(k,c)为filter
k
k
k的第
c
c
c个通道的卷积核,并记
U
k
,
c
=
G
w
(
k
,
c
)
G
T
U_{k,c}=Gw^{(k,c)}G^T
Uk,c=Gw(k,c)GT,其中
k
=
0
,
1
,
…
,
K
−
1
k=0,1,\dots,K-1
k=0,1,…,K−1,
c
=
0
,
1
,
…
,
C
−
1
c=0,1,\dots,C-1
c=0,1,…,C−1。这里为了和矩阵元素下标相区别,将索引
k
,
c
k,c
k,c放在
w
w
w的商标。同理,记
k
(
b
,
c
)
k^{(b,c)}
k(b,c)为第
b
b
b个子矩阵组的第
c
c
c个通道的子矩阵(tile),并记
V
b
,
c
=
B
T
k
(
b
,
c
)
B
V_{b,c}=B^Tk^{(b,c)}B
Vb,c=BTk(b,c)B,其中
b
=
0
,
1
,
…
,
P
−
1
b=0,1,\dots,P-1
b=0,1,…,P−1,
c
=
0
,
1
,
…
,
C
−
1
c=0,1,\dots,C-1
c=0,1,…,C−1。于是对于某个
k
k
k和
b
b
b,我们需要先求得
∑
i
=
0
,
1
,
…
,
C
−
1
U
k
,
i
⊙
V
b
,
i
,
\sum_{i=0,1,\dots,C-1} U_{k,i}\odot V_{b,i},
i=0,1,…,C−1∑Uk,i⊙Vb,i,
然后计算
A
T
[
∑
i
=
0
,
1
,
…
,
C
−
1
U
k
,
i
⊙
V
b
,
i
]
A
.
A^T\left[\sum_{i=0,1,\dots,C-1} U_{k,i}\odot V_{b,i}\right]A.
AT⎣⎡i=0,1,…,C−1∑Uk,i⊙Vb,i⎦⎤A.
至此,再来看看Algorithm 1中的几个循环。第一个基于K和C的循环即是在求 K × C K\times C K×C个卷积核对应的 U k , i U_{k,i} Uk,i, k = 0 , 1 , … , K − 1 k=0,1,\dots,K-1 k=0,1,…,K−1, i = 0 , 1 , … , C − 1 i=0,1,\dots,C-1 i=0,1,…,C−1。第二个基于P和C的循环其实是在求 P × C P\times C P×C个像素子矩阵(tile)对应的 V b , c V_{b,c} Vb,c, b = 0 , 1 , … , P − 1 b=0,1,\dots,P-1 b=0,1,…,P−1, i = 0 , 1 , … , C − 1 i=0,1,\dots,C-1 i=0,1,…,C−1。第三个循环实现 U k , i U_{k,i} Uk,i和 V b , c V_{b,c} Vb,c的点乘与求和,即 ∑ i = 0 , 1 , … , C − 1 U k , i ⊙ V b , i \sum_{i=0,1,\dots,C-1}U_{k,i}\odot V_{b,i} ∑i=0,1,…,C−1Uk,i⊙Vb,i。最后一个循环实现左右分别乘 A T A^T AT和 A A A。
5. 参考文献
[1] A. Lavin and S. Gray, Fast Algorithms for Convolutional Neural Networks, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4013-4021.
[2] 日拱一卒,《卷积神经网络中的Winograd快速卷积算法》,2019-05-22.

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









