



在linux编程中,有可能会在条件判断中见到likely(expr)和unlikely(expr)的用法,它们实际上是宏定义:
#define likely(x) __builtin_expect((x), 1)
#define unlikely(x) __builtin_expect((x), 0)
是在告诉编译器,这个表达式为true的概率是大还是小,这样能指导编译器在处理分支判断的跳转时,更好地利用程序的空间局部性(CPU对指令的cache)。
下面举个例子来说明编译器具体是怎么优化likely和unlikely的:
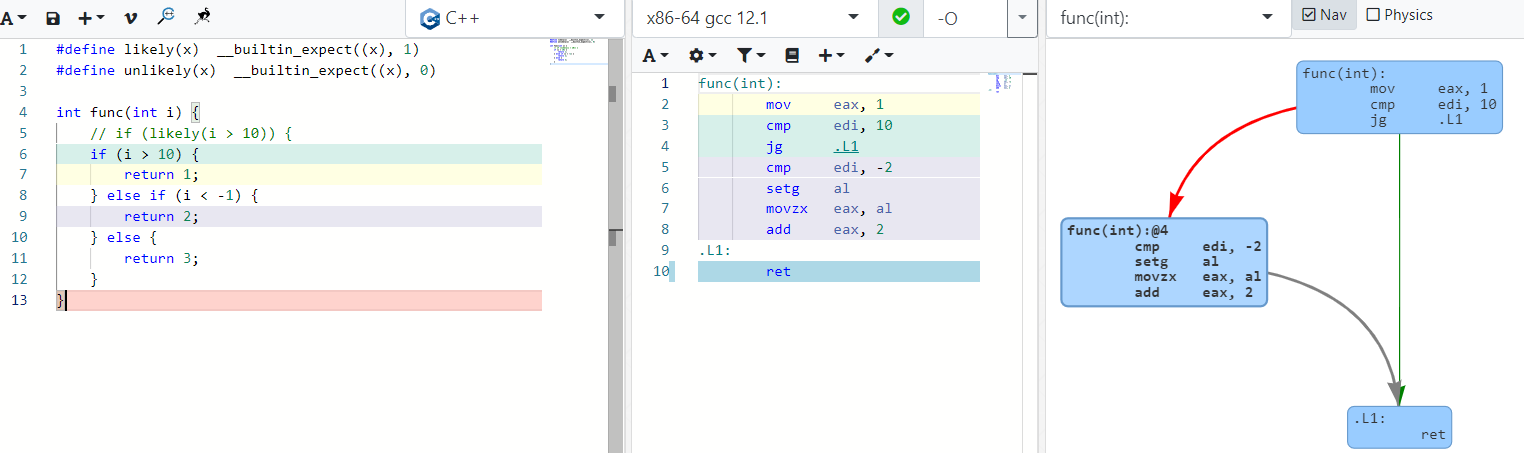
如果没有加likely,对于第一个判断,如果i > 10成立,会跳转到.L1这个离当前代码块较远的位置(本测试程序的例子还好,实际的程序中可能会比较远),可能.L1的代码并没有在cache中。
如果给i > 10加上likely,
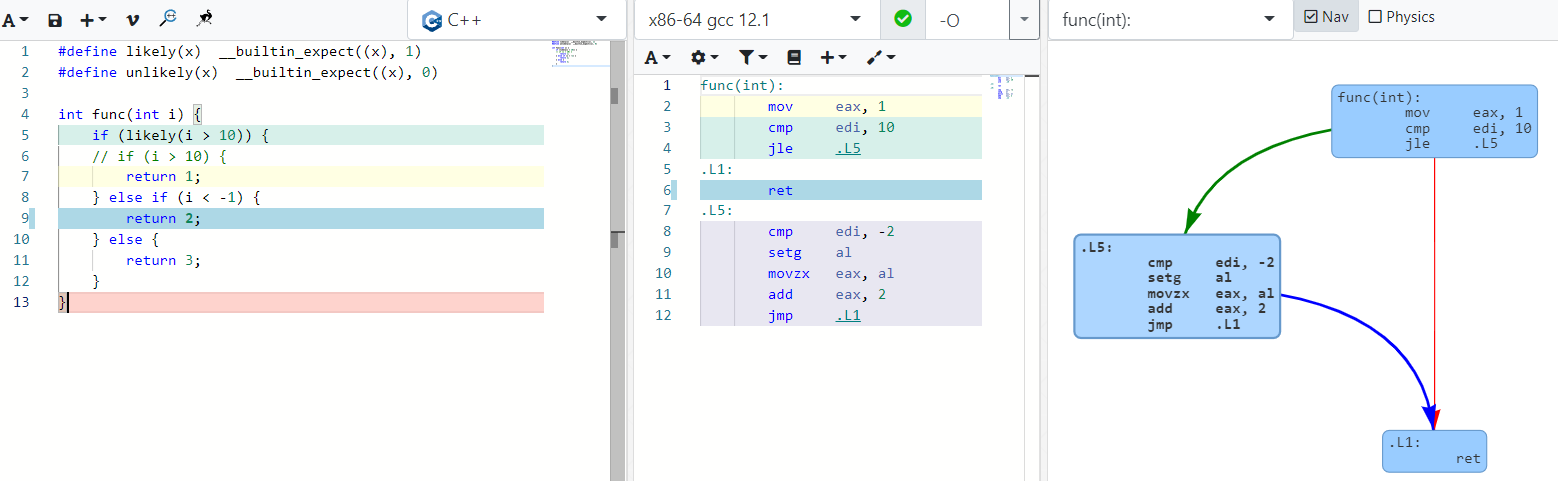
由于认为i > 10的概率较大,因此若表达式为true,则顺序执行到.L1,不会跳转到其他代码块,.L1的代码很可能在cache内,充分利用了指令cache。
如果大家对文章内容有疑问或建议,欢迎评论区留言,我们可以一起讨论,共同提高
转载请标明原作者:https://blog.youkuaiyun.com/qq_36622751

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









