




基本思想
若把样本的多维特征空间的点投影到一条直线上,就能把特征空间压缩成一维。那么关键就是找到这条直线的方向,找得好,分得好,找不好,就混在一起。因此fisher方法目标就是找到这个最好的直线方向以及如何实现向最好方向投影的变换。这个投影变换恰是我们所寻求的解向量 ,这是fisher算法的基本问题。
样本训练集以及待测样本的特征数目为n。为了找到最佳投影方向,需要计算出各类均值、样本类内离散度矩阵 和总类间离散度矩阵、样本类间离散度矩阵,根据Fisher准则,找到最佳投影准则,将训练集内所有样本进行投影,投影到一维Y空间,由于Y空间是一维的,则需要求出Y空间的划分边界点,找到边界点后,就可以对待测样本进行一维Y空间的投影,判断它的投影点与分界点的关系,将其归类。
主要用到的函数(二分类问题时):
function W = FisherLDA(w1,w2)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%w1为第一类样本
%w2为第二类样本
%W为权值向量
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%第一步:计算样本均值向量
M1 = mean(w1);
M2 = mean(w2);
M = mean([w1;w2]);
%第二步:计算类内离散度矩阵Sw
p = size(w1,1);
q = size(w2,1);
S1 = 0;
for i = 1:p
S1 = S1 + (w1(i,:)-M1)'*(w1(i,:)-M1);
end
S2 = 0;
for i = 1:q
S2 = S2 + (w2(i,:)-M2)'*(w2(i,:)-M2);
end
Sw = (p*S1+q*S2)/(p+q);
%第三步:计算类间离散度矩阵Sb
S1 = M - M1;
S2 = M - M2;
Sb = (p*S1'*S1 + q*S2'*S2)/(p+q);
%第四步:求最大特征值和特征向量
A = repmat(0.1,[1,size(Sw,1)]);
B = diag(A);
[V,L]=eig(inv(Sw + B)*Sb);
[a,b]=max(max(L));
W = V(:,b);%最大特征值所对应的特征向量
一:
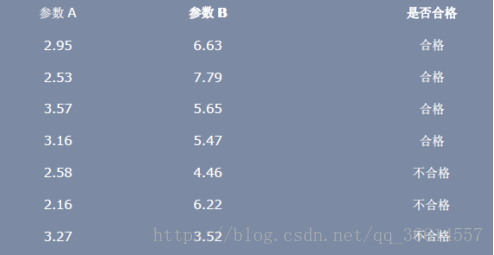
根据上图,我们可以把样本分为两类,一类是合格的产品,一类是不合格的产品。通过LDA算法对训练样本的投影获得判别函数,然后判断测试样本的类别,即输入一个样本的参数,判断该产品是否合格。
实验代码:
w1=[2.95 6.63;2.53 7.79;3.57 5.65;3.16 5.47];
w2=[2.58 4.46;2.16 6.22;3.27 3.52];
W=FisherLDA(w1,w2);
for i=1:length(w1)
y(i)=W'*w1(i,:)';
end
for j=1:length(w2)
y(i+j)=W'*w2(j,:)';
end
thre=mean(y(i:i+1));
x(1)=input('参数A');
x(2)=input('参数B');
dy=W'*x';
if (dy<=thre)
display('合格');
else
display('不合格');
end
运行结果:输入[3 5]:
参数A3
参数B5
合格
二:
基于ORL人脸库,实验样本主要来自于两个人,每人45张图片,共有90个样本,其中的80个样本作为训练样本,10个作为测试样本。通过LDA实现两类问题的线性判别。
运行代码:
%读入训练集1
fpath = 'F:\Arti 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
























 1022
1022



 到【灌水乐园】发言
到【灌水乐园】发言







