




 本文提出了一种无源图像翻译(SFIT)方法,用于在无源域自适应(UDA)中可视化知识差异。通过生成器网络,将目标图像转化为源样式,同时使用知识蒸馏损失和关系保持损失来保持特征映射之间的相对通道关系,从而在源模型和目标模型之间建立联系。这种方法有助于理解域适应过程中模型学到的知识。
本文提出了一种无源图像翻译(SFIT)方法,用于在无源域自适应(UDA)中可视化知识差异。通过生成器网络,将目标图像转化为源样式,同时使用知识蒸馏损失和关系保持损失来保持特征映射之间的相对通道关系,从而在源模型和目标模型之间建立联系。这种方法有助于理解域适应过程中模型学到的知识。
论文地址:https://arxiv.org/abs/2104.10602
开源code:https://github.com/houyz/DA_visualization
引言
域转移或域适配旨在弥补源域和目标域之间的分布差距。许多现有的工作研究了无监督域自适应(UDA)问题,其中目标域是未标记的。
文章基于UDA方法(主要可以用Source-free),提出了一种基于target model和source model下只利用目标域图像生成更加接近源域目标风格图像的方法,解决了在只有模型而无法获取源域数据的情况下(source-free)如何可视化两个域间的知识差异(knowledge difference)的问题。
用图像差异代替模型差异,并且利用生成的图像,可以进一步对target model进行finetune。
在本文中,提出了一种无源图像翻译(SFIT)的方法,在不使用源图像的情况下,将目标图像翻译成源样式。具体地说,将翻译后的源样式图像提供给源模型,将原始目标图像提供给目标模型,并通过更新生成器网络强制这两个分支的类似输出。为此,使用了传统的知识蒸馏损失和一种新的关系保持损失,保持了特征映射之间的相对通道关系。
结果表明,在改变图像风格的同时,所提出的保持关系的损失也有助于缩小域间的差距,从域自适应的角度进一步解释了所提出的方法。一些结果如图1所示,观察到,即使在源自由设置下,来自两个模型的知识仍然可以驱动从目标样式到源样式的样式转换(SFIT降低颜色饱和度并使背景变白以模拟看不见的源样式)

方法
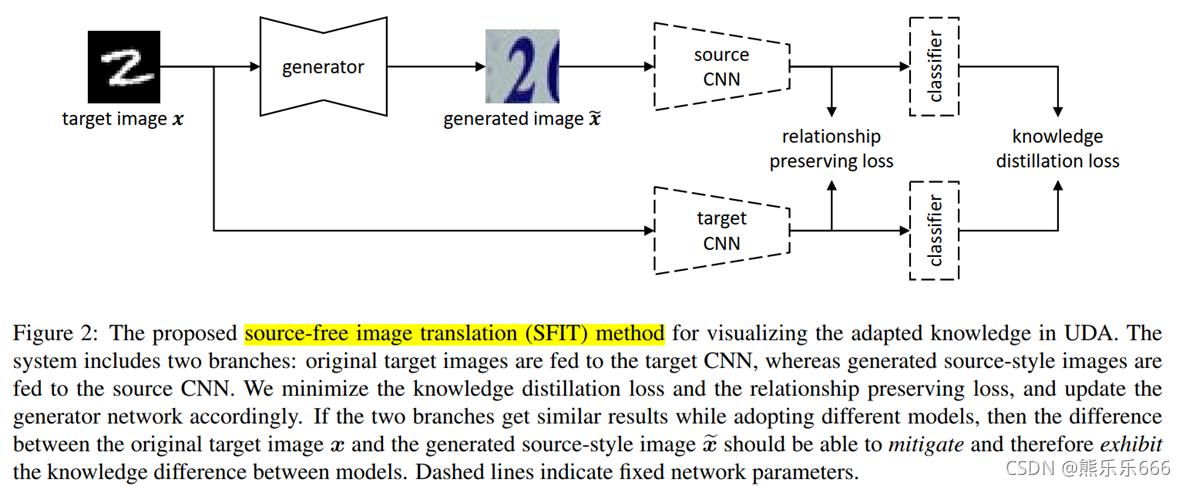
为了实现我们的目标,即在UDA中可视化自适应的知识,将一个图像 从一个特定的域转换成一个新的图像
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









