




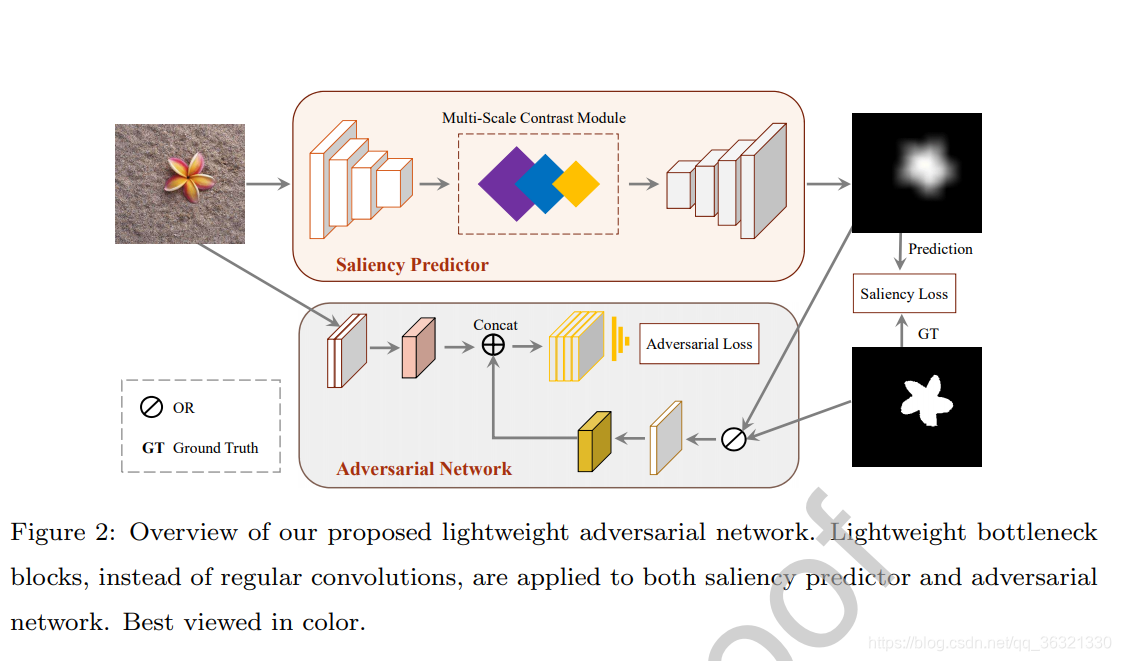
 该博客介绍了LANet模型,它使用轻量级瓶颈块(Lightweight Bottleneck Block)降低计算复杂度,并结合Adversarial Training进行细化。通过Multi-Scale Contrast Module融合全局和局部信息。模型基于VGG16,使用SPP模块进行空间金字塔池化,以生成高精度的显著性图。同时,文中还定义了对抗网络(Discriminator)以提升预测性能。
该博客介绍了LANet模型,它使用轻量级瓶颈块(Lightweight Bottleneck Block)降低计算复杂度,并结合Adversarial Training进行细化。通过Multi-Scale Contrast Module融合全局和局部信息。模型基于VGG16,使用SPP模块进行空间金字塔池化,以生成高精度的显著性图。同时,文中还定义了对抗网络(Discriminator)以提升预测性能。
1. Lightweight Bottleneck Block
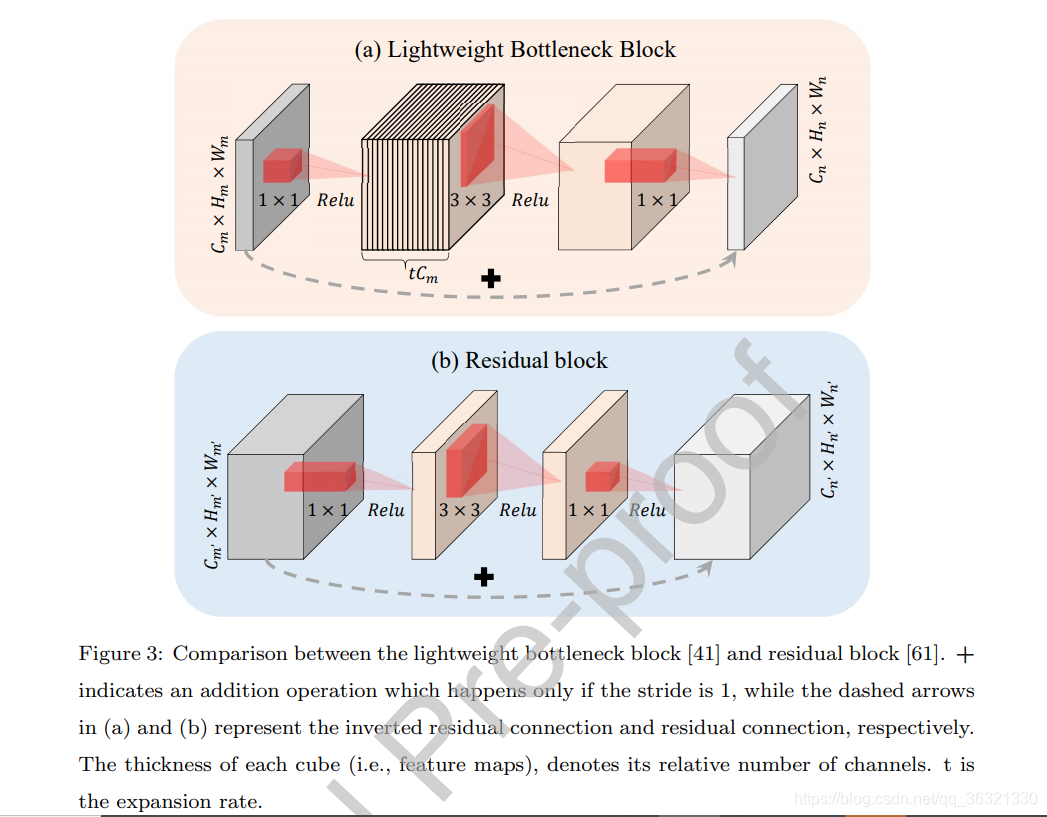
此模块是LANet的基本模块,工程上来说,先用1×1的卷积将输入特征图映射到高维空间,然后使用K×K的卷积进行filter,最后再用1×1的卷积进行降维,以此来降低计算复杂度。并且,skip connection 加在了"薄的特征图上",而不是“厚的特征图”。
2. Adversarial Training
只使用CNN得到的显著性图不是很完整,所以加了一个GAN进行fine-tuning。Saliency loss使用的是二值交叉熵。对抗损失如下:
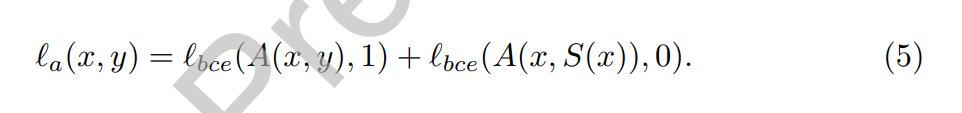
A(x,y)是对抗模型预测y是x显著性图的概率。S(x)是saliency predictor的输出。
训练Saliency Predictor的时候,使用如下损失,使得S(x^k)是x^k的显著性图的机率越大越好:
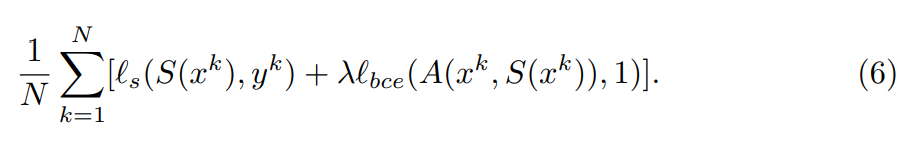
训练Adversarial Networkde时候,最小化如下损失:
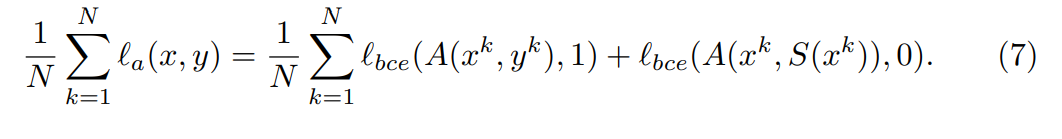
3. Multi-Scale Contrast Module
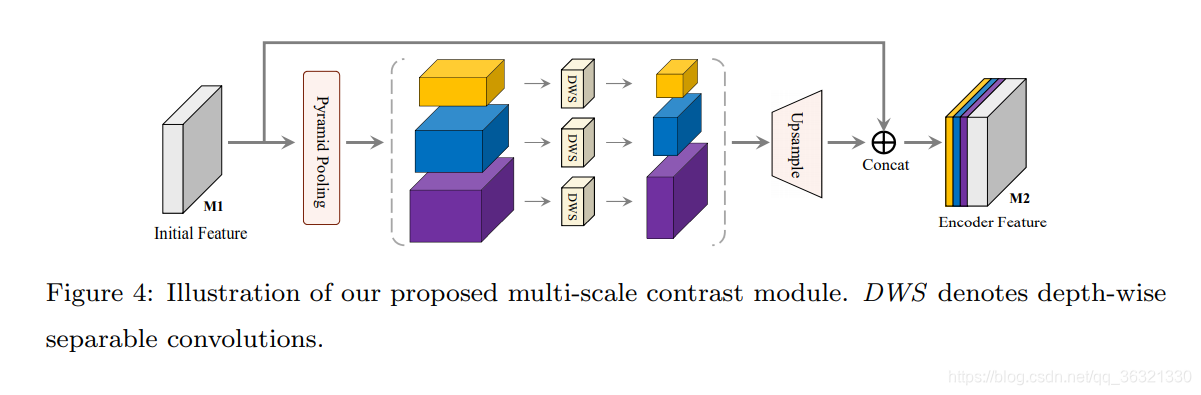
主要用于结合全局和局部的上下文信息,空间金字塔中使用了三种不同大小的kernel进行filter,以产生不同尺度的特征图。将这三部分特征图分别经过深度可分离卷积,以将特征图通道变为原来的1/3。最后其采用双线性插值变为输入特征图的大小并进行concat,得到最终的输入特征图。
4. Network Architecture
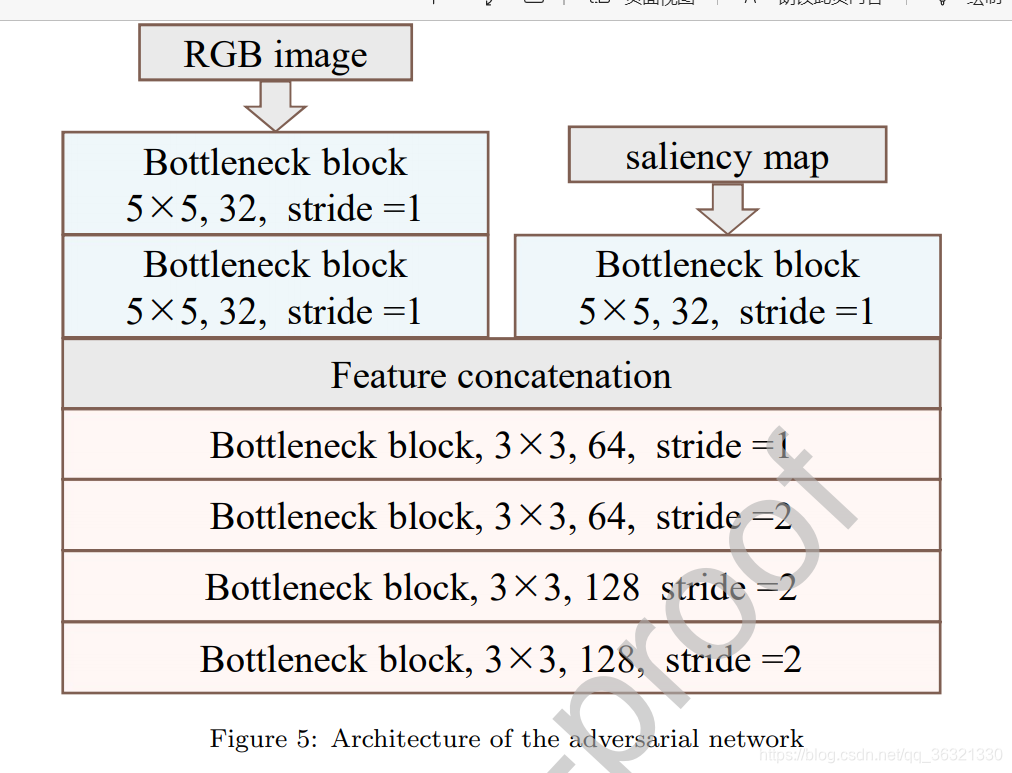
Saliency Predictor使用VGG16(将里面的卷积替换成lightweight bottleneck blocks)。
Adversarial Network的结构见图5,输入的图像都resize成224×224。
import torch
import torch.nn as nn
import torch.nn.functional
from torch.nn import init
from collections import OrderedDict
import numpy as np
class LinearBottleneck(nn.Module):
def __init__(self,inplanes,outplanes,stride,t,activation=nn.ReLU6,kernel_size = [3,3],padding = 1):
'''
:param inplanes:
:param outplanes:
:param stride:
:param t:
:param activation:
'''
'''
首先利用点卷积升维,然后利用深度卷积计算,最后利用点卷积降维,每个卷积后跟着BN和激活函数
'''
super(LinearBottleneck,self).__init__()
self.conv1 = nn.Conv2d(inplanes,t*inplanes,kernel_size=1,bias=False)
self.bn1 = nn.BatchNorm2d(inplanes*t)
self.conv2 = nn.Conv2d(inplanes*t,inplanes*t,kernel_size=kernel_size,stride=stride,padding=padding,bias=False,groups=t*inplanes)
self.bn2 = nn.BatchNorm2d(inplanes*t)
self.conv3 = nn.Conv2d(inplanes*6,outplanes,kernel_size=1,bias=False)
self.bn3 = nn.BatchNorm2d(outplanes)
self.activation = activation(inplace=True)
self.inplanes = inplanes
self.outplanes = outplanes
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.activation(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.activation(out)
out = self.conv3(out)
out = self.bn3(out)
#out = self.activation(out)
if self.stride==1 and self.inplanes==self.outplanes:
out = out+residual
return out
class SPP(nn.Module):
def __init__(self,in_channels):
nn.Module.__init__(self)
self.pool1 = x1 = nn.AvgPool2d([16,16])
self.pool2 = nn.AvgPool2d([8,8])
self.pool3 = nn.AvgPool2d([2,2])
self.conv1 = nn.Conv2d(in_channels,in_channels, kernel_size=1, stride=1, bias=False,
groups=in_channels)
self.conv2 = nn.Conv2d(in_channels,in_channels//3,kernel_size=1,bias=False)
self.conv3 = nn.Conv2d(in_channels,in_channels, kernel_size=1, stride=1, bias=False,
groups=in_channels)
self.conv4 = nn.Conv2d(in_channels, in_channels // 3, kernel_size=1, bias=False)
self.conv5 = nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, bias=False,
groups=in_channels)
self.conv6 = nn.Conv2d(in_channels, in_channels // 3, kernel_size=1, bias=False)
#torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
def forward(self, x):
x_size = x.size()[2:]
out = x
x1 = self.pool1(x)
x2 = self.pool2(x)
x3 = self.pool3(x)
x1 = self.conv1(x1)
x1 = self.conv2(x1)
x2 = self.conv3(x2)
x2 = self.conv4(x2)
x3 = self.conv5(x3)
x3 = self.conv6(x3)
x1 = nn.functional.interpolate(x1, size=x_size, mode='bilinear',align_corners=True)
x2 = nn.functional.interpolate(x2, size=x_size, mode='bilinear',align_corners=True)
x3 = nn.functional.interpolate(x3, size=x_size, mode='bilinear',align_corners=True)
x4 = torch.cat([x1,x2,x3,out],1)
return x4
base = {'352': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512]}
def vgg16(cfg, inchannels, batch_norm=False):
layer = []
inchannels = inchannels
for v in cfg:
if v == 'M':
layer += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = LinearBottleneck(inchannels,v,stride=1,t=6)
if batch_norm:
layer += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layer += [conv2d, nn.ReLU(inplace=True)]
inchannels = v
return layer
class LANet(nn.Module):#相当于生成器
def __init__(self,vgg=vgg16(base['352'],3),spp=SPP(512)):
nn.Module.__init__(self)
self.vgg = nn.ModuleList(vgg)
self.spp = spp
self.conv = LinearBottleneck(1022,512,1,6)
self.convLast = LinearBottleneck(512, 1, 1, 6)
def forward(self,x):
for i in range(len(self.vgg)):
x = self.vgg[i](x)
x = self.spp(x)
x = self.conv(x)
x = self.convLast(x)
x = nn.functional.interpolate(x,scale_factor=16)#decoder
return x
class Discriminate():
def __init__(self):
super(Discriminate,self).__init__()
self.linearBottleneck1 = LinearBottleneck(3,32,stride=1,t=6,padding = 2,kernel_size=[5, 5])
self.linearBottleneck2 = LinearBottleneck(32,32,stride=1,t=6,padding = 2,kernel_size=[5, 5])
self.linearBottleneck3 = LinearBottleneck(1,32,stride=1,t=6,padding = 2,kernel_size=[5, 5])
self.linearBottleneck4 = LinearBottleneck(64,64,stride=1,t=6,padding = 1,kernel_size=[3, 3])
self.linearBottleneck5 = LinearBottleneck(64, 64, stride=2, t=6, padding=1, kernel_size=[3, 3])
self.linearBottleneck6 = LinearBottleneck(64, 128, stride=2, t=6, padding=1, kernel_size=[3, 3])
self.linearBottleneck7 = LinearBottleneck(128, 128, stride=2, t=6, padding=1, kernel_size=[3, 3])
self.fc = nn.Sequential(
nn.Linear(int(np.prod(32,32,128)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self,img,mask):
x1 = self.linearBottleneck1(img)
x1 = self.linearBottleneck2(x1)
x2 = self.linearBottleneck3(mask)
x3 = torch.cat([x1,x2],1)
x3 = self.linearBottleneck4(x3)
x3 = self.linearBottleneck5(x3)
x3 = self.linearBottleneck6(x3)
x3 = self.fc(x3)
return x3
def xavier(param):
init.xavier_uniform_(param)
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
m.bias.data.zero_()
















 8836
8836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









