




 提出一种轻量级对抗网络LANet,用于显著目标检测,通过轻量级瓶颈块和多尺度对比模块提高准确性和效率,实现在嵌入式应用中的实时运行。
提出一种轻量级对抗网络LANet,用于显著目标检测,通过轻量级瓶颈块和多尺度对比模块提高准确性和效率,实现在嵌入式应用中的实时运行。
Abstract
作者提出了一种用于显着目标检测(salient object detection)的轻量级对抗网络,该网络通过进行对抗性训练来实现更高阶的空间一致性,并分别通过轻量级bottleneck block降低了计算成本,从而同时提高了准确性和效率。
1.Introduction
在计算机上,鉴别器区分输入图像的真实性,并进一步导致更完整的显着性检测结果,这启发我们将对抗性训练引入视觉显着性学习中,目前最常见的后处理方法是CRF。
LANet将对抗损失放入视觉显著性学习中,利用编码器-解码器结构进行显著性推理。
本文的贡献:
- 我们提出了一个准确有效的网络,即LANet,用于显着目标检测,该网络利用轻量级的线性瓶颈模块(lightweight linear bottleneck blocks)来构造显着性预测器和对抗性网络,从而大大降低了计算成本以确保效率。
- 提出多尺度对比模块(Multi-scale contrast module)
- 此模型对于准确性和效率两方面进行了折衷。
2.Related Work
2.1 Salient Object Detection
《 Deeply supervised salient object detection with short connections》提出了一种深度监督的模型(deeply supervised salient model),但是这个模型需要高性能的计算资源,使得无法应用于嵌入式和移动设备。
2.2 Adversarial Learning
生成对抗网络由生成网络和对抗网络组成,是一种用于学习深度生成模型的对抗方法。 它最初是为图像生成而设计的,其中生成网络用于生成伪造图像,而对抗网络则旨在区分真实图像和生成网络生成的伪造图像。
最近,一些工作将GAN扩展到显着目标检测。 在本文中,我们提出了一种用于目标物体检测的轻量级对抗网络,该网络将高级对抗损失纳入了网络训练期间的常规显着性预测中。
3.Lightweight Adversarial Network

如图2所示,LANet由显着性预测器(saliency predictor)和对抗性网络(adversarial network)组成,二者均基于轻量级瓶颈块(lightweight bottleneck)而不是规则卷积,从而实现了有效的端到端解决方案。
显着性预测器包括特征提取器,多尺度对比度模块和解码器,用于生成显着性图。 具体来说,在给定图像的情况下,我们采用特征提取器(即定制的VGG)来生成初始特征图,然后将其馈入多尺度对比度模块以生成最终的编码器特征图。 然后,通过解码器对得到的特征图进行上采样以产生最终显着性预测。
在训练阶段,此网络最初在预测的显着性图上以显着性损失进行训练。 然后,该模型通过对抗网络进行训练,该对抗网络经过训练可以解决LANet预测的显着性图和相应的地面真实性之间的二元分类任务。
3.1. Lightweight Bottleneck Block

Lightweight Bottleneck Block是LANet中每个部分的基本单元。如上图,轻量级瓶颈块的特征在于深度方向上可分离的卷积,线性瓶颈(linear bottlenecks)和倒数残差(inverted residuals)。
特别地,将深度方向上可分离的卷积依次分解为深度方向卷积和点方向卷积,即1×1卷积。 深度方向卷积使用不同的卷积核过滤每个输入通道,而点方向卷积进一步融合所有通道上的合成特征以产生新的特征表示。
如图可以直观地观察到,轻量级瓶颈块首先通过逐点卷积将输入扩展到更高的维度,然后通过深度卷积来过滤高维度的结果,最后通过另一个点卷积来减小结果特征的维度。
深度方向可分离卷积的主要贡献是减少了计算量。
给定输入张量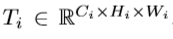 kernel尺寸是K×K卷积,得到特征图
kernel尺寸是K×K卷积,得到特征图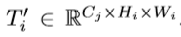 深度方向可分离卷积的相应计算成本M为:
深度方向可分离卷积的相应计算成本M为:
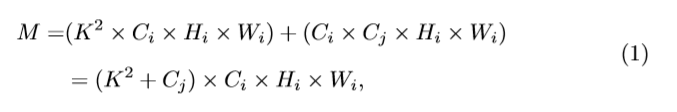
而常规卷积运算的计算成本R为:

轻量级瓶颈块中的反向残差(inverted residual)用于加快训练和推理的过程。 如图3(a)所示,它在维数减少后的输入层和各层之间建立了快捷链接,这仅在步幅为1时发生。
反向残差(inverted residual)与经典残差(the classical residual)之间的差异是:(a)中的倒数残差连接了较薄的立方体(特征图),而(b)中的经典残差则连接了较厚的立方体。 此外,为了防止有用的信息被破坏,瓶颈块摆脱了其最后一层的非线性激活。
3.2. Adversarial Training
在使用基于CNN的模型时,预测的显着性图通常不完整,即在空间上与相应的Ground Truth不一致。 我们利用对抗训练,将对抗损失纳入saliency predictor中,以实现更高阶的空间一致性。 具体而言,我们在训练LANet时既考虑了显着性损失Ls也考虑了对抗性损失La。
为了便于说明,将这两个术语中使用的二进制交叉熵损失表示为

显着性损失是一个标准的二进制交叉熵,用于执行显着性模型以独立预测每个像素位置的准确显着性,但是无法实现更高阶的空间一致性。
给定N个训练图像 xk∈RH×W×3 的数据集和相应的ground-truth yk∈{0,1} H×W,我们使用y^ = S(x)表示预测的显着图。 然后,显着性损失可以计算为

由于对抗网络处理二进制分类问题,导致感受野比显着性预测器大得多,因此对抗训练可以实现更高阶的空间一致性。
将A(x,y)∈[0,1]表示为对抗网络预测y是x的真实情况显着性图的概率,S(•)是显着性预测器的输出。 因此,对抗性损失也由二进制交叉熵损失表示:

Training the Saliency Predictor 在给定对抗网络的情况下,对显着性预测器的训练旨在最大程度地减少显着性损失,t同时降低对抗性网络的性能。 这鼓励了显着性预测器生成难以与对抗性网络的ground-truth图区分开的显着性图。 it propagates stronger gradient to maximize bce(A(xk,S(xk)),1) than to minimize bce(A(xk,S(xk)),0)。与显着性预测器相关的损失函数为

Training the Adversarial Network
由于对抗性损失仅取决于对抗性网络,因此训练对抗性网络等效于最小化以下二进制分类损失

合并对抗性损失不会在测试阶段消耗额外的计算资源。 Lightweight bottleneck(对抗网络的基本单位)也使训练更加有效。 显着性预测器和对抗性网络的体系结构将在下面的第3.4节中介绍。
3.3. Multi-Scale Contrast Module

如前所述,我们提出的基于bottleneck blocks的LANet无法充分融合先前的关键全局对比度,这是因为vanilla CNN和轻型瓶颈块中的接受域都大大损失了。 为了解决这个问题,我们提出了一种多尺度对比模块,以正确地结合全局和局部上下文,以进行精确的显着性检测。
空间金字塔平均池可以利用空间统计信息有效地描述整个图像。 如图4所示,多尺度对比模块(multi-scale contrast module)包含金字塔平均池,深度方向可分离卷积(即深度方向卷积与点方向卷积耦合)以及上采样操作。
为了从初始特征M1分别提取局部和全局视觉对比信息,我们在执行金字塔平均池化时考虑了三个不同级别的大小.实验表明,深度可分离卷积将计算精度提高了约0.6%,而计算成本却可以忽略不计。
3.4. Network Architecture

显着性预测器的体系结构。 在显着性预测器中,特征提取器由VGG16的卷积层组成[59],其中常规卷积被轻量级瓶颈块替换以减少模型参数,而解码器通过无参数双线性插值的上采样以16的倍数生成显着图。
对抗网络的体系结构。 对抗网络的体系结构如图5所示。它以RGB图像和相应的显着性图作为输入,这两种图像在馈入网络之前都被调整为224×224。 显着性图要么是基础事实,要么是由显着性预测器生成的。 如[68]中所建议的,从图5中的两个220个独立分支生成的特征图具有相同数量的通道。
4.Experimental Results
评价标准:
F-measure,mean absolute error(MAE), precision-recall(PR)
F-measure:

其中β2设置成0.3可以突显精度的重要性。
MAE:
MAE 以像素为单位测量ground-truth G与预测显着图M之间的数值距离

W和H表示显著性图的宽度和高度
M(i,j)表示像素在(i,j)的显著性值
G(i,j)表示像素在(i,j)的真实值
在bottleneck blocks 中的扩张率设置成6
显著性损失和对抗性损失都被公式化为二值交叉熵损失
作者使用验证集搜索最佳的超参数λ,最终我们使用15
Conclusion
最终的结果表明,对抗训练比CRF可以更好地缓解不完整的预测显着性图的问题。LANet降低计算成本、加快了训练速度、并且在准确性和效率方面有更好的优越性,可以更好的应用在实时的嵌入式应用中。

















 8704
8704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









