






备注:
By 远方时光原创,可转载,open
合作微信公众号:大数据左右手
背景:
在处理500个GB历史数据orderBy('key')时候遇到的shuffle问题
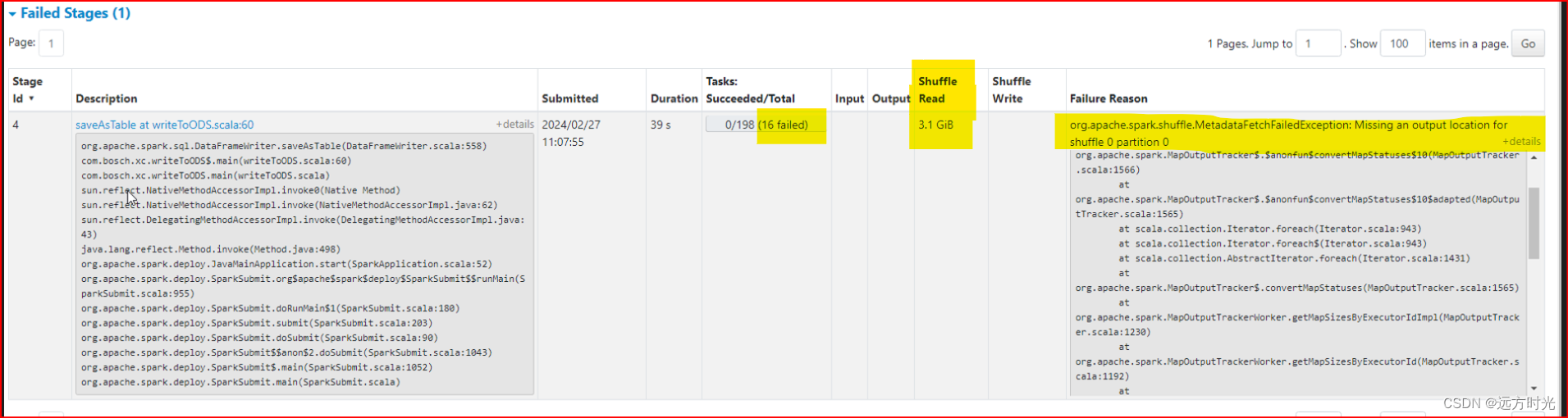
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0 partition 0一般在执行数据量较大的spark任务时经常会出现MetadataFetchFailedException
报错分析:
这里是报的shuffle中获取不到元数据的异常,没有空间用于shuffle了
shuffle又分为shuffle read(理解为mapReduce中的map) 和shuffle write (理解为mapReduce中的Reduce)两个部分。shuffle write的分区数由上一阶段的RDD分区数控制,shuffle read(Map阶段)的时候数据的分区数则是由spark提供的一些参数控制,如果这个参数值设置的很小,同时shuffle read的量很大,那么将会导致一个task需要处理的数据非常大。结果导致JVM crash,从而导致取shuffle数据失败,同时executor也丢失了。
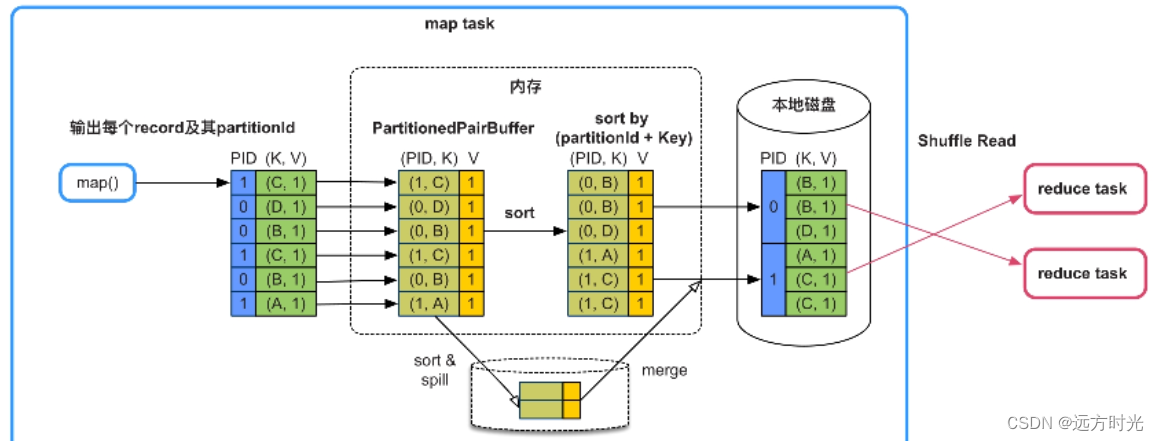
简单来说就是下图,蓝色框框map Task资源不足,或者能够工作的map task不够多(并行度不够),来处理那么多数据
知识回顾
什么叫MapReduce:
一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书数量。小罗数1号书架,小蒋数2号书架。这就是“ Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“ Reduce”
注:大数据处理数据能力增强无非就是:1.增加数书的人数(并行度增加) 2.加强数书人自身能力,比如小罗会一目十行,记忆力变高(core,内存增加)
什么叫shuffle:
Shuffle 的本意是扑克的“洗牌,打乱次序”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发。
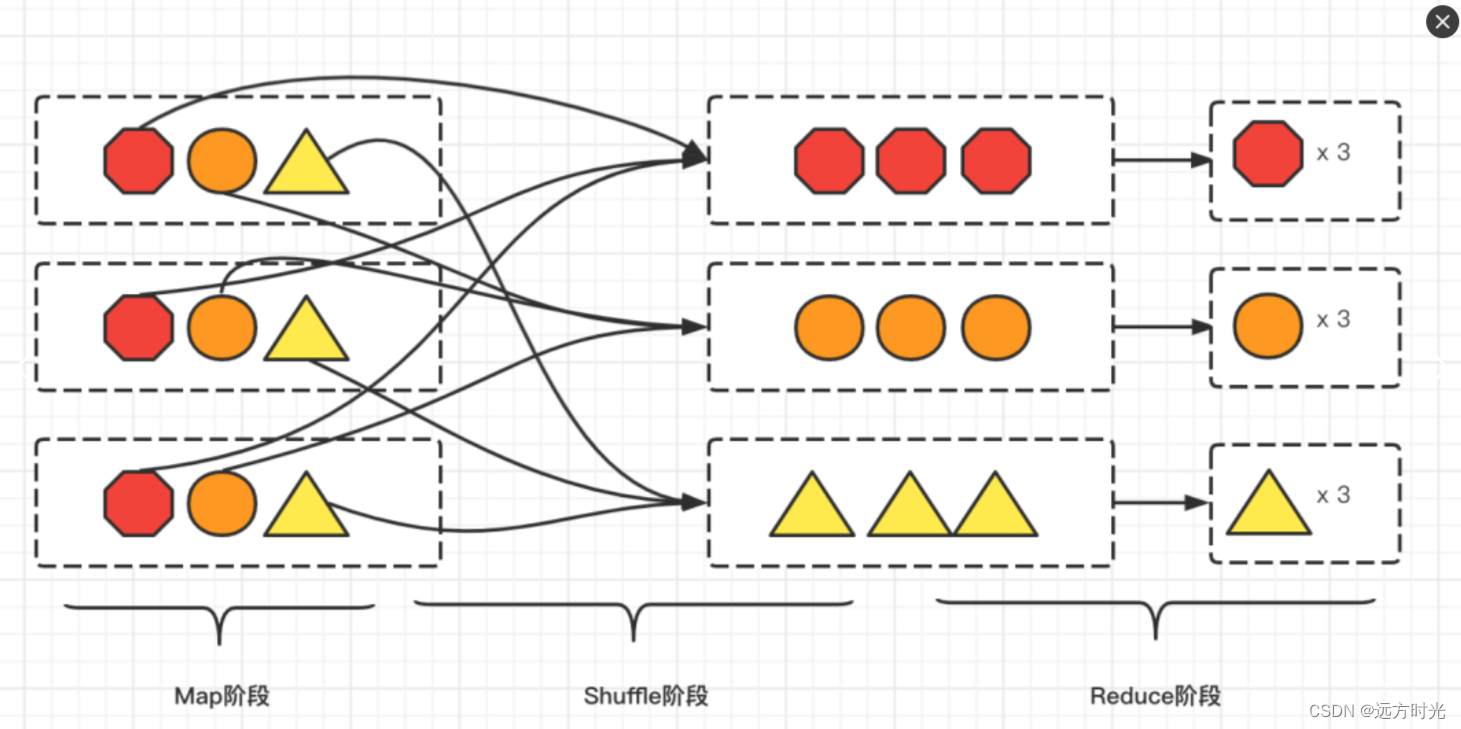 上图中在做形状分类时,集群会需要大量资源进行磁盘和网络的I/O。在DAG的计算链条中,Shuffle环节的执行性能往往是最差的。
上图中在做形状分类时,集群会需要大量资源进行磁盘和网络的I/O。在DAG的计算链条中,Shuffle环节的执行性能往往是最差的。
处理海量数据时候,通过分布式计算,使用多个节点帮我们处理海量数据,假如每个节点计算资源是均匀的,那我们希望分给每个节点的数据要尽量均匀。
数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,造成数据热点问题(数据倾斜的另一种说法),这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢(木桶效应)
----------------------------------------
Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂。
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低。Spark也会有自己的shuffle实现过程。
spark shuffle:
在 DAG 调度的过程中,Stage 阶段的划分是根据是否 有 shuffle 过程,也就是存在宽依赖的时候,需要进行 shuffle
hashshuffle:
未优化前:每一个上游ShufflleMapTask 根据下游 ReduceTask数量,产生对应多个的bucket内存,这个bucket存放的数据是经过Partition操作(默认是Hashpartition)之后找到对应的 bucket 然后放进去,bucket内存大小默认是32k,最后将bucket缓存的数据溢写到磁盘,即为对应的block file。接下来Reduce Task底层通过 BlockManager 将数据拉取过来。拉取过来的数据会组成一个内部的 ShuffleRDD,优先放入内存,内存不够用则放入磁盘。
问题是:小文件太多
优化后:每一个Executor建立一个buffer池,将不同task相同的key拉到相应的桶,大大减少了不同key的桶写人磁盘文件数量,shuffle阶段拉取到reduceTask的IO也就小了
sortshuffle:
在普通模式下,数据会先写入一个内存数据结构中,如果是由聚合操作的shuffle算子用map数据结构,如果是join算子就用Array数据结构。在写入的过程中如果达到了临界值,就会将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。在溢写磁盘之前,会先根据key对内存数据结构中的数据进行排序,排序好的数据,会以每批次1万条数据的形式分批写入磁盘文件。在task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写,会产生多个临时文件,最后会将之前所有的临时文件都进行合并,最后会合并成为一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件,最终再由下游的task根据索引文件读取相应的数据文件。
bypass的就是不排序,还是用hash去为key分磁盘文件,分完之后再合并,形成一个索引文件和一个合并后的key hash文件。省掉了排序的性能。
shuffle调优参数

我们来解决问题:
解决shuffle一般思路:
1.增加executor的内存spark.executor.memory
2.考虑用broadcast或者map join 进行规避shuffle的产生
3.在shuffle前进行过滤,减少shuffle的数据量
4.提高并行度
5.考虑是否有数据倾斜现象的产生
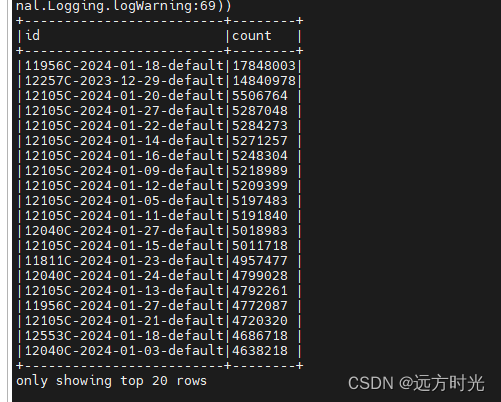
- 先说第5点,是否数据倾斜,我groubykey然后count然后sort(倒序),只有两个ID是大概3倍于其他ID,没有出现几十倍以上倾斜,所以我认为数据还算均匀
ps: 几十倍~几百倍那种倾斜的话,正常id的数据正常处理,异常id单独拎出来处理,加盐(id_随机数),再排序,再减盐(id_去除随机数),二阶段再排序,正常id数据和异常处理后的数据合并
- 第2点,广播变量
大表join小表,小表(<10M)默认是自动广播的

如果有什么变量需要被每一个executor共享使用再考虑使用广播变量,我这个排序场景不适用
- 第3点 减少shuffle的数据量,这个我也有考虑,原本key三列合并为一列(key: id_data_type),没有用到的列我也drop掉
- 最后说第1点增加executor的内存spark.executor.memory和第4点提高并行度是我们最需要考虑的,因为数据没有过于数据倾斜,最先想到的就是map(shuffle read)或者reduce(shuffle write)资源不足,大数据重要原则:自己能力不行,切记找兄弟,加节点 加节点内存,资源足够情况下可以解决绝大多数shuffle问题

图片中(memory拼错了...)
.config("spark.executor.instances", "10")
.config("spark.executor.cores", "10")
.config("spark.executor.memory", "16")升级完计算资源运行飞快
总结:
不是数据倾斜问题的话,优先考虑增加计算资源解决shuffle

















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









