







 文章介绍了在面临百万级设备数据存储和查询效率问题时,采用TDengine时序数据库进行优化。通过Java应用建立REST连接,展示了如何配置连接参数、插入和查询数据的代码示例,以及注意的时间区问题。此外,提到了TDengine的超级表和子表概念。
文章介绍了在面临百万级设备数据存储和查询效率问题时,采用TDengine时序数据库进行优化。通过Java应用建立REST连接,展示了如何配置连接参数、插入和查询数据的代码示例,以及注意的时间区问题。此外,提到了TDengine的超级表和子表概念。
最近学习了TDengine数据库,因为我们公司有硬件设备,设备按照每分钟,每十分钟,每小时上传数据,存入数据库。而这些数据会经过sql查询,统计返回展示到前端。但时间积累后现在数据达到了百万级数据,导致查询很慢,综合考虑下,决定使用这个时序数据库来存入数据。
关于TDengine详情,可去官网https://docs.taosdata.com/查看。具体理解超级表和子表。
接下来展示我的简单使用:
建入连接
有两种方式建入连接,一种是安装客户端驱动,一种是安装连接器,我这边使用的是安装连接器。
安装连接器,又有两种方式,一种是原声连接,一种是REST连接。两种连接端口不同(自行配置)。
我使用的REST连接:
首先导入依赖:
<dependency>
<groupId>com.taosdata.jdbc</groupId>
<artifactId>taos-jdbcdriver</artifactId>
<version>3.0.0</version>
</dependency>接下来是建入连接代码:
application.yml:
tdengine:
forward: false #是否启用该数据库开关
ip: 127.0.0.49 #tdengine服务ip
port: 8080
database: abc
user: root
password: 111111TdengineConfig.java
@Configuration
public class TdengineConfig {
public static String ip;
public static String port;
public static String database;
public static String user;
public static String password;
public static Boolean forward;
@Value("${tdengine.ip}")
public void setIp(String ip) {
TdengineConfig.ip = ip;
}
@Value("${tdengine.port}")
public void setPort(String port) {
TdengineConfig.port = port;
}
@Value("${tdengine.database}")
public void setDatabase(String database) {
TdengineConfig.database = database;
}
@Value("${tdengine.user}")
public void setUser(String user) {
TdengineConfig.user = user;
}
@Value("${tdengine.password}")
public void setPassword(String password) {
TdengineConfig.password = password;
}
@Value("${tdengine.forward}")
public void setForward(Boolean forward) {
TdengineConfig.forward = forward;
}
}TdengineConnectConfig.java
@Component
public class TdengineConnectConfig {
//8030原生连接端口 8041
public static Connection conn = null;
public static String URL = TdengineConfig.ip + ":" + TdengineConfig.port + "/" + TdengineConfig.database;
@PostConstruct
public static Connection getConnection(){
if(!TdengineConfig.forward) return null;
try{
System.out.println("---------------start Connected");
String jdbcUrl = "jdbc:TAOS-RS://"+ URL +"?user="+ TdengineConfig.user +"&password=" + TdengineConfig.password;
Properties connProps = new Properties();
//connProps.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_LOAD, "true"); //开启批量拉取功能
conn = DriverManager.getConnection(jdbcUrl, connProps);
System.out.println("---------------Connected success");
}catch (Exception e){
System.out.println("---------------Connected fail");
e.printStackTrace();
}
return conn;
}
}操作数据,拼接-执行sql
1.新增数据sql拼接:
//拼接sql sql初始化--sql=insert into""
public void inserDdengingDatabase(StringBuffer sql, FactorBean factorBean, FactorEntity factorEntity, String mnNumber, Date insertDate, String cnNumber){
try{
DengineFactorBean dfb = new DengineFactorBean(factorBean);
dfb.setInsertDate(insertDate);
dfb.setMn(mnNumber);
dfb.setFactor_name(factorEntity.getPfName());
dfb.setFactor_code(factorEntity.getPfCode());
dfb.setFactor_unit(factorEntity.getPfUnitMic());
//D_[mn]_[2011/2051/...]_[factor_code]
String stable = " USING data_" + cnNumber;
String table = " D_" + mnNumber + "_" + cnNumber + "_" + factorEntity.getPfCode();
//表名不支持"-"符号
table = table.replace("-","__");
sql.append( "\n" + table + stable + dfb.toString());
}catch (Exception e){
System.out.println("-------------拼接sql失败");
e.printStackTrace();
}
}
//执行sql
public static void executeSql(String sql){
try{
if(conn == null) conn = getConnection();
if(conn != null){
Statement statement = conn.createStatement();
statement.execute(sql);
}
}catch (Exception e){
System.out.println("sql执行失败");
e.printStackTrace();
}
}
注:超级表需要提前建好,子表可以通过sql新建,子表的名称可以通过代码动态拼接。表名中如果含有大写会自动转为小写,不能带有“-”符号,可以使用“_”。
具体语法可以去看官网。给你们展示一下写入数据的sql:
--------执行sql:INSERT INTO
D_LE202012210190_2011_a24088 USING data_2011 TAGS ('LE202012210190','a24088','非甲烷总烃','mg/m³') VALUES (1675844844000,0.011,null,null,null,null)
D_LE202012210190_2011_a34001 USING data_2011 TAGS ('LE202012210190','a34001','总悬浮颗粒物TSP','mg/m³') VALUES (1675844844000,0.132,null,null,null,null)
D_LE202012210190_2011_a01012 USING data_2011 TAGS ('LE202012210190','a01012','烟气温度','°C') VALUES (1675844844000,14.9,null,null,null,null)
D_LE202012210190_2011_GGY03 USING data_2011 TAGS ('LE202012210190','GGY03','油烟浓度','mg/m³') VALUES (1675844844000,0.028,null,null,null,null);再展示一下数据库界面(下图中有新建好的子表):
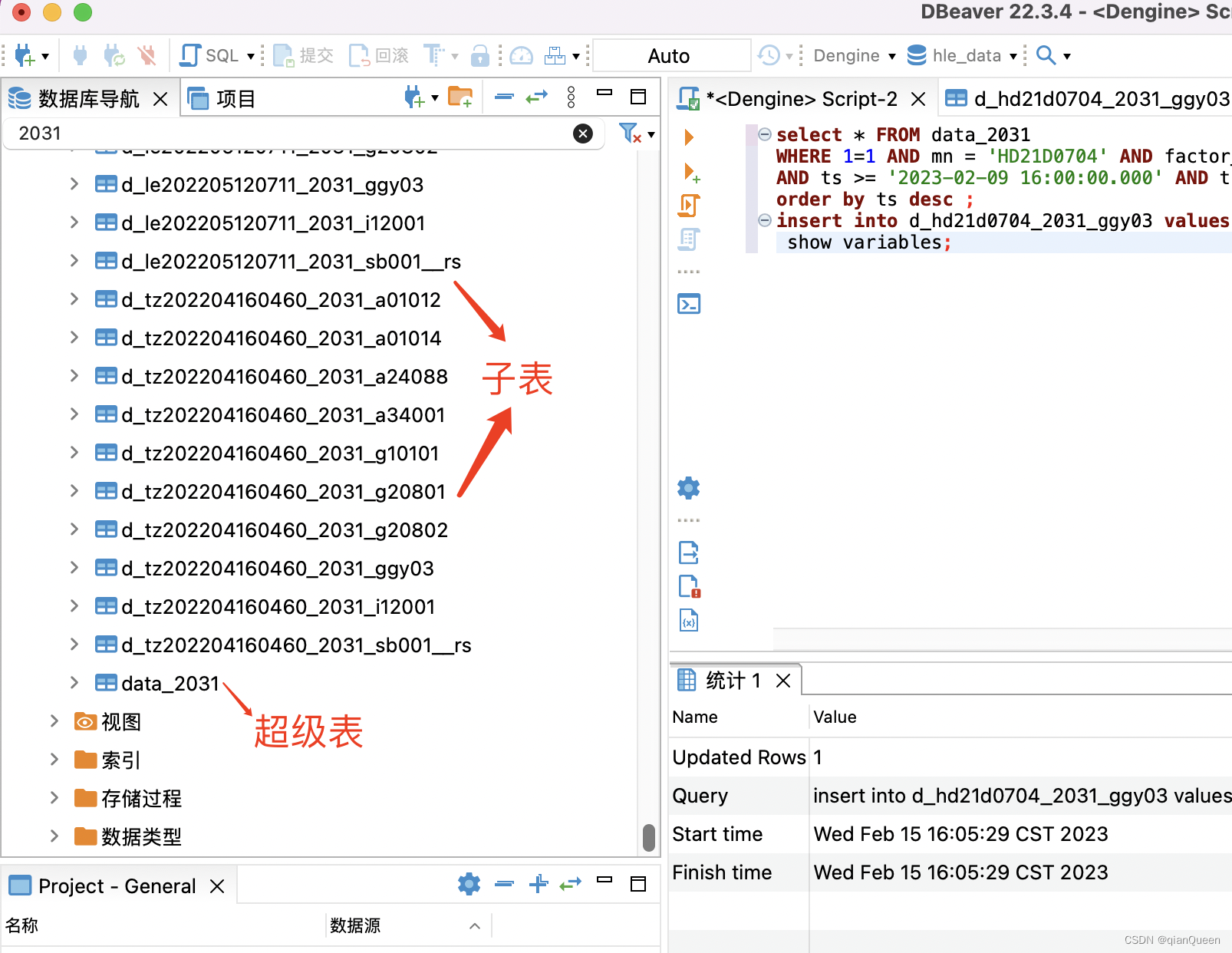
2.查询数据sql拼接,转换ResultSet:
//执行查询sql
public static ResultSet executeQuerySql(String sql){
try{
if(conn == null) conn = getConnection();
if(conn != null){
Statement statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
return rs;
}
}catch (Exception e){
System.out.println("sql执行失败");
e.printStackTrace();
}
return null;
}
/**
* 转换为list(多行值)
* @param rs
* @throws SQLException
*/
public static List<Map> changeResult(ResultSet rs, Integer dateType, Integer factorId) {
try{
if(rs!=null){
List<Map> list = new ArrayList<>();
while (rs.next()) {
Map data = new HashMap();
ResultSetMetaData meta = rs.getMetaData();
for (int i = 1; i <= meta.getColumnCount(); i++) {
data.put(colName, rs.getObject(i));
}
list.add(data);
}
return list;
}
}catch (Exception e){
e.printStackTrace();
}
return null;
}
/**
* 转换为list(单行值)
* @param rs
* @throws SQLException
*/
public static Map changeOneResult(ResultSet rs) {
try{
Map data = new HashMap();
if(rs!=null){
while (rs.next()) {
ResultSetMetaData meta = rs.getMetaData();
for (int i = 1; i <= meta.getColumnCount(); i++) {
data.put(meta.getColumnName(i), rs.getObject(i));
}
}
}
return data;
}catch (Exception e){
e.printStackTrace();
}
return null;
}
/**
* 打印行值
* @param rs
* @throws SQLException
*/
private static void printRow(ResultSet rs) throws SQLException {
ResultSetMetaData meta = rs.getMetaData();
System.out.println(meta.getColumnCount());
for (int i = 1; i <= meta.getColumnCount(); i++) {
String value = rs.getString(i);
System.out.print(value);
System.out.print("\t");
}
System.out.println();
}
/**
* 打印列名
* @param rs
* @throws SQLException
*/
private static void printColName(ResultSet rs) throws SQLException {
ResultSetMetaData meta = rs.getMetaData();
for (int i = 1; i <= meta.getColumnCount(); i++) {
String colLabel = meta.getColumnLabel(i);
System.out.print(colLabel);
System.out.print("\t");
}
System.out.println();
}
public static String sqlSplice(Integer dataType, String factoryCode, String mn, String startDate, String endDate){
//写sql 查询超级表数据
String stable = "data_"+dataType;
String sql= "select * FROM " +
stable +
" WHERE 1=1" + //不能用true
(StringUtils.isEmpty(mn) ? "":" AND mn = '" + mn + "'") +
(StringUtils.isEmpty(factoryCode) ? "":" AND factor_code = '" + factoryCode + "'") +
(StringUtils.isEmpty(startDate) ? "":" AND ts >= '" + startDate + "'") +
(StringUtils.isEmpty(endDate) ? "":" AND ts <= '" + endDate+ "'") +
" order by ts desc ";
return sql;
}
public static String countSqlSplice(Integer dataType, String factoryCode, String mn, String startDate, String endDate){
//写sql
String stable = "data_"+dataType;
String sql= "select count(ts) as c1 FROM " +
stable +
" WHERE 1=1" +
(StringUtils.isEmpty(mn) ? "":" AND mn = '" + mn + "'") +
(StringUtils.isEmpty(factoryCode) ? "":" AND factor_code = '" + factoryCode + "'") +
(StringUtils.isEmpty(startDate) ? "":" AND ts >= '" + startDate + "'") +
(StringUtils.isEmpty(endDate) ? "":" AND ts <= '" + endDate+ "'") ;
return sql;
}使用查询发现一个时区问题,项目在本地运行时查询和插入数据,时间多了八个小时,但是在服务器上运行时插入的数据时间是正确的,但我在我电脑上查询数据库当前时间是也是对的,可能是在插入和查询数数据操作数据库时,时间会自动+8小时...这个问题注意一下哦~
修改和删除因为项目暂时不需要,就不写了。哈哈哈哈这就是我的简单使用,更多的自行去官网看看哦~

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









