







 本文介绍了无监督学习中的K均值聚类算法,详细阐述了算法思想、实现过程和可能遇到的问题。针对K均值算法的局限,讨论了使用后处理优化聚类性能和二分K均值算法来改善局部最小值问题。通过实例展示了算法的应用,并对比了不同算法的效果。
本文介绍了无监督学习中的K均值聚类算法,详细阐述了算法思想、实现过程和可能遇到的问题。针对K均值算法的局限,讨论了使用后处理优化聚类性能和二分K均值算法来改善局部最小值问题。通过实例展示了算法的应用,并对比了不同算法的效果。
1 简介
我们之前接触的所有机器学习算法都有一个共同特点,那就是分类器会接受2个向量:一个是训练样本的特征向量X,一个是样本实际所属的类型向量Y。由于训练数据必须指定其真实分类结果,因此这种机器学习统称为有监督学习
然而有时候,我们只有训练样本的特征,而对其类型一无所知。这种情况,我们只能让算法尝试在训练数据中寻找其内部的结构,试图将其类别挖掘出来。这种方式叫做无监督学习。由于这种方式通常是将样本中相似的样本聚集在一起,所以又叫聚类算法
下面我们介绍一个最常用的聚类算法:K均值聚类算法(K-Means)
2 算法
K均值算法的思想大致如下:
1:初始化K个样本作为初始聚类中心
2:计算每个样本点到K个中心的距离,选择最近的中心作为其分类,直到所有样本点分类完毕
3:分别计算K个类中所有样本的质心,作为新的中心点,完成一轮迭代。
通常的迭代结束条件为新的质心与之前的质心偏移值小于一个给定阈值。
这里我们给出算法的代码实现
from numpy import *
#计算两点间距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
#随机生成K个初始点
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
#K均值算法主体
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
#图形可视化
import matplotlib
import matplotlib.pyplot as plt
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s', 'o', '^', '8', 'p', 'd', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0=fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png')
ax0.imshow(imgP)
ax1=fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:,0].A==i)[0],:]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0], ptsInCurrCluster[:,1].flatten().A[0], marker=markerStyle, s=90)
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
在算法中,相似度的计算方法默认的是欧氏距离计算,当然也可以使用其他相似度计算函数,比如余弦距离;算法中,k个类的初始化方式为随机初始化,并且初始化的质心必须在整个数据集的边界之内,这可以通过找到数据集每一维的最大值和最小值;然后最小值取值范围0到1的随机数,来确保随机点在数据边界之内
这里我们可以看一个给出的例子:
#文件导入函数
def loadDataSet(fileName):
dataSet = []
f = open(fileName)
for line in f.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataSet.append(fltLine)
return mat(dataSet)
#
datMat = mat(kMeans.loadDataSet('testSet.txt'))
myCentroids, clustAssing = kMeans.kMeans(datMat,4)
效果如图:

可以看到,经过3次迭代后K均值算法收敛,并得出了4个质心。
看起来,现在关于聚类的进展都很顺利,然而实际上并非完全如此,下面我们将讨论算法可能出现的问题。
3 算法改进
3.1 使用后处理提高聚类性能

有时候当我们观察聚类的结果图时,发现聚类的效果没有那么好,如上图所示,K-means算法在k值选取为3时的聚类结果,我们发现,算法能够收敛但效果较差。显然,这种情况的原因是,算法收敛到了局部最小值,而并不是全局最小值,局部最小值显然没有全局最小值的结果好。
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和)。SSE的值越小表示数据点越接近于他们的质心,聚类的效果也越好。因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低SSE值的方法是增加簇的个数,但这违背了聚类的目标,聚类的目标是在保持簇数目不变的情况下提高簇的质量。
可行的方法是对生成的簇进行后处理,一种方法是我们可以将具有最大SSE值得簇划分为两个簇。具体地,可以将最大簇包含的点过滤出来并在这些点上运行K-means算法,其中k设为2,同时,当把最大的簇(上图中的下半部分)分为两个簇之后,为了保证簇的数目是不变的,我们可以再合并两个簇。具体地:
一方面我们可以合并两个最近的质心所对应的簇,即计算所有质心之间的距离,合并质心距离最近的两个质心所对应的簇。
另一方面,我们可以合并两个使得SSE增幅最小的簇,显然,合并两个簇之后SSE的值会有所上升,那么为了最好的聚类效果,应该尽可能使总的SSE值小,所以就选择合并两个簇后SSE涨幅最小的簇。具体地,就是计算合并任意两个簇之后的总得SSE,选取合并后最小的SSE对应的两个簇进行合并。这样,就可以满足簇的数目不变。
3.2 二分K均值算法
为了克服K均值算法收敛于局部最小值的问题,有人提出了两一个成为二分K均值的算法。二分K-means算法首先将所有点作为一个簇,然后将簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇取决于对其进行划分是否能够最大程度的降低SSE的值。上述划分过程不断重复,直至划分的簇的数目达到用户指定的值为止。
二分K均值算法的伪代码形式如下:
将所有点看成一个簇
当簇数目小于k时
对于每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二之后的总误差
选择使得总误差最小的簇进行划分
当然,选取时也可以选择SSE最大的簇进行划分,直到簇的目标达到用户指定的数目为止。代码实现如下:
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0]
for j in range(m):
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList)
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss
return mat(centList), clusterAssment
在上述算法中,直到簇的数目达到k值,算法才会停止。在算法中通过将所有的簇进行划分,然后分别计算划分后所有簇的误差。选择使得总误差最小的那个簇进行划分。划分完成后,要更新簇的质心列表,数据点的分类结果及误差平方。具体地,假设划分的簇为m(m
4 应用
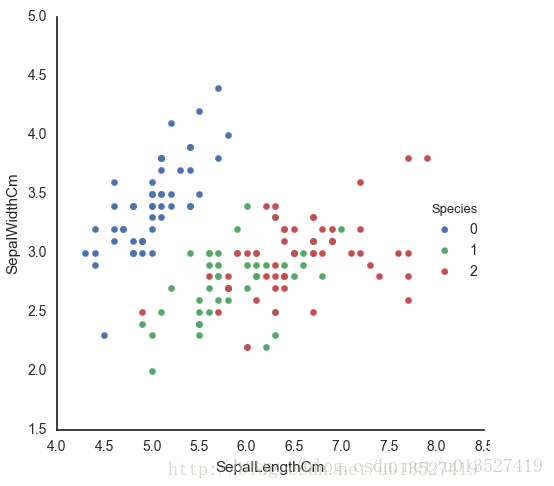
我把K均值算法应用到IRIS上,经过12次迭代,得到的分类结果为:
[[5.006 3.418 1.464 0.244 ]
[5.88360656 2.74098361 4.38852459 1.43442623]
[6.85384615 3.07692308 5.71538462 2.05384615]]
把分类结果与原数据的标签进行比对,结果如下:
| 序号 | 错误数目(个) |
| 1-50(Iris-setosa) | 0 |
| 51-100(Iris-versicolor) | 3 |
| 101-150(Iris-virginica) | 14 |
考虑到数据的分布,如下图,这样的结果是可以理解的。
5 结论
1 聚类是一种无监督的学习方法。聚类区别于分类,即事先不知道要寻找的内容,没有预先设定好的目标变量。
2 聚类将数据点归到多个簇中,其中相似的数据点归为同一簇,而不相似的点归为不同的簇。相似度的计算方法有很多,具体的应用选择合适的相似度计算方法。
3 K-means聚类算法,是一种广泛使用的聚类算法,其中k是需要指定的参数,即需要创建的簇的数目,K-means算法中的k个簇的质心可以通过随机的方式获得,但是这些点需要位于数据范围内。在算法中,计算每个点到质心得距离,选择距离最小的质心对应的簇作为该数据点的划分,然后再基于该分配过程后更新簇的质心。重复上述过程,直至各个簇的质心不再变化为止。
4 K-means算法虽然有效,但是容易受到初始簇质心的情况而影响,有可能陷入局部最优解。为了解决这个问题,可以使用另外一种称为二分K-means的聚类算法。二分K-means算法首先将所有数据点分为一个簇;然后使用K-means(k=2)对其进行划分;下一次迭代时,选择使得SSE下降程度最大的簇进行划分;重复该过程,直至簇的个数达到指定的数目为止。实验表明,二分K-means算法的聚类效果要好于普通的K-means聚类算法。

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









