






使用AI4J快速接入RAG应用 | 结合Pinecone实现法律AI助手RAG应用
本博文给大家介绍一下如何使用AI4J快速接入OpenAI大模型,并且结合Pinecone向量数据库实现一个刑法AI助手的RAG应用。
介绍
由于SpringAI需要使用JDK17和Spring Boot3,但是目前很多应用依旧使用的JDK8版本,所以使用可以支持JDK8的AI4J来接入OpenAI大模型。
AI4J是一款JavaSDK用于快速接入AI大模型应用,整合多平台大模型,如OpenAi、Ollama、智谱Zhipu(ChatGLM)、深度求索DeepSeek、月之暗面Moonshot(Kimi)、腾讯混元Hunyuan、零一万物(01)等等,提供统一的输入输出(对齐OpenAi)消除差异化,优化函数调用(Tool Call),优化RAG调用、支持向量数据库(Pinecone),并且支持JDK1.8,为用户提供快速整合AI的能力。
Pinecone
Pinecone向量数据库是一个云原生的向量数据库,具有简单的API和无需基础架构的优势。它可以快速处理数十亿条向量数据,并实时更新索引。同时,它还可以与元数据过滤器相结合,以获得更相关、更快速的结果。
Pinecone是完全云托管的,容易上手、扩展轻松,用户可以放心使用。
注册与使用
大家可以进入Pinecone官网进行注册和登录,至于注册账号,这里不在演示,相信大家都会。
选择Database->Indexes->Create Index来创建索引
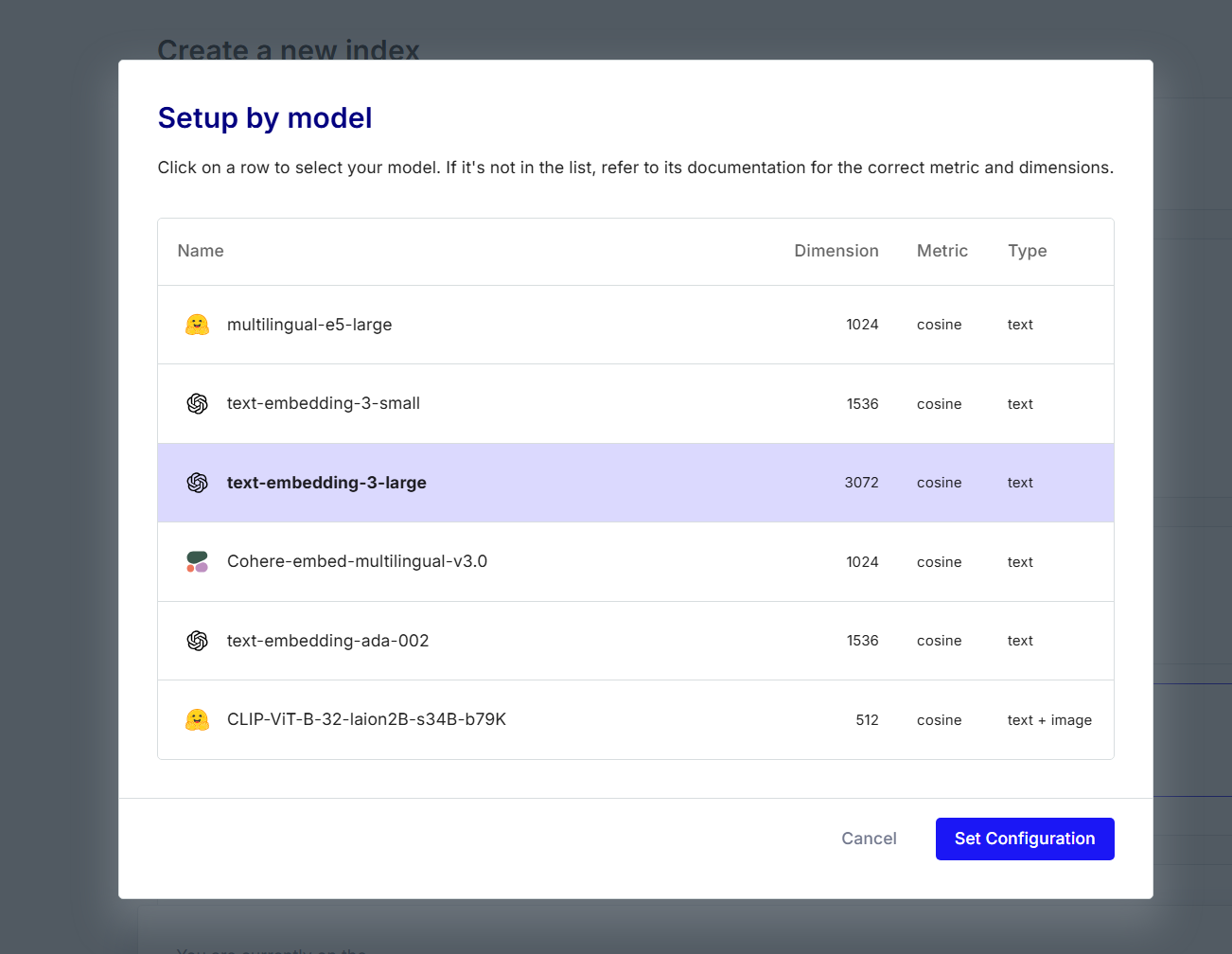
在这里可以输入你的维度,或者点击Setup by model,根据模型来选择向量维度。这里我以text-embedding-3-large模型为例子
创建完成后,记录自己的Host,我们后面要用到
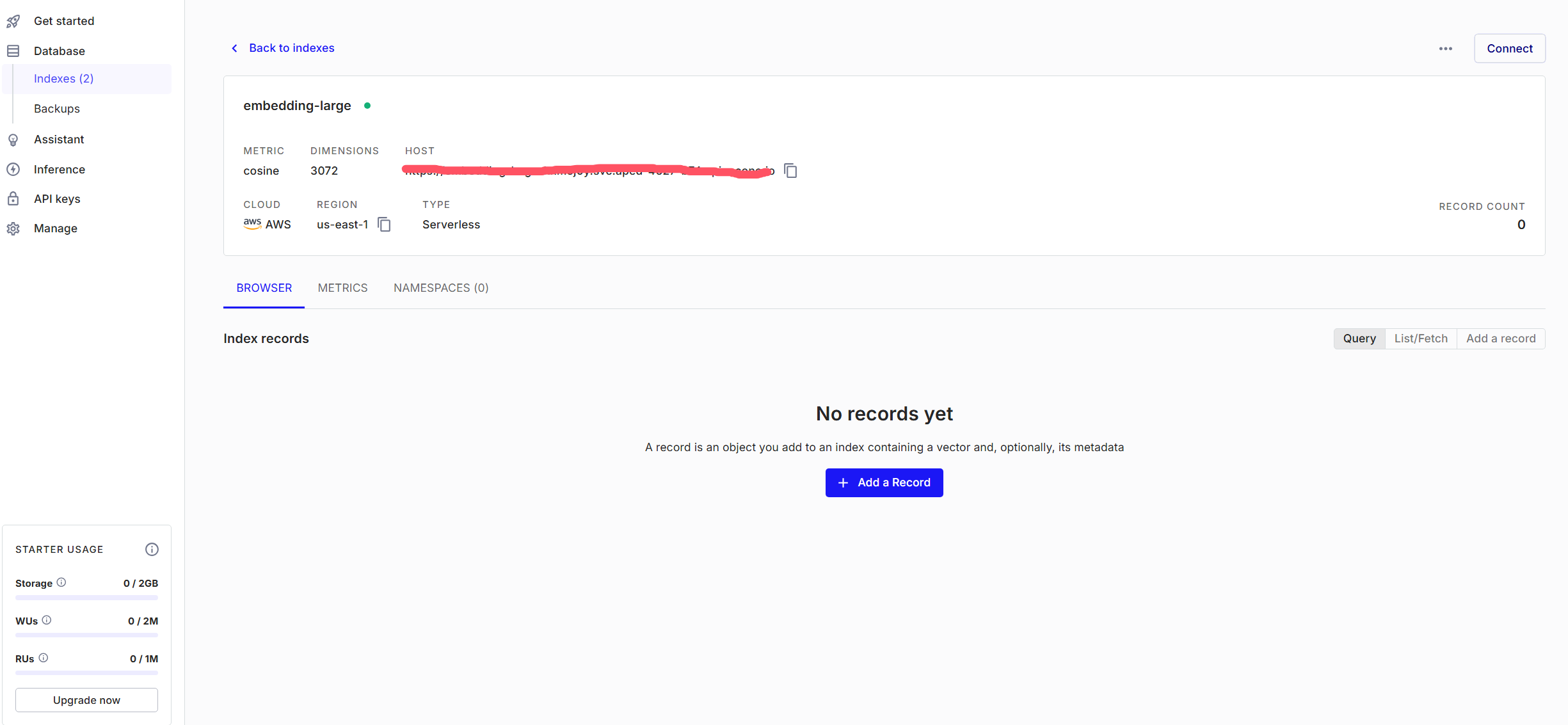
创建自己的API Key

快速使用
之前已经为大家提供了两篇文档,可供大家参考:
引入AI4J依赖
<!-- Spring应用 -->
<dependency>
<groupId>io.github.lnyo-cly</groupId>
<artifactId>ai4j-spring-boot-stater</artifactId>
<version>0.6.3</version>
</dependency>
注意版本,尽量选择最新的版本。0.6.3之前的版本对RAG的实现有一些bug
如果你使用阿里源无法引入,可能是阿里云镜像还没有同步。
配置application.yml
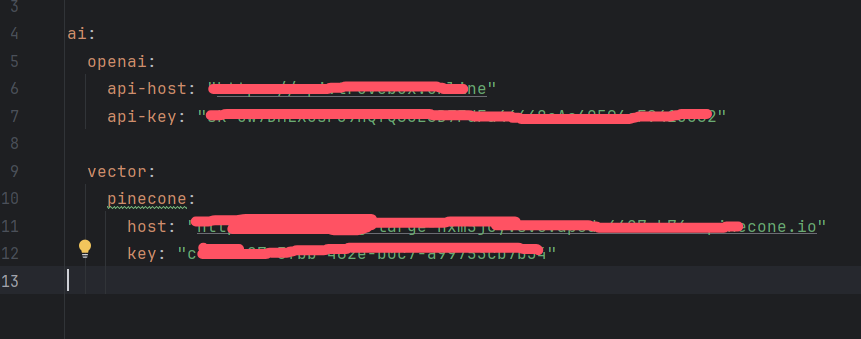
注意:
你需要填写上文Pinecone提供的Host和API Key。
由于目前版本的AI4J只实现了OpenAi的Embedding服务,所以这里也需要配置OpenAi的信息。
Chat服务可以使用OpenAi的也可以使用其它的平台如Ollama、Zhipu等等。
如果没有OpenAi的官方key,大家可以使用中转API
[低价中转平台] 低价ApiKey
搭建RAG服务Test类
这里以一个简单的Test类来演示,大家可以比葫芦画瓢自己搭建Controller。
建立RAG知识库
既然要建立RAG应用,那肯定少不了知识库。
本文搭建的是一个简单的法律AI助手,所以我们需要一个法律知识库。
接下来我以刑法知识库为例为大家讲解
可以将所需要的知识库,存入一个文本文档当中:

存储至Pinecone向量数据库中
@SpringBootTest
public class RagTest {
// 1. 注入Pinecone服务
@Autowired
private PineconeService pineconeService;
// 2. 注入AI服务
@Autowired
private AiService aiService;
@Test
public void test_rag_store() throws Exception {
// 3. 获取Embedding服务
IEmbeddingService embeddingService = aiService.getEmbeddingService(PlatformType.OPENAI);
// 4. Tika读取file文件内容
String fileContent = TikaUtil.parseFile(new File("D:\\data\\test.txt"));
System.out.println(fileContent);
// 5. 分割文本内容
RecursiveCharacterTextSplitter recursiveCharacterTextSplitter = new RecursiveCharacterTextSplitter(1000, 200);
List<String> contentList = recursiveCharacterTextSplitter.splitText(fileContent);
System.out.println(contentList.size());
// 6. 转为向量
Embedding build = Embedding.builder()
.input(contentList)
.model("text-embedding-3-large")
.build();
EmbeddingResponse embedding = embeddingService.embedding(build);
List<List<Float>> vectors = embedding.getData().stream().map(EmbeddingObject::getEmbedding).collect(Collectors.toList());
VertorDataEntity vertorDataEntity = new VertorDataEntity();
vertorDataEntity.setVector(vectors);
vertorDataEntity.setContent(contentList);
System.out.println(vertorDataEntity);
// 7. 向量存储至pinecone
Integer count = pineconeService.insert(vertorDataEntity, "abc-123-abc");
System.out.println(count > 0 ? "存储成功" : "存储失败");
}
}
下图是插入成功的数据
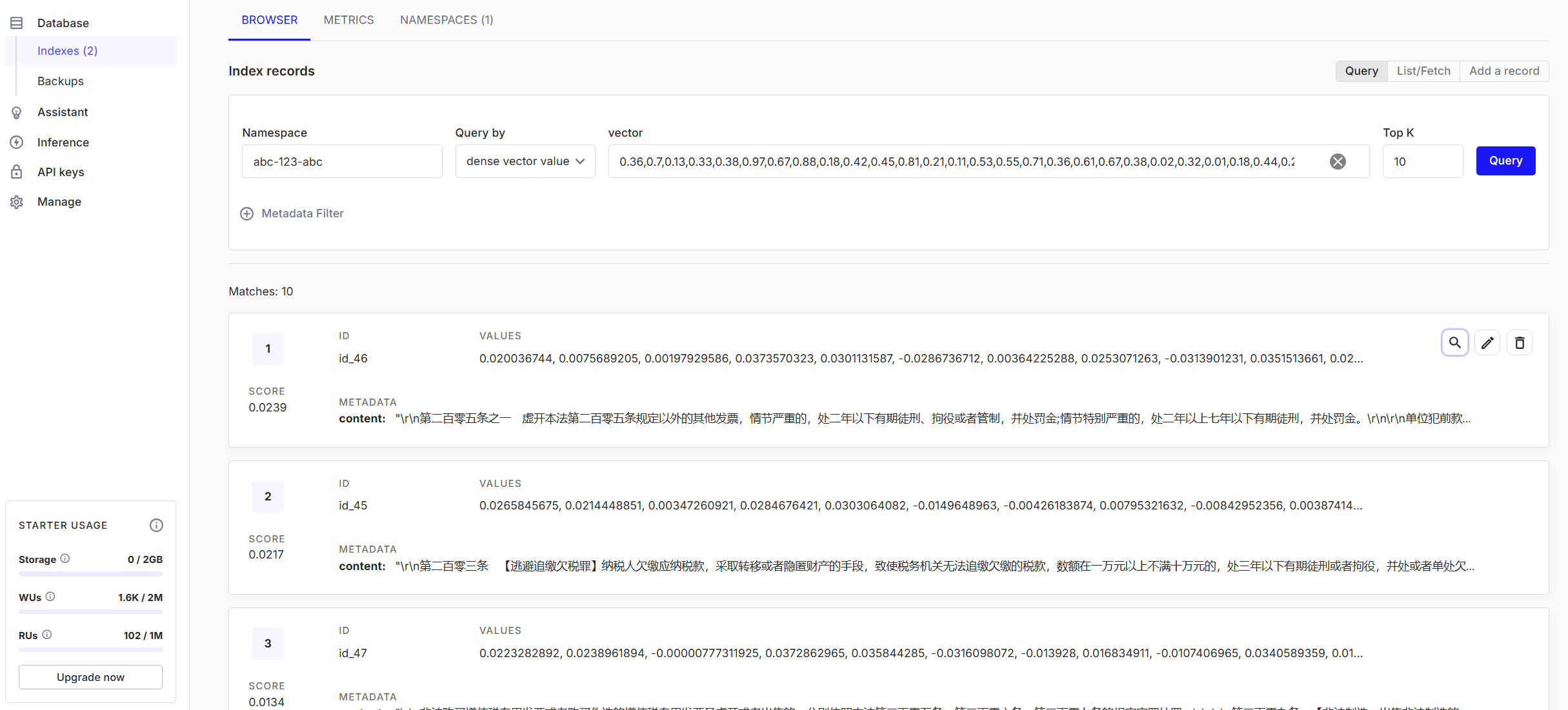
RAG查询
@Test
public void test_rag_query() throws Exception {
// 8. 获取Embedding服务
IEmbeddingService embeddingService = aiService.getEmbeddingService(PlatformType.OPENAI);
// 9. 构建要查询的问题,转为向量
String question = "如何挑选最甜的西瓜?";
Embedding build = Embedding.builder()
.input(question)
.model("text-embedding-3-large")
.build();
EmbeddingResponse embedding = embeddingService.embedding(build);
List<Float> questionEmbedding = embedding.getData().get(0).getEmbedding();
// 10. 构建向量数据库的查询对象
PineconeQuery pineconeQueryReq = PineconeQuery.builder()
.namespace("abc-123-abc")
.topK(5)
.vector(questionEmbedding)
.build();
// 11. 查询
// PineconeQueryResponse queryResponse = pineconeService.query(pineconeQueryReq);
// delimiter为想用什么字符拼接查询出来的内容
String retrievalContent = pineconeService.query(pineconeQueryReq, " ");
String contentFormat = "你是一个善于回答中华人民共和国刑法相关问题的助手。请使用以下提供的检索内容和自身知识来回答问题。如果你不知道答案,请直接说不知道,不要杜撰答案。请用三句话以内回答,保持简洁。\n" +
"\n" +
"问题:%s\n" +
"\n" +
"检索内容:%s";
String content = String.format(contentFormat, question, retrievalContent);
// 12. 获取Chat服务
IChatService chatService = aiService.getChatService(PlatformType.OPENAI);
// 13. 构建Chat请求
ChatCompletion chatCompletion = ChatCompletion.builder()
.model("gpt-4o")
.message(ChatMessage.withUser(content))
.build();
// 14. 发送Chat请求
ChatCompletionResponse chatCompletionResponse = chatService.chatCompletion(chatCompletion);
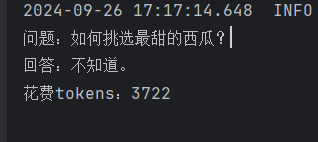
System.out.println("问题:" + question);
System.out.println("回答:" + chatCompletionResponse.getChoices().get(0).getMessage().getContent());
System.out.println("花费tokens:" + chatCompletionResponse.getUsage().getTotalTokens());
}
下图是测试的结果:

至此我们已经完成了一个RAG应用的搭建,大家可以根据自己的需求搭建自己的RAG应用。

















 2264
2264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









