




最近阅读几篇 distillation-adapter论文,要求掌握理解算法,和大家分享一下:第一篇是huggingface的adpater代码库中的位置,其中详细讲解了在transformer中加入adapter层和adapterfusion层,第二篇论文在adpater代码库中的位置中也可以找到,主要是将已经训练好的multilingual模型移到另外一种语言上,模型由三部分组成language, task, and invertible adapters组成,第三篇是使用CONTRASTIVE LEARNING来进行distillation的学习。
文章目录
1. AdapterFusion: Non-Destructive Task Composition for Transfer Learning
解决问题:解决pre-train模型的在多domain上的catastrophic forgetting和dataset balancing的问题。
related work:目前主流的pre-train模型的方法有三个:
- fine-tuning:对于n个任务,在每一步训练一个任务模型的时候要初始化一个层,通过学习这个层的结构来学习参数,但是这种方法在超过两种task下就会出现灾难性遗忘的问题。
- Multi-Task Learning (MTL):所有task都同步学习,来学习一个大的结构可以表示所有的模型。这种方法在大量困难任务的学习时loss的设计是一个大问题。
- adapter:分为Single-Task Adapters (ST-A)、Multi-Task Adapters (MT-A)。本文提出,可以解决上述的两个问题。
adapter的方法: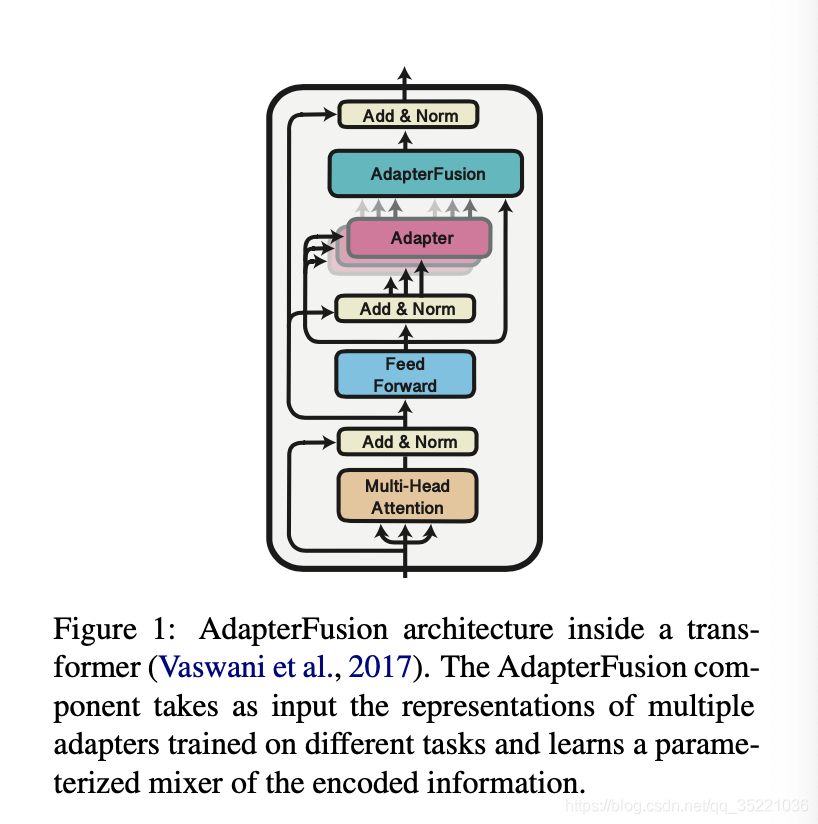
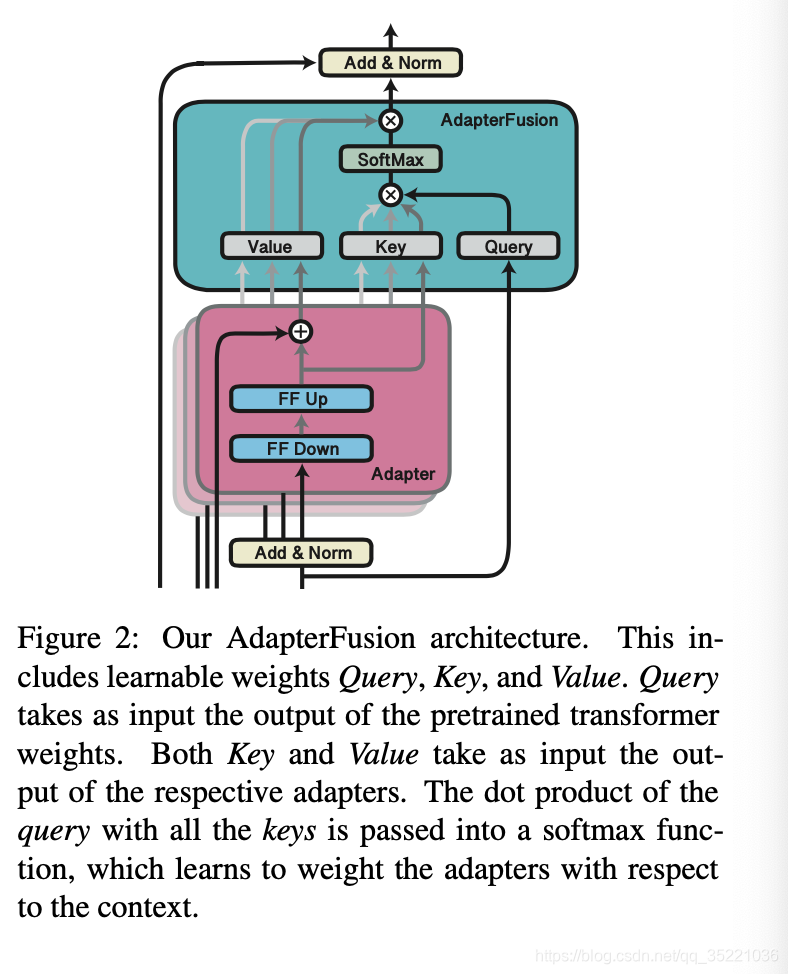
方法:主要分成两个部分adapter部分和adapterfusion
- adapter:In the first stage of our learning algorithm, we train either ST-A or MT-A for each of the N tasks.
- adapterfusion:In the second stage, we then combine the set of N adapters by using AdapterFusion. While fixing both the parameters Θ as well as all adapters Φ, we introduce parameters Ψ that learn to combine the N task adapters to solve the target task.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









