 BERT详解
BERT详解




 本文详细介绍了BERT模型,包括其网络结构、输入表示方式、预训练过程及如何进行微调应用于下游任务等。并提供了训练技巧和实践指导。
本文详细介绍了BERT模型,包括其网络结构、输入表示方式、预训练过程及如何进行微调应用于下游任务等。并提供了训练技巧和实践指导。
该论文是谷歌提出BERT时的原论文,在distill的时候感觉对于该模型的理解不够,所以再次对于该论文进行了阅读,希望有更好的理解。
BERT所提供的是一种预训练模型,所谓预训练模型可以理解为一个特征抽取器,在使用的时候就将这些预训练模型用到对应的数据集上进行fintune,具体理解可参考。
1. BERT的网络结构
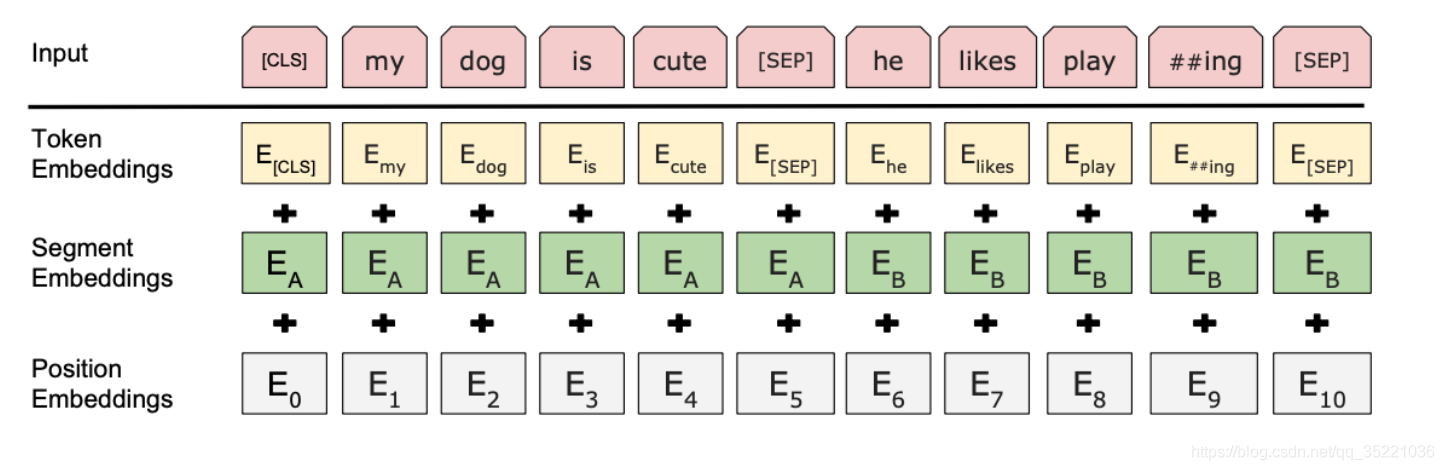
2. BERT的输入表示
BERT允许输入的字符的最大长度为512,由3部分组成:
-
Token embedding: 根据词表将句子中的单词划分成每一个很小的单元
-
Position embedding:表示每个单词的位置
-
Segment embedding:用于区分不同的句子(可以用于判断B是否是A的下文),对于句子对,第一个句子对特征值是0,第二个句子的特征值是1。
还有两个特殊符号:[CLS] 和 [SEP] , [CLS] 表示该特征用于分类模型,对非分类模型,该符合可以省去。 [SEP] 表示分句符号,用于断开输入语料中的两个句子
3. BERT模型的训练过程
BERT主要通过两个步骤训练而成:Masked Language Model(MLM) ; Next Sentence Prediction(NSP)
3.1 Masked Language Model(MLM)
MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词。在bert中Token中的15%的词都会被随机的mask掉,对于这15%的单词也分为3中不同的情况:0%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的 时候会保留原始Token。
• 80%: my dog is hairy -> my dog is [mask]
• 10%: my dog is hairy -> my dog is apple
• 10%: my dog is hairy -> my dog is hairy
这么做的原因是如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就 会有一些没有⻅过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的 分布式表征,否则模型就会记住这个[mask]是token ’hairy‘。至于单词带来的负面影响,因为一 个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
3.2 Next Sentence Prediction(NSP )
NSP用于判断Segment中的句子B是否是A的下文。
如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话, 其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
4. finetine
2021年8月12日补充:这两天思考的时候发现对于finetune的部分还是有点不透彻,所以写清楚一点
在训练好的预训练模型上,加上少量的task-specific 参数,例如对于分类问题就加上一层softmax,然后在新的网络里面进行finetune。
关于选取BERT的最后几层的hidden_state做的实验

通过步骤三的训练过程,我们可以将他运用到NLP的各个下游任务上了,大部分的任务只需要在BERT的基础上再添加一个输出层便可以完成对特定任务的finetine。
5. 评测
这里我们可以使用huggingface封装好的指标进行实验,可以检验的内容:语言模型、语言生成、GLUE、SQuAD、多项选择、命名实体识别、XNLI、模型性能的对抗性评估。
笔者这里习惯使用huggingface封装好的包直接进行评测,教程。

















 2416
2416




 到【灌水乐园】发言
到【灌水乐园】发言







