




 本文介绍如何使用Python将TXT格式数据转换为CSV格式,并利用TensorFlow读取CSV数据进行处理。通过具体代码示例,展示了数据转换流程及TensorFlow数据读取方法。
本文介绍如何使用Python将TXT格式数据转换为CSV格式,并利用TensorFlow读取CSV数据进行处理。通过具体代码示例,展示了数据转换流程及TensorFlow数据读取方法。
环境:python3.5 tensorflow1.12
数据:
6.1101,17.592
5.5277,9.1302
8.5186,13.662
7.0032,11.854
5.8598,6.8233
8.3829,11.886
7.4764,4.3483
txt转换为csv格式
import csv
#要保存后csv格式的文件名
file_name_string="file.csv"
with open(file_name_string, 'w', newLine='') as csvfile:
#编码风格,默认为excel方式,也就是逗号(,)分隔
spamwriter = csv.writer(csvfile, dialect='excel')
# 读取txt文件,每行按逗号分割提取数据
with open('ex1data1.txt', 'rb') as file_txt:
for line in file_txt:
line_datas= str(line, encoding='utf-8').strip('\n').split(',')
spamwriter.writerow(line_datas)
得到file.csv文件,其中ex1data1.txt为原数据,file.csv为转化后的csv数据
读取csv格式数据:
import tensorflow as tf
import os
import csv
#要保存后csv格式的文件名
file_name_string="file.csv"
filename_queue = tf.train.string_input_producer([file_name_string])
#每次一行
reader = tf.TextLineReader()
key,value = reader.read(filename_queue)
record_defaults = [[1.0], [1.0]] # 这里的数据类型决定了读取的数据类型,而且必须是list形式
col1, col2 = tf.decode_csv(value, record_defaults=record_defaults) # 解析出的每一个属性都是rank为0的标量
with tf.Session() as sess:
#线程协调器
coord = tf.train.Coordinator()
#启动线程
threads = tf.train.start_queue_runners(coord=coord)
is_second_read=0
line1_name='%s:1' % file_name_string
print(line1_name)
while True:
#x_第一个数据,y_第二个数据,dline_key中保存当前读取的行号
x_, y_,line_key = sess.run([col1, col2,key])
#若当前line_key第二次等于第一行的key(即line1_name)则说明读取完,跳出循环
if is_second_read==0 and line_key==line1_name:
is_second_read=1
elif is_second_read==1 and line_key==line1_name:
break
print (x_,y_,line_key)
#循环结束后,请求关闭所有线程
coord.request_stop()
coord.join(threads)
sess.close()
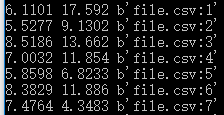
输出结果


















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









