







 本文详细介绍了缓存(Cache)的工作原理,包括基于程序局部性的访问特点,以及全相连、直接映射和组相连三种映射方式的优缺点。还探讨了缓存替换算法,如随机、FIFO和LRU,并讨论了写策略,如写回法和全写法。最后,提到了多级缓存系统中不同层级之间的数据一致性处理。
本文详细介绍了缓存(Cache)的工作原理,包括基于程序局部性的访问特点,以及全相连、直接映射和组相连三种映射方式的优缺点。还探讨了缓存替换算法,如随机、FIFO和LRU,并讨论了写策略,如写回法和全写法。最后,提到了多级缓存系统中不同层级之间的数据一致性处理。
cache
- 基于程序的局部性原理
-
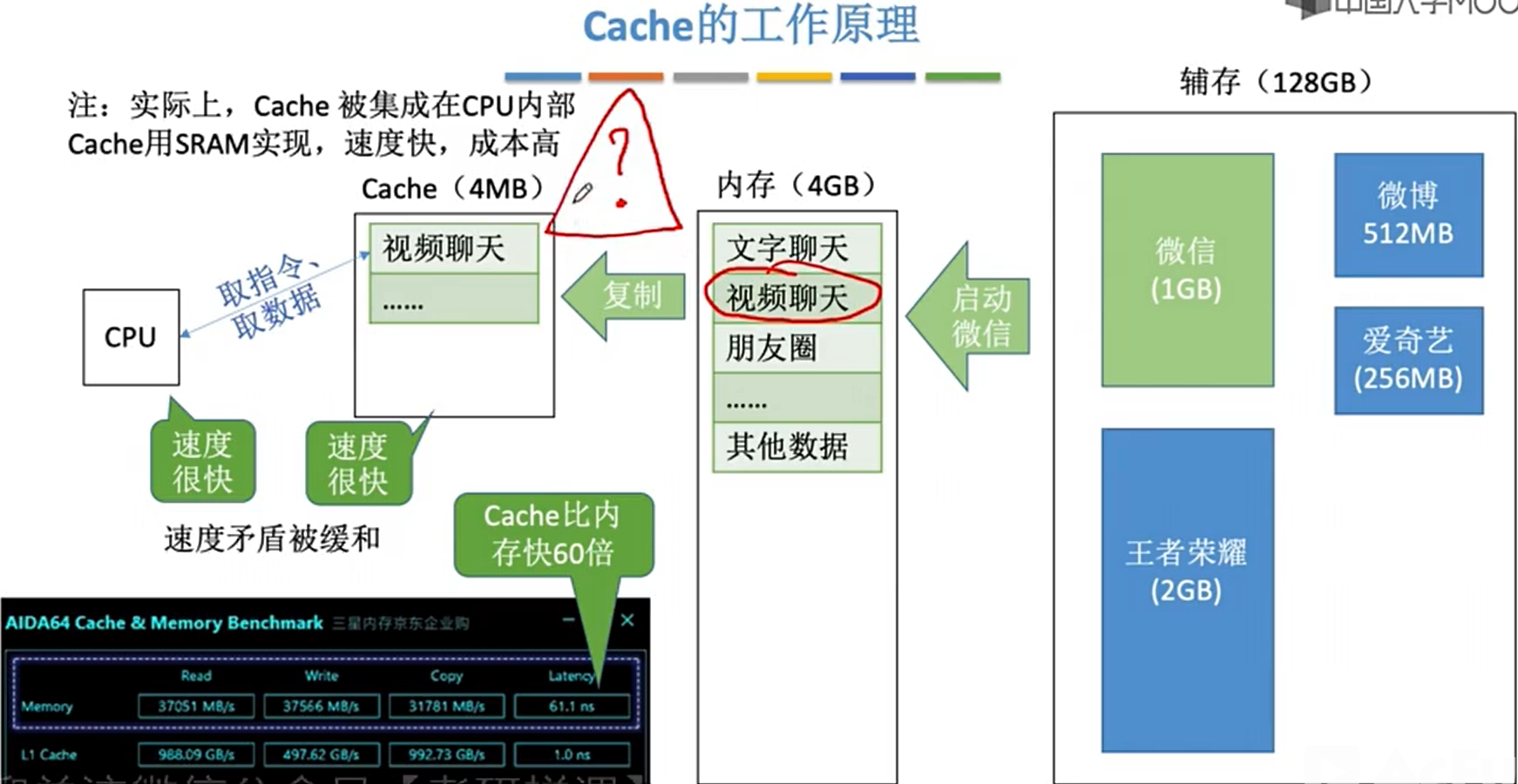
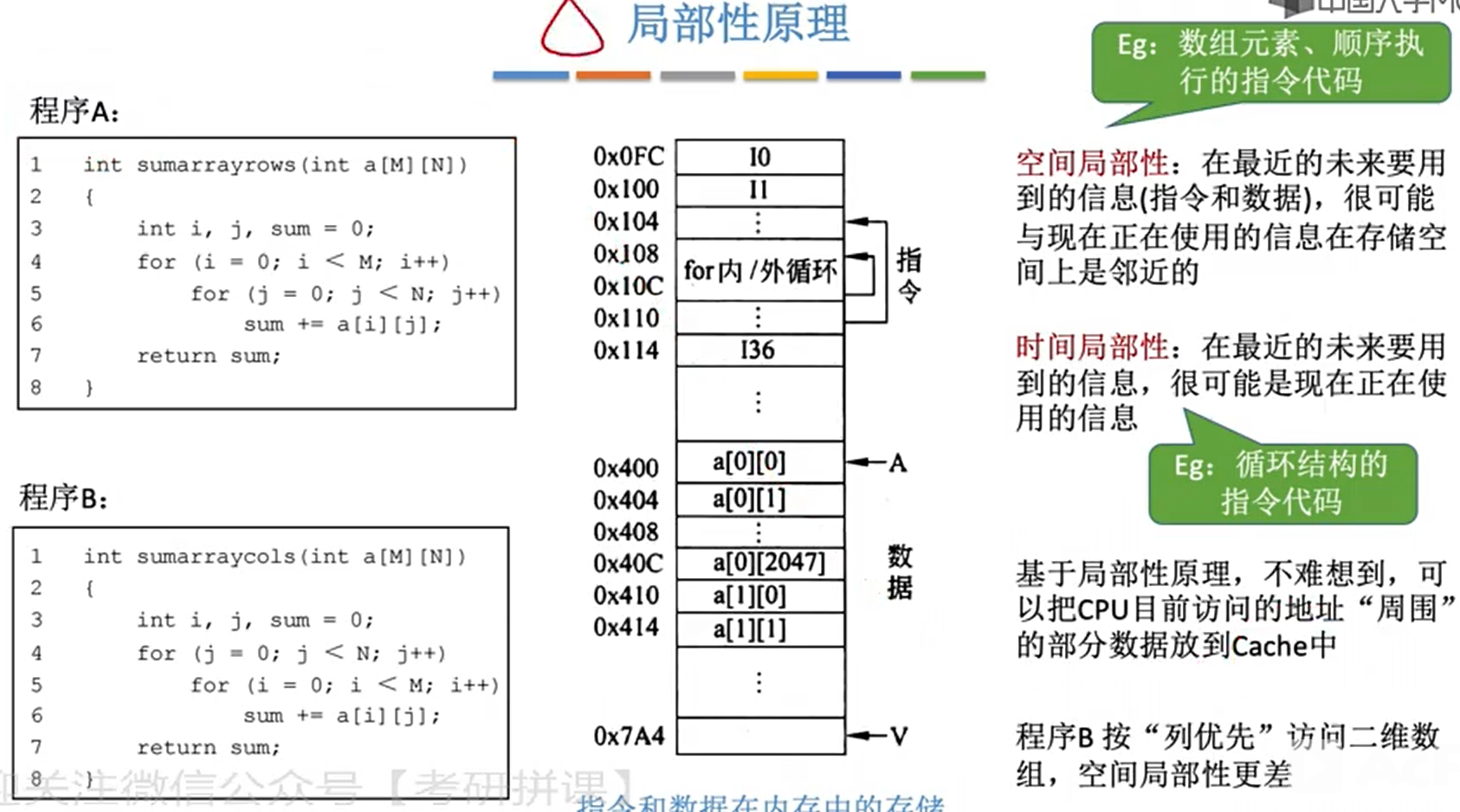
- 突然想起之前字节面试时问过这个问题,当时是回答的按列不连续,但是忘记说cache的存在了,由于会将空间局部放进cache,所以实际上按列无法直接访问cache,故速度更慢
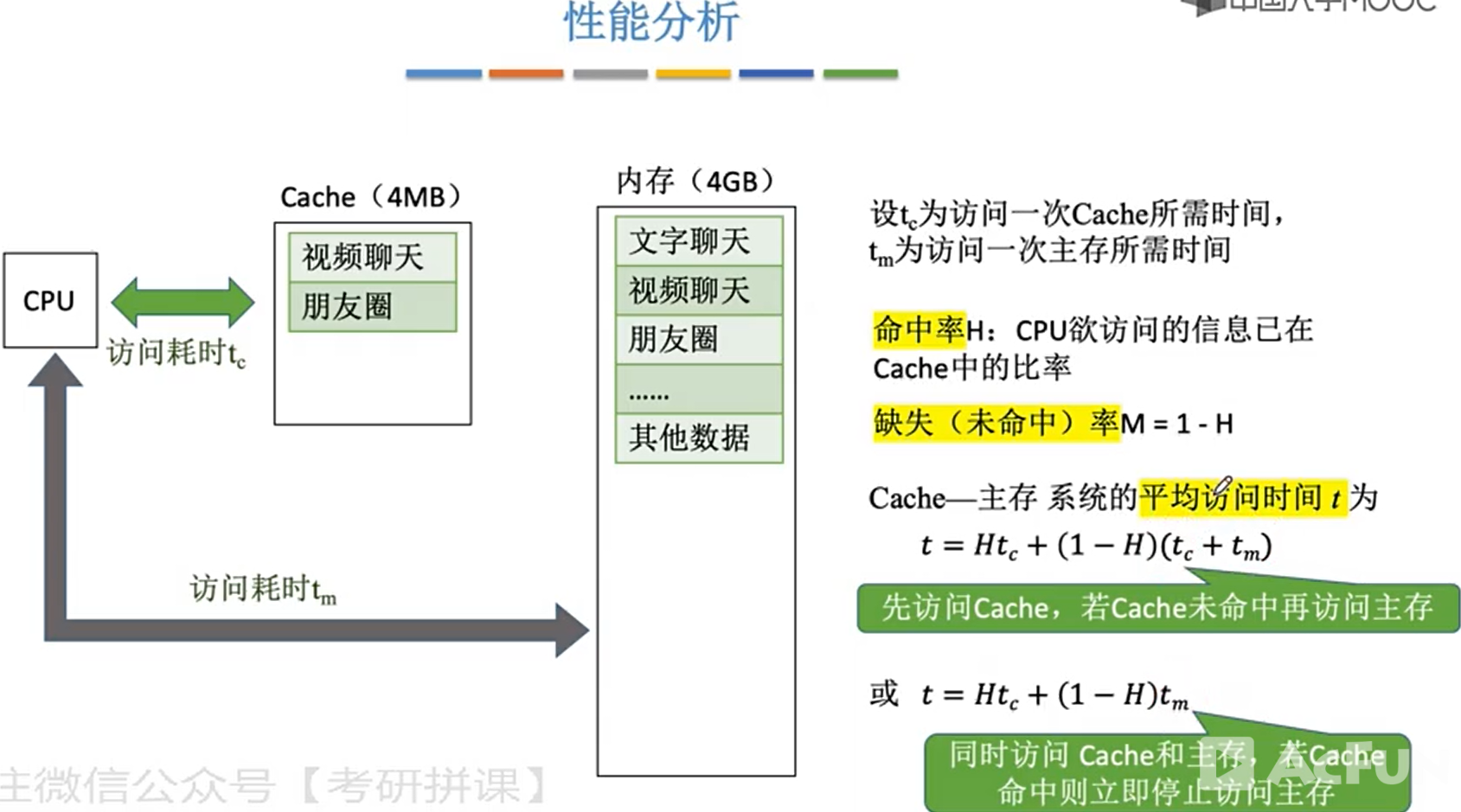
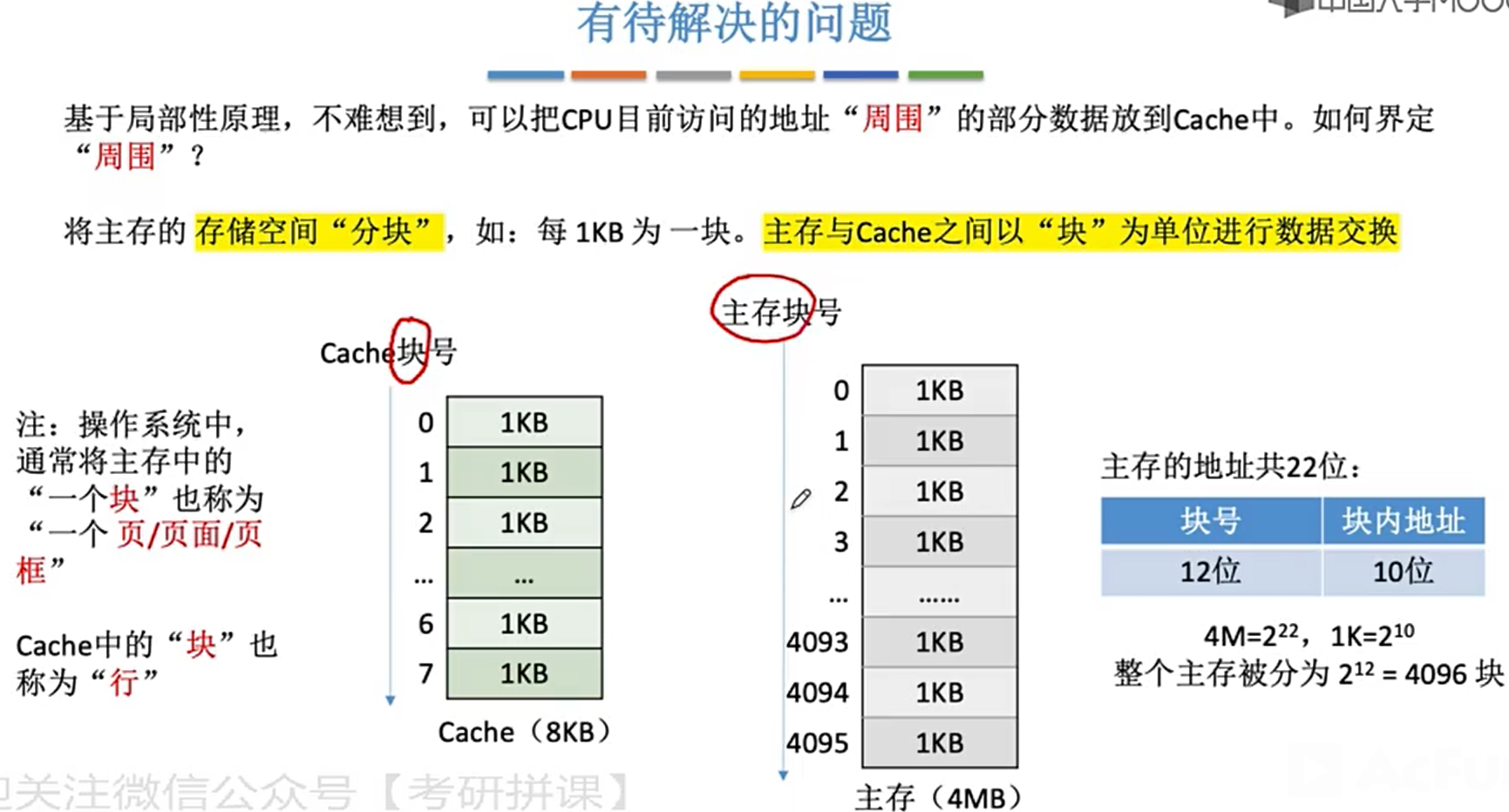
- 每次被访问的主存块,一定会被立即调入cache
cache与主存的映射
-
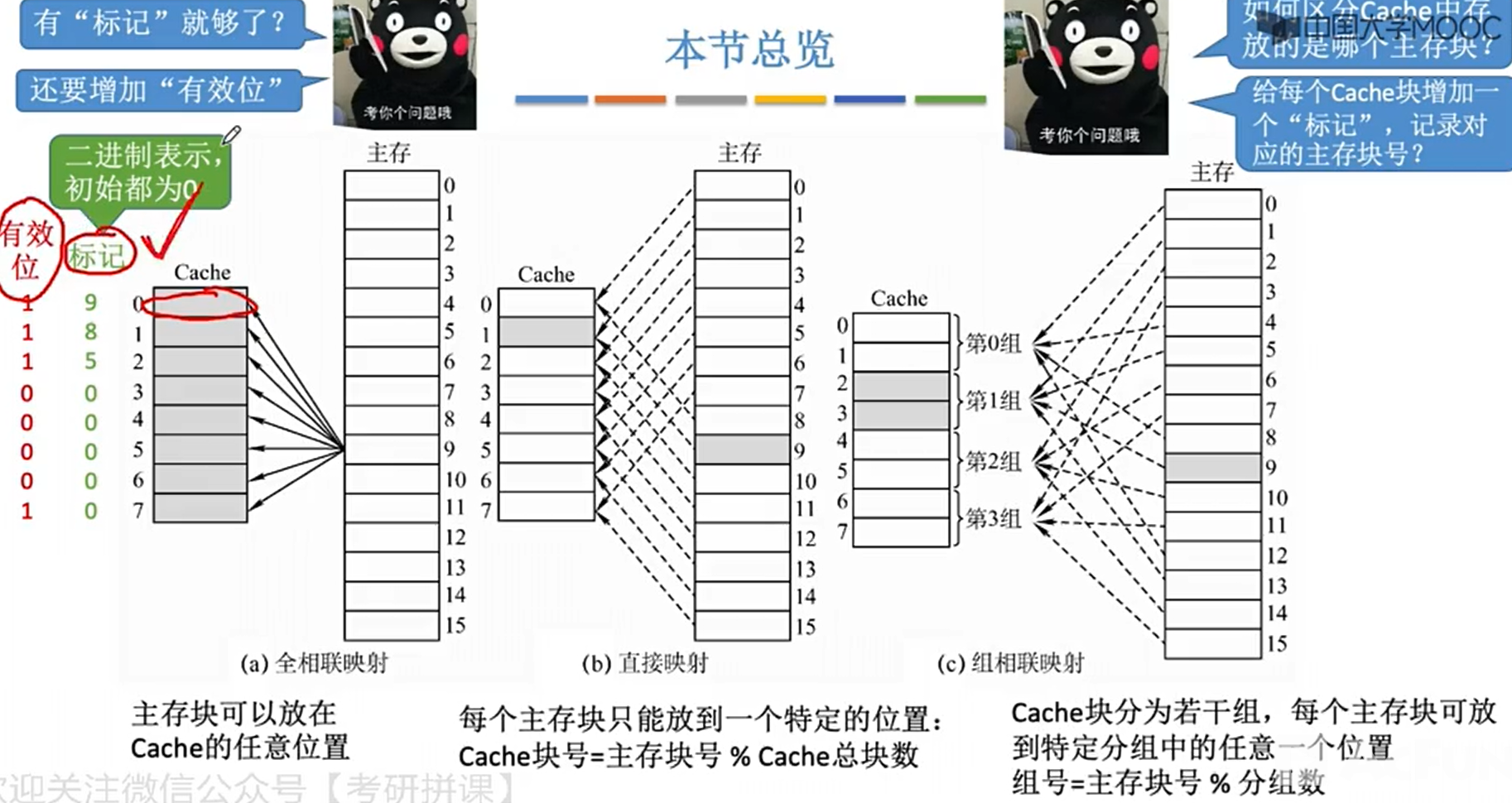
-
标记 标识cache中的每个块是主存的哪个块
-
有效位 标识是否有效 (可以区分0块和空)
-
全相连映射
-
-
直接映射
-
组相连映射
- 和直接映射区别不大其实
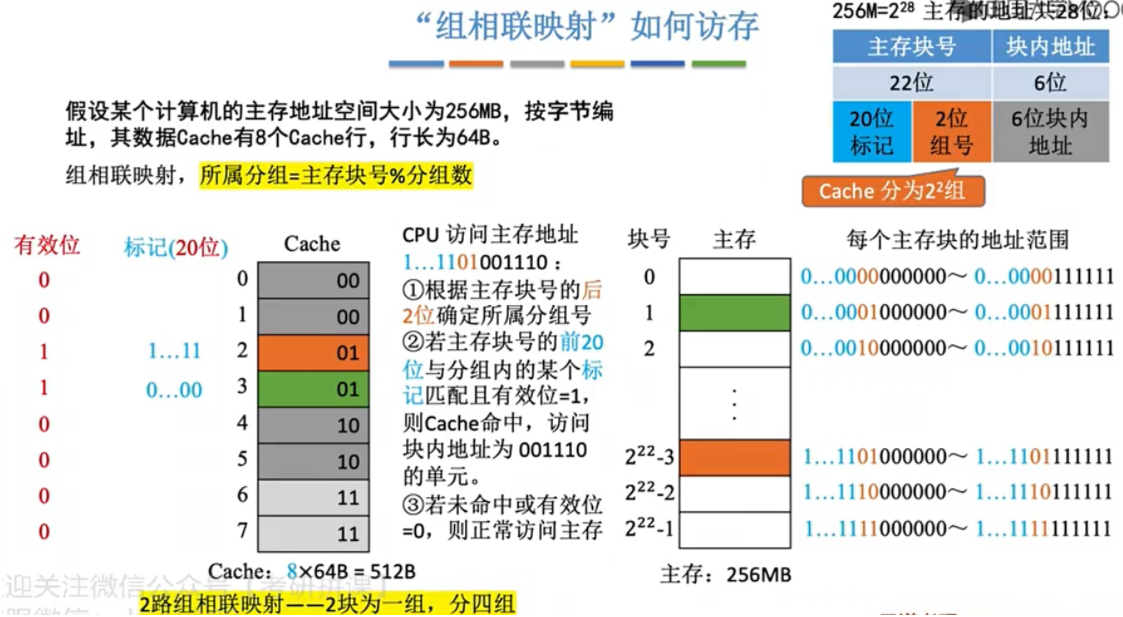
-
总结:
- 全连接映射:空间利用率高,每个主存块可以放到任意的cache位置,但是在查找时,需要遍历所有进行对比,看是否命中,时间上一般,命中率高
- 直接映射在时间上比较快,基本是O(1),但是就算cache有剩余空间,大概率也放不进来,命中率很低
- 组相连也差不多吧
- 所以又是时间与空间的平衡
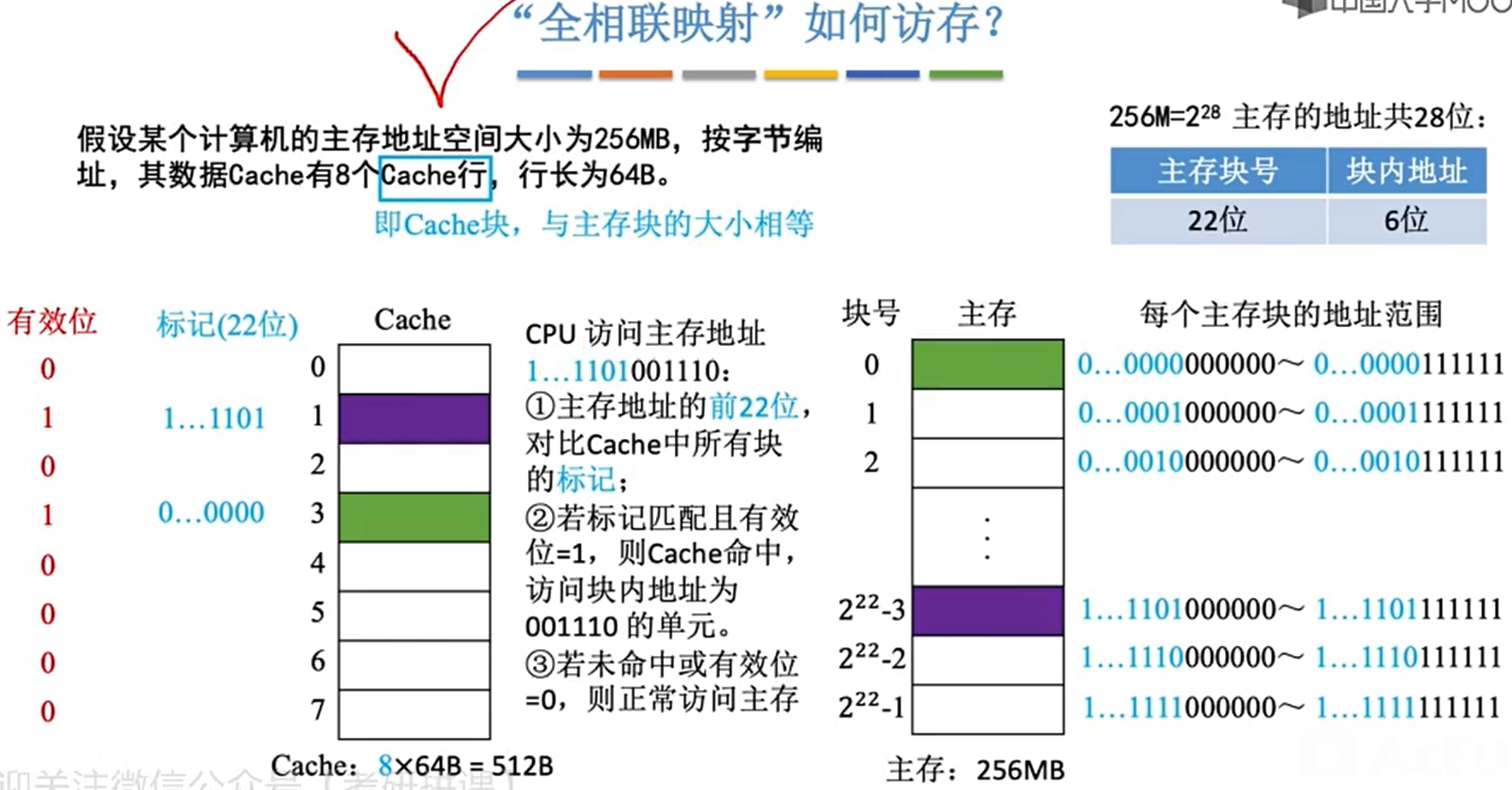
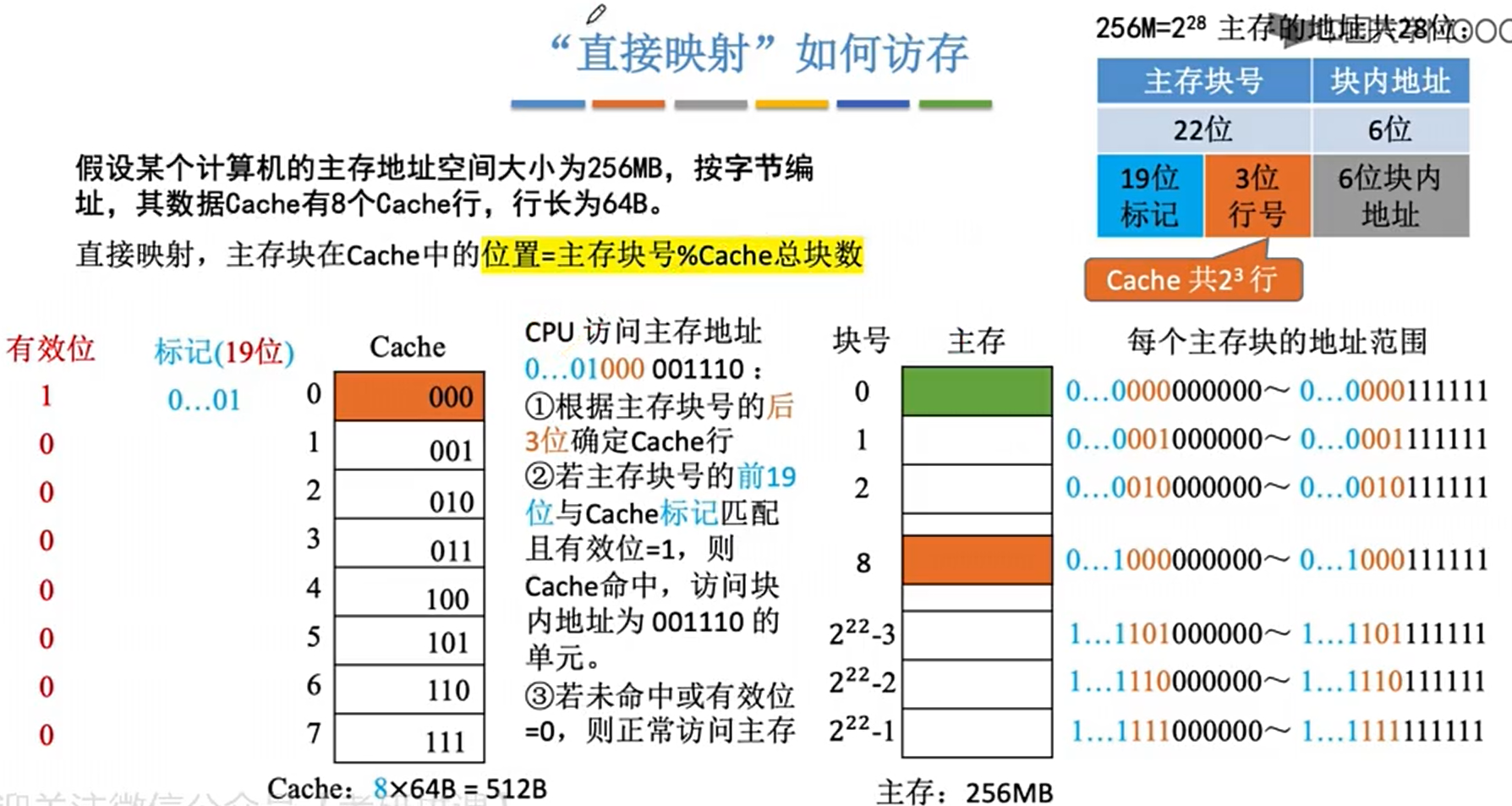
cache替换算法
- 对于不同的映射方式,它的替换算法是不同的
- 直接映射不需要考虑
- 随机算法:
- 若cache满了,随机选择一块替换
- FIFO 先进先出
- balabala
- LRU 近期最少使用
- 计数器,使用次数
- LFU最不经常使用
- 这里都在操作系统中学过了,所以不记录了,没有必要
cache的写策略
- cache与主存的数据一致性
- 实际上这里和redis、mysql的逻辑是一样
- 写命中
- 写回法:只修改cache内容,只有当此块被换出时才写会主存
- 增加一个脏位进行标记
- 全写法:都修改
- 一般使用写缓冲 write buffer,从而减少cpu访问主存的次数
- SRAM实现FIFO队列的写缓冲
- 专门的控制电路将FIFO逐一写回
- 适合cpu写操作不频繁,若频繁,则FIFO会阻塞
- 写回法:只修改cache内容,只有当此块被换出时才写会主存
- 写未命中
- 写分配法:先把主存块调入cache,然后修改cache
- 适合与写回法搭配使用
- 非写分配法:同时修改,使用写缓冲
- 与全写法搭配
- 写分配法:先把主存块调入cache,然后修改cache
- 多级cache
- L1、L2、L3
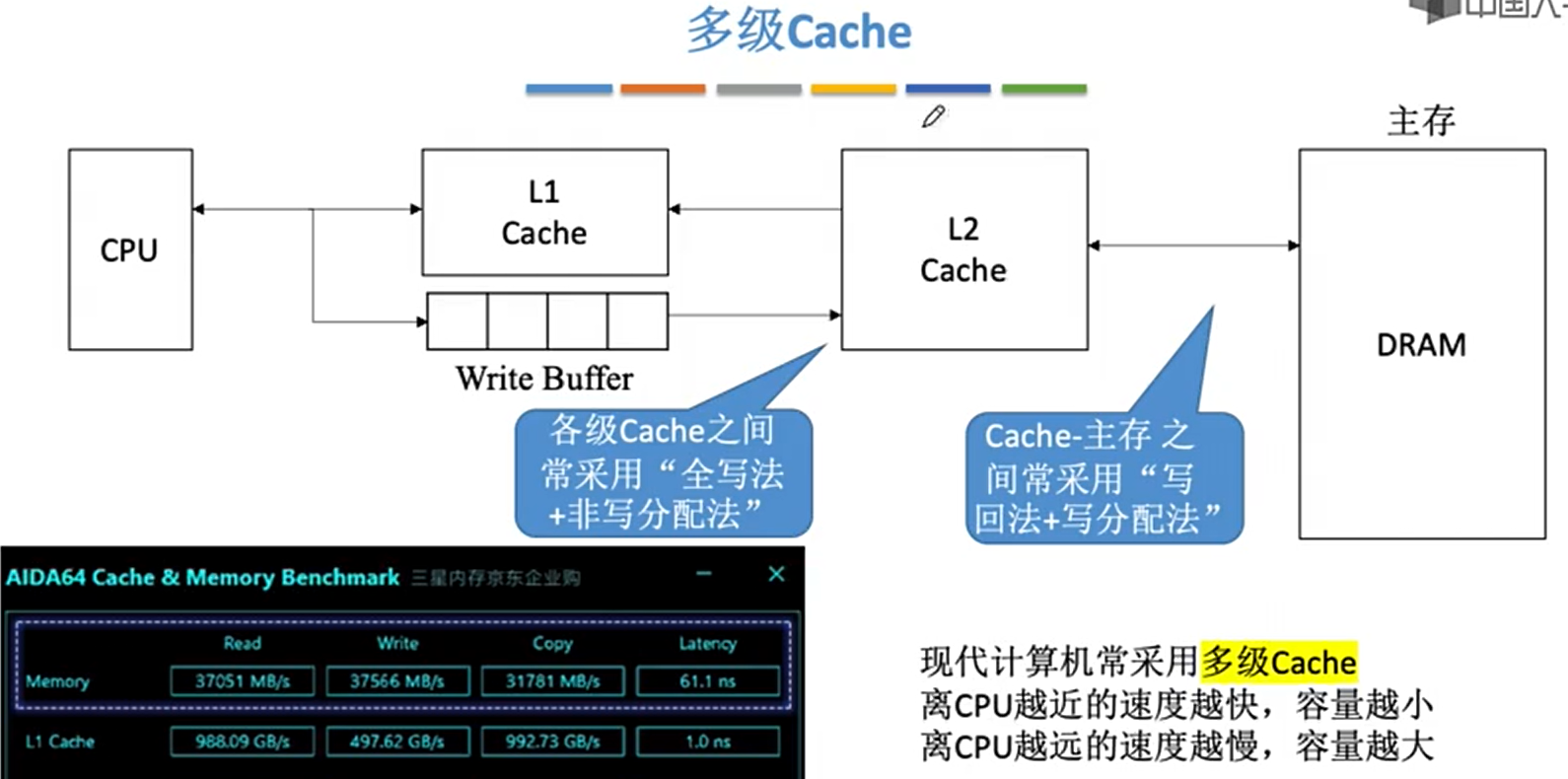
- cache速度比较快,所以它们之间用全写法;cache和主存之间速度差异大,所以用写回法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









