







【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
1.什么是神经风格迁移

以上便是神经风格迁移的两个例子。在本文中,我们将用C表示原始图像,S表示要迁移的图像风格,G表示最终合成的图像。
2.卷积网络的可视化
本部分内容主要引自论文:Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//European conference on computer vision. Springer, Cham, 2014: 818-833.
相关博客讲解:【论文阅读】Visualizing and Understanding Convolutional Networks。
在正式介绍神经风格迁移之前,我们可以先通过可视化来解释CNN的每一层学习到了什么东西。
假设我们有如下网络:
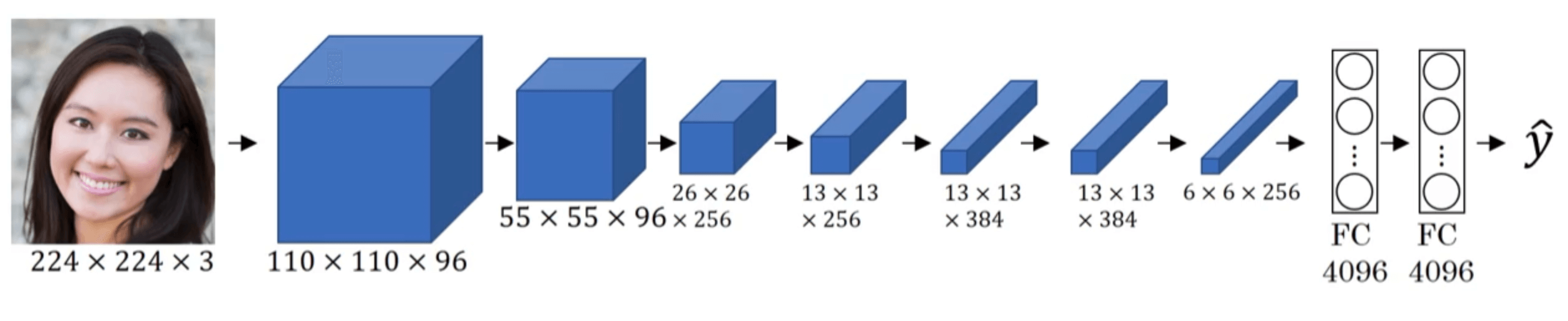
将第一个隐藏层学习到的内容进行可视化:

可以看到,第一个隐藏层只学到了一些简单的特征,比如边缘、阴影等。
同样的,将第二到第五个隐藏层学习到的内容都进行可视化:

每一个隐藏层相较前一个隐藏层都学到了更为复杂的形状和图案。并且,更靠后的隐藏层能够看到更大的区域。
3.神经风格迁移系统的代价函数
神经风格迁移系统的目标是生成新的图片G,因此我们需要构建一个关于G的代价函数 J ( G ) J(G) J(G),来评价生成图像G的好坏。
通常把 J ( G ) J(G) J(G)分为两个部分:
J ( G ) = α J c o n t e n t ( C , G ) + β J s t y l e ( S , G ) J(G)=\alpha J_{content}(C,G)+\beta J_{style}(S,G) J(G)=αJcontent(C,G)+βJstyle(S,G)
- 内容代价(content cost):用于衡量G与C内容之间的相似度。
- 风格代价(style cost):用于衡量G与S风格之间的相似度。
超参数 α , β \alpha,\beta α,β为两种代价的权重。
主要观点来自论文:Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style[J]. arXiv preprint arXiv:1508.06576, 2015.
算法的大致步骤为:
- 随机初始化G。比如设G的大小为 100 × 100 × 3 100\times 100 \times 3 100×100×3或其他任何你想要的尺寸。
- 使用梯度下降法最小化代价函数 J ( G ) J(G) J(G)。更新G为 G : = G − ∂ ∂ G J ( G ) G:=G-\frac{\partial }{\partial G}J(G) G:=G−∂G∂J(G)(其实更新的是图像G的像素值)。
例如我们有C(左)和S(右)见下:

G的生成过程可能是下面这个样子的:

接下来我们来讨论下如何定义内容代价函数和风格代价函数。
3.1.定义内容代价函数
假设我们用隐藏层 l l l来计算内容代价。使用一个预训练过的卷积神经网络,例如VGG网络。 a [ l ] ( C ) , a [ l ] ( G ) a^{[l](C)},a^{[l](G)} a[l](C),a[l](G)分别表示C和G在层 l l l的激活函数值。如果 a [ l ] ( C ) , a [ l ] ( G ) a^{[l] (C)},a^{[l] (G)} a[l](C),a[l](G)比较接近,则可认为C和G有着相似的内容。
l l l通常会选在网络的中间部分,不会过浅也不会过深。
因此,内容代价函数可定义为:
J c o n t e n t ( C , G ) = ∥ a [ l ] ( C ) − a [ l ] ( G ) ∥ 2 2 J_{content}(C,G)=\lVert a^{[l](C)} - a^{[l](G)} \rVert _2 ^2 Jcontent(C,G)=∥a[l](C)−a[l](G)∥22
3.2.定义风格代价函数
假设我们依旧用隐藏层 l l l来计算风格代价(可以和计算内容代价选择的隐藏层不同)。假设层 l l l的结构如下(feature map的数量为5,即深度/通道数为5):

我们可以根据S和G的feature map构建两个风格矩阵,因为feature map代表着该层学习到的图像的某些特征,因此如果两个风格矩阵接近的话,我们可以认为S和G在某些图像特征上是类似的,即拥有类似的风格。
那么该如何构建风格矩阵呢?
设 a i , j , k [ l ] a^{[l]}_{i,j,k} ai,j,k[l]为层 l l l在 ( n H = i , n W = j , n C = k ) (n_H=i,n_W=j,n_C=k) (nH=i,nW=j,nC=k)位置的激活函数值。则S在层 l l l的风格矩阵 G [ l ] ( S ) G^{[l] (S)} G[l](S)(在数学中被称为“Gram”矩阵)的大小应该为 n C [ l ] × n C [ l ] n_C^{[l]} \times n_C^{[l]} nC[l]×nC[l](即每两个feature map之间都要计算其相关性)。假设 k , k ′ k,k' k,k′为其中两个feature map(或者说是通道,即 k , k ′ = 1 , . . . , n C [ l ] k,k'=1,...,n_C^{[l]} k,k′=1,...,nC[l]),则 G [ l ] ( S ) G^{[l](S)} G[l](S)可定义为:
G k k ′ [ l ] ( S ) = ∑ i = 1 n H [ l ] ∑ j = 1 n W [ l ] a i , j , k [ l ] ( S ) a i , j , k ′ [ l ] ( S ) G^{[l](S)}_{kk'}=\sum_{i=1}^{n_H^{[l]}} \sum_{j=1}^{n_W^{[l]}} a^{[l](S)}_{i,j,k} a^{[l](S)}_{i,j,k'} Gkk′[l](S)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](S)ai,j,k′[l](S)
然后对生成图像G进行同样的操作,计算其风格矩阵:
G k k ′ [ l ] ( G ) = ∑ i = 1 n H [ l ] ∑ j = 1 n W [ l ] a i , j , k [ l ] ( G ) a i , j , k ′ [ l ] ( G ) G^{[l](G)}_{kk'}=\sum_{i=1}^{n_H^{[l]}} \sum_{j=1}^{n_W^{[l]}} a^{[l](G)}_{i,j,k} a^{[l](G)}_{i,j,k'} Gkk′[l](G)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](G)ai,j,k′[l](G)
关于层 l l l的风格代价函数可定义如下:
J s t y l e [ l ] ( S , G ) = ∥ G [ l ] ( S ) − G [ l ] ( G ) ∥ F 2 = ∑ k ∑ k ′ ( G k k ′ [ l ] ( S ) − G k k ′ [ l ] ( G ) ) 2 J^{[l]}_{style}(S,G)=\lVert G^{[l](S)}-G^{[l](G)} \rVert ^2_F = \sum_k \sum_{k'} (G^{[l](S)}_{kk'} - G^{[l](G)}_{kk'})^2 Jstyle[l](S,G)=∥G[l](S)−G[l](G)∥F2=k∑k′∑(Gkk′[l](S)−Gkk′[l](G))2
也可以选择在上式中加上归一化系数:
J s t y l e [ l ] ( S , G ) = 1 ( 2 n H [ l ] n W [ l ] n C [ l ] ) 2 ∥ G [ l ] ( S ) − G [ l ] ( G ) ∥ F 2 J^{[l]}_{style}(S,G)=\frac{1}{(2n_H^{[l]} n_W^{[l]} n_C^{[l]} )^2} \lVert G^{[l](S)}-G^{[l](G)} \rVert ^2_F Jstyle[l](S,G)=(2nH[l]nW[l]nC[l])21∥G[l](S)−G[l](G)∥F2
当然也可以不加这个归一化系数,因为已经有了超参数 β \beta β。
此外,如果我们对各层都使用风格代价函数会让结果变得更好,那么总体的风格代价函数可以定义为各层风格代价函数之和:
J s t y l e ( S , G ) = ∑ l λ [ l ] J s t y l e [ l ] ( S , G ) J_{style}(S,G)= \sum_l \lambda^{[l]} J^{[l]}_{style}(S,G) Jstyle(S,G)=l∑λ[l]Jstyle[l](S,G)
其中, λ [ l ] \lambda ^{[l]} λ[l]为层 l l l的权重。这样做的好处就是可以同时考虑到浅层的低级特征和深层的高级特征。
4.代码地址
5.参考资料
想要获取最新文章推送或者私聊谈人生,请关注我的个人微信公众号:⬇️x-jeff的AI工坊⬇️

个人博客网站:https://shichaoxin.com
GitHub:https://github.com/x-jeff


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









