







 本文详细介绍了链表操作中的关键点,包括理解指针或引用的含义,警惕指针丢失和内存泄漏,以及如何利用“哨兵”简化链表操作。特别强调了边界条件处理的重要性,提供了插入、删除节点的例子,并探讨了哨兵节点在处理边界情况时的优势。此外,还讨论了链表中环的检测与计算链表长度、中间节点等常见问题的解决方案。
本文详细介绍了链表操作中的关键点,包括理解指针或引用的含义,警惕指针丢失和内存泄漏,以及如何利用“哨兵”简化链表操作。特别强调了边界条件处理的重要性,提供了插入、删除节点的例子,并探讨了哨兵节点在处理边界情况时的优势。此外,还讨论了链表中环的检测与计算链表长度、中间节点等常见问题的解决方案。
一、理解指针或引用的含义
有些语言有“指针”的概念,比如 C 语言;有些语言没有指针,取而代之的是“引用”,比如 Java、Python。不管是“指针”还是“引用”,都是存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next = q; // 表示p节点的后继指针存储了q节点的内存地址。
p->next = p->next->next; // 表示p节点的后继指针存储了p节点的下下个节点的内存地址。
二、警惕指针丢失和内存泄漏(单链表)
以单链表的插入操作为例。

在结点a和相邻的结点b之间插入结点x,p指针指向节点a,如果按照下述过程实现,则造成指针丢失和内存泄漏。
p->next = x; // 将p的next指针指向x结点;
x->next = p->next; // 将x的结点的next指针指向b结点;
p->next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。第 2 行代码相当于将 x 赋值给 x->next,这会导致x节点的后继指针指向自身。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到了。对于有些语言来说,比如 C 语言,内存管理是由程序员负责的,如果没有手动释放结点对应的内存空间,就会产生内存泄露。
所以插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏。如下所示:
x—>next = p—>next;// 将x的结点的next指针指向b结点;
p—>next = x;// 将p的next指针指向x结点;
内存泄露:申请了内存空间进行使用,用完之后忘了归还,结果自己申请的那块内存空间最后自己也访问不到了(也有可能是把它的地址弄丢了),而系统也没办法把他分给需要的程序。
内存溢出:1.要求分配的内存超出了系统能够给的,系统不能满足,于是就产生了溢出。2.或者申请int大小的内存,但是存放了long大小的数据,结果导致内存不够用,也会导致内存溢出。
再以删除一个节点举例。
删除 a节点 和 c节点 间的 b节点,b是a的下一节点,p指针指向节点a:
p—>next = p—>next—>next;
三、利用“哨兵”简化实现难度
回顾一下单链表的插入和删除操作。如果在结点 p 后面插入一个新的结点,只需要下面两行代码就可以搞定。
new_node->next = p->next;
p->next = new_node;
但当要向一个空链表中插入第一个结点,上述逻辑要进行下面这样的特殊处理,其中 head 表示链表的头结点。可以发现,对于单链表的插入操作,第一个结点和其他结点的插入逻辑是不一样的。
if (head == null) {
head = new_node;
}
再来看单链表结点删除操作。如果要删除结点 p 的后继结点,只需要一行代码。
p->next = p->next->next;
但如果要删除链表中的最后一个结点,需要对于这种情况特殊处理。
if (head->next == null) {
head = null;
}
针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。 这样代码实现起来就会很繁琐,不简洁,而且也容易因为考虑不全而出错。如何来解决这个问题呢?
引入”哨兵“👮♂️
链表中的“哨兵”节点是解决边界问题的,不参与业务逻辑。
不带头结点的链表,初始时 head = null ;
带头结点的链表,初始时 head->next = null ;
如果引入“哨兵”节点,则不管链表是否为空,head指针都会指向这个“哨兵”节点。这样,插入第一个节点和插入其他节点,删除最后一个节点和删除其他节点都可以统一为相同的代码实现逻辑了。把这种有“哨兵”节点的链表称为带头链表,相反,没有“哨兵”节点的链表就称为不带头链表。

删除最后一个节点,在没有加哨兵的时候,哪怕只有一个节点也得给他删除掉,这个时候自然用p->next=p.next->next没用,就一个节点的话p.next和p.next.next都是null嘛 相当于null=null。 但是加上哨兵就不同了,哨兵是恒存在于链表中的,删除链表中的最后一个元素(是删除哨兵以外的最后一个,哨兵不参与业务逻辑)所以当哨兵后还跟着一个元素时,也就是有最后一个元素时,站在哨兵的位置依旧可以执行p.next=p.next.next,进而把最后一个干掉。
举例对比有无哨兵的情况
// 在数组a中,查找key,返回key所在的位置
// 其中,n表示数组a的长度
int find(char* a, int n, char key) {
// 边界条件处理,如果a为空,或者n<=0,说明数组中没有数据,就不用while循环比较了
if(a == null || n <= 0) {
return -1;
}
int i = 0;
// 这里有两个比较操作:i<n和a[i]==key.
while (i < n) {
if (a[i] == key) {
return i;
}
++i;
}
return -1;
}
// 在数组a中,查找key,返回key所在的位置
// 其中,n表示数组a的长度
// 我举2个例子,你可以拿例子走一下代码
// a = {4, 2, 3, 5, 9, 6} n=6 key = 7
// a = {4, 2, 3, 5, 9, 6} n=6 key = 6
int find(char* a, int n, char key) {
if(a == null || n <= 0) {
return -1;
}
// 这里因为要将a[n-1]的值替换成key,所以要特殊处理这个值
if (a[n-1] == key) {
return n-1;
}
// 把a[n-1]的值临时保存在变量tmp中,以便之后恢复。tmp=6。
// 之所以这样做的目的是:希望find()代码不要改变a数组中的内容
char tmp = a[n-1];
// 把key的值放到a[n-1]中,此时a = {4, 2, 3, 5, 9, 7}
a[n-1] = key;
int i = 0;
// while 循环比起代码一,少了i<n这个比较操作
while (a[i] != key) {
++i;
}
// 恢复a[n-1]原来的值,此时a= {4, 2, 3, 5, 9, 6}
a[n-1] = tmp;
if (i == n-1) {
// 如果i == n-1说明,在0...n-2之间都没有key,所以返回-1
return -1;
} else {
// 否则,返回i,就是等于key值的元素的下标
return i;
}
}
对比两段代码,在字符串 a 很长的时候,比如几万、几十万,代码二运行得更快点呢?答案是,因为两段代码中执行次数最多就是 while 循环那一部分。第二段代码中,通过一个哨兵 a[n-1] = key,成功省掉了一个比较语句 i<n,当累积执行万次、几十万次时,累积的时间就很明显了。这只是为了举例说明哨兵的作用,写代码的时候千万不要写第二段那样的代码,因为可读性太差。
四、重点留意边界条件处理
要在编写的过程中以及编写完成之后,检查边界条件是否考虑全面,以及代码在边界条件下是否能正确运行。经常用来检查链表是否正确的边界4个边界条件:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个节点时,代码是否能正常工作?
- 如果链表只包含两个节点时,代码是否能正常工作?
- 代码逻辑在处理头尾节点时是否能正常工作?
五、举例画图,辅助思考
核心:释放脑容量,留更多的给逻辑思考。
比如往单链表中插入一个数据这样一个操作,把各种情况都举一个例子,画出插入前和插入后的链表变化,如图所示:

六、多写多练
5个常见的链表操作:
-
单链表反转 206:借助外部空间、双指针迭代、递归解法
-
链表中环的检测 I 141:
-
判断是否会多次访问重复的节点:依次遍历单链表中的每一个节点。每遍历一个新的节点,就从头检查新节点之前的所有节点,用新节点和此节点之前所有节点依次作比较。如果发现新节点和之前的某个节点相同,说明该节点被遍历过两次,链表存在环。
-
暴力解法:遍历判定head.next == null 是否存在,可以设置最大的链表结点个数(设置个数为10000)或时间(比如1s内的搜索),看是否能遇到这种情况。
-
哈希集:使用哈希集来存储所有已经访问过的节点(创建一个以节点ID为Key的HashSet 集合,HashSet,不存在重复的元素)。每次到达一个节点,如果该节点存在于哈希集中,则说明该链表是环形链表;否则将该节点加入哈希集中。重复上述过程,直到遍历完整个链表。
-
快慢指针(龟兔赛跑):定义两个指针,一快一慢。快指针每次移动两步,慢指针每次移动一步,如果两者经过一段时间后相遇,则证明链表中有环。
-
❗如果链表有环,求出环的长度?
当快慢指针首次相遇,证明有环时,让两个指针从相遇点继续循环前进,并统计前进的循环次数,直到两个指针第二次相遇。此时统计出来的前进次数就是环长。
原因:指针slow每次走1步,指针fast每次走2步。当两个指针再次相遇时,fast比slow多走了整整一圈。
环长 = 每次的速度差 * 前进次数 = 1 * 前进次数 = 前进次数
-
链表中环入口的检测 II 142:
-
哈希集:遍历链表中的每个节点,并将它记录下来;一旦遇到了此前遍历过的节点,就可以判定链表中存在环。(HashSet)
-
快慢指针:链表有环情况判断记录相遇点;对快慢指针的所走距离进行关系建立。
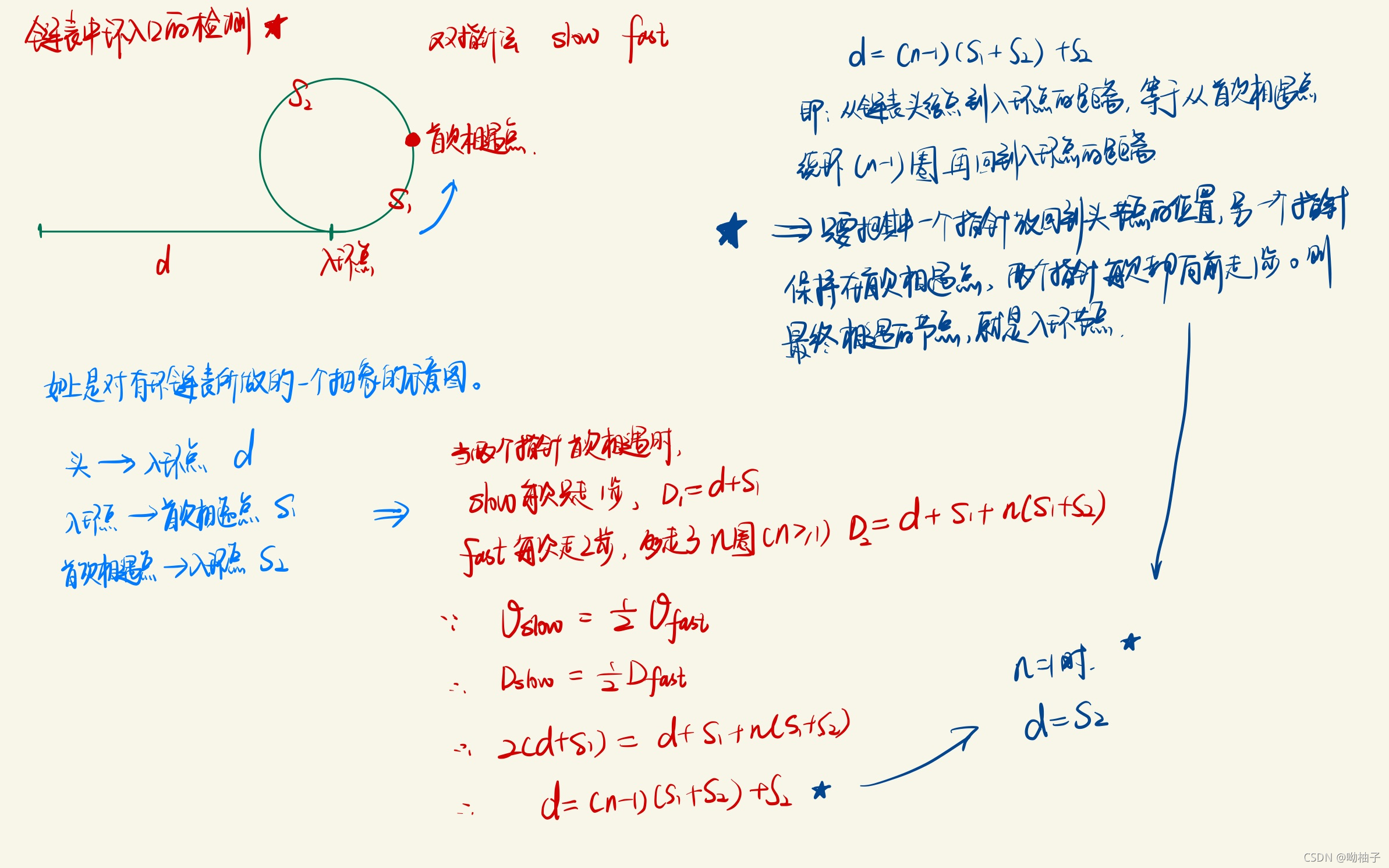
-
-
两个有序链表合并 21:
- 递归:两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。

- 迭代:当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。
- 递归:两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。
-
删除链表倒数第n个节点 19 —— 添加哑节点来统一删除操作的普遍性
- 计算链表长度:首先从头节点开始对链表进行一次遍历,得到链表的长度Len;之后再从头遍历,当遍历到 Len - n + 1 个节点时,删除该节点即可。
- 栈(Deque—>Stack):在遍历链表的同时将所有节点依次入栈。根据“先进后出”的原则,弹出栈的第n个节点就是需要删除的节点,并且当下栈顶的节点就是待删除节点的前驱节点。
- 双指针大法——前后双指针
- 设置虚拟节点 dummyHead 指向 head;设定双指针 back 和 front ,初始都指向虚拟节点 dummyHead;
- 移动 front ,直到 back与 front 之间相隔的元素个数为 n;
- 同时移动 back 与 front ,直到 front 指向的为 null;
- 将 back 的 next 指针指向下下个节点。
-
求链表的中间节点 876
- 数组变换,使用下标访问:对链表进行遍历,同时将遍历到的元素依次放入数组
A中。如果遍历到了N个元素,那么链表以及数组的长度也为N,对应的中间节点即为A[N/2]。 - 单指针法:对方法一进行空间优化。对链表进行两次遍历。第一次遍历时,统计链表中的元素个数 len;第二次遍历时,遍历到第 len/2 个元素(链表的首节点为第 0 个元素)时,将该元素返回即可。
- 快慢指针:用两个指针
slow与fast一起遍历链表。slow一次走一步,fast一次走两步。当fast到达链表的末尾时,slow必然位于中间。
- 数组变换,使用下标访问:对链表进行遍历,同时将遍历到的元素依次放入数组


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









