







 本报告通过horseColic数据集对比分析了普通Logistic回归和stocLogistic回归。在数据预处理中,用0填充缺失值。Logistic回归在高迭代次数下精确度提升,但alpha值不变导致拟合区波动。stocLogistic回归针对大规模数据,采用随机采样和动态alpha,提高了精确度和效率。
本报告通过horseColic数据集对比分析了普通Logistic回归和stocLogistic回归。在数据预处理中,用0填充缺失值。Logistic回归在高迭代次数下精确度提升,但alpha值不变导致拟合区波动。stocLogistic回归针对大规模数据,采用随机采样和动态alpha,提高了精确度和效率。
一、概述
本次报告利用了 horseColic 数据进行实验性分析,分析探讨了两种 Logistics回归模式的适用范围与优缺点。
二、数据预处理
本次实验数据采用 UCI 数据集中的 horseColic 数据,包含了 21 个特征与两个分类类别,并自身划分了训练集与测试集,在 21 个特征中,部分缺失的情况采用取 0 处理,这种做法的依据在是 Logistic 回归中这种做法不会影响 weights,从而减小缺失值对算法精确度的影响。另外,在 21 个特征中有部分是主观评价的,因而有着一定的模糊性,部分数据如下:
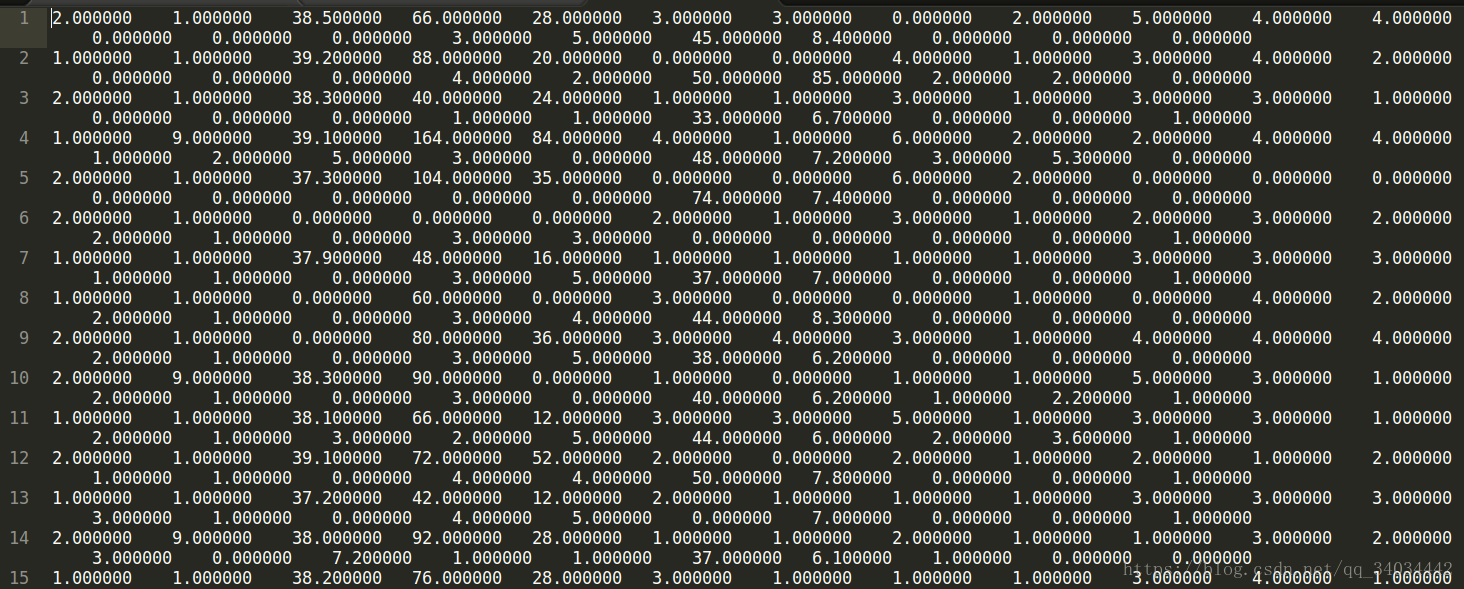
对缺失数据取零处理后直接带入 Logistic 与 stocLogistic 回归算法
三、算法对比分析
一般来说普通 Logistic 回归算法随着迭代次数的增多会呈现精确度增加的情况,但同时 alpha 的取值也会有着一定的影响,该报告分析了随着迭代次数增加对于精确度的影响。
具体实现:
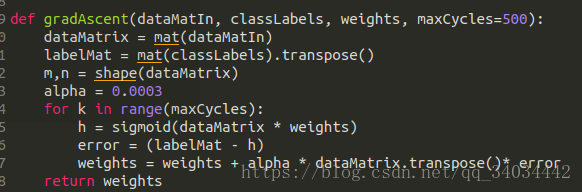
首先,对于机器学习实战中代码,其 gradAscent 函数每次取固定的 500 次作为迭代次数,为了能够分析随着迭代次数增加精确度的变化,对代码进行了改进,使 weights 作为迭代量,以 10 次训练为训练次数单位,并对每次迭代产生的 weights 进行精确度分析:
改进的 gradAscent 函数:
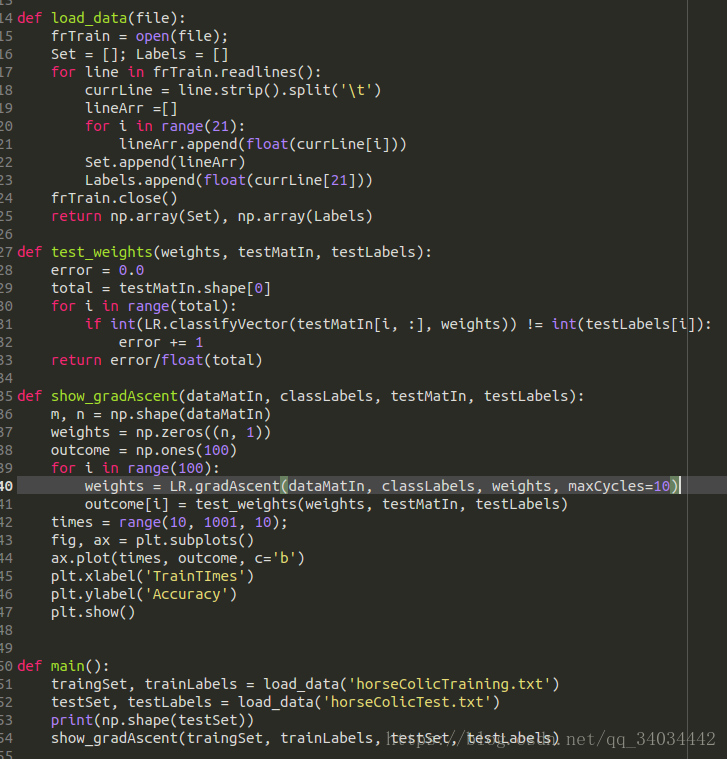
进行测试并可视化的函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









