







 本讲座聚焦自然语言处理中的问答系统,涵盖从早期的Simmons到现代的BERT模型的发展。重点介绍了斯坦福大学的SQuAD数据集及其评估标准,以及BiDAF模型的双向注意力流机制。此外,还讨论了复杂问答系统的挑战和最新进展。
本讲座聚焦自然语言处理中的问答系统,涵盖从早期的Simmons到现代的BERT模型的发展。重点介绍了斯坦福大学的SQuAD数据集及其评估标准,以及BiDAF模型的双向注意力流机制。此外,还讨论了复杂问答系统的挑战和最新进展。
本节课主要内容
- 最终项目的一些提示
- 问答系统产生的动机和发展历史
- 斯坦福大学的SQuAD数据集
- 斯坦福大学的Attentive Reader 模型
- BiDAF
- 最近的,更进一步的架构
- ELMo和BERT模型的概览、
一、最终项目的建议
论文写作过程:
二、问答系统
谷歌实际上构建了一个知识图谱为搜索引擎服务
可以把问答分为两个步骤:
找到可能含有答案的文档(可以通过传统的信息检索或网络搜索获得,在cs276课上回讨论这个问题,这里不讨论)
在一个段落或者文档中找到问题的答案,这个过程称为阅读理解,也就是今天这堂课的关注点
问答系统的历史
Simmons等人(1964)首次从说明性文本中探索了如何基于匹配的依赖关系分析来回答问题
Murax (Kupiec 1993)旨在通过在线百科全书使用IR和浅层语言处理来回答问题
NIST的TREC QA跟踪始于1999年,它首先对大量文档的事实问题进行了严格的调查
IBM的Jeopardy!System (DeepQA, 2011)引入了注意力;它使用了许多方法的集合
DrQA (Chen et al. 2016)采用IR结合神经阅读理解,将深度学习引入开放领域QA
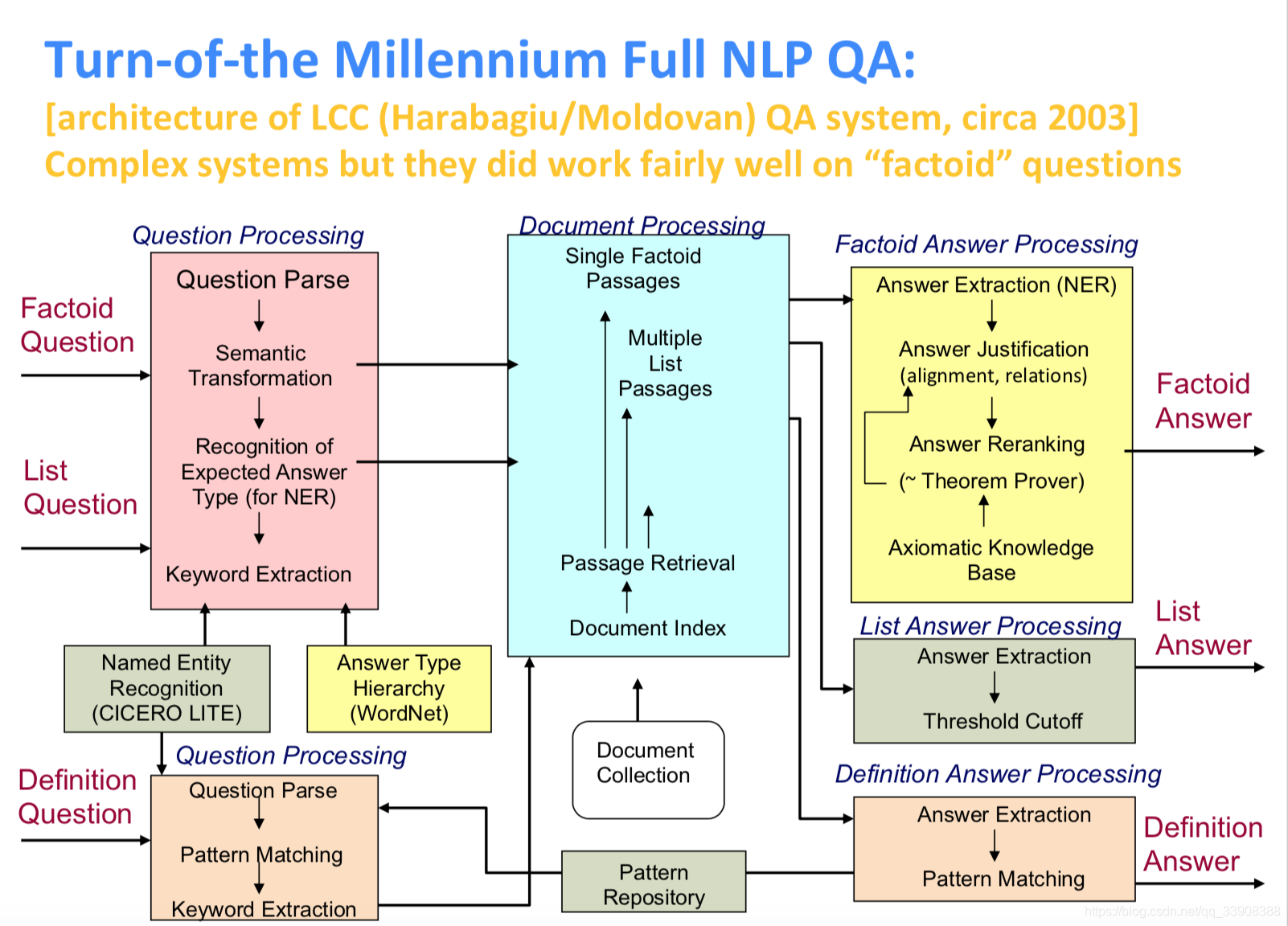
一个复杂的问答系统,但是在“factoid”问题上表现的很好
三、斯坦福大学的问答数据集SQuAD
SQuAD 的评估,v1.1版本的
针对一个问题,筛选出人回答的三个准确的答案
系统根据两个指标进行评估
- 精确匹配:系统的回答是否和三个答案之一的相匹配,有则为1,没有为0
- F1:将系统的回答与三个准确答案作为词袋,评估
![]()
F1用的比较多,这两个指标都忽略了标点符号的a,an这样的词
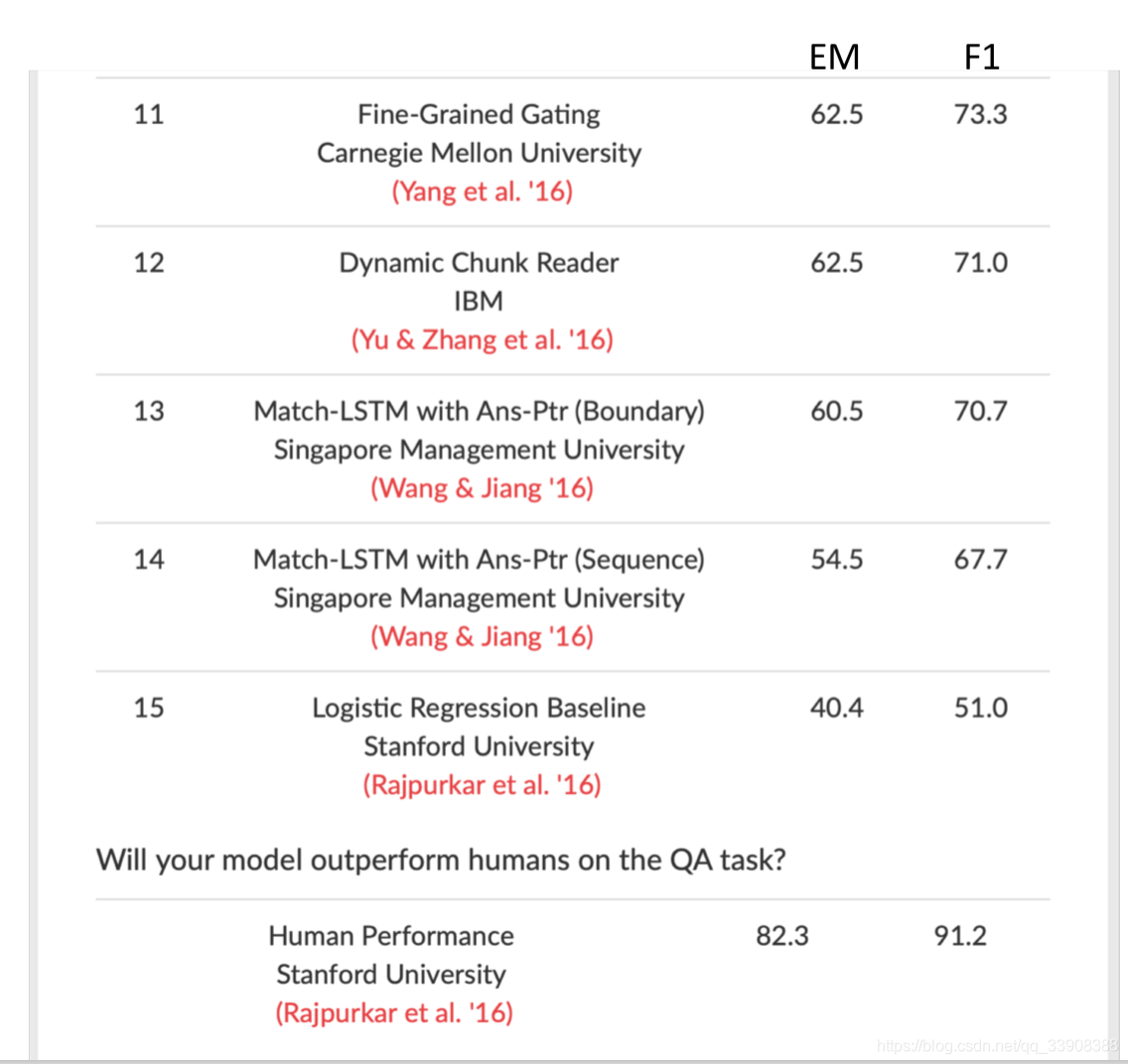
2016年12月6号各个模型在SQuAD数据集上的排行榜:
最底下的是人类的分数,EM,F1是上面提到的两个评价指标
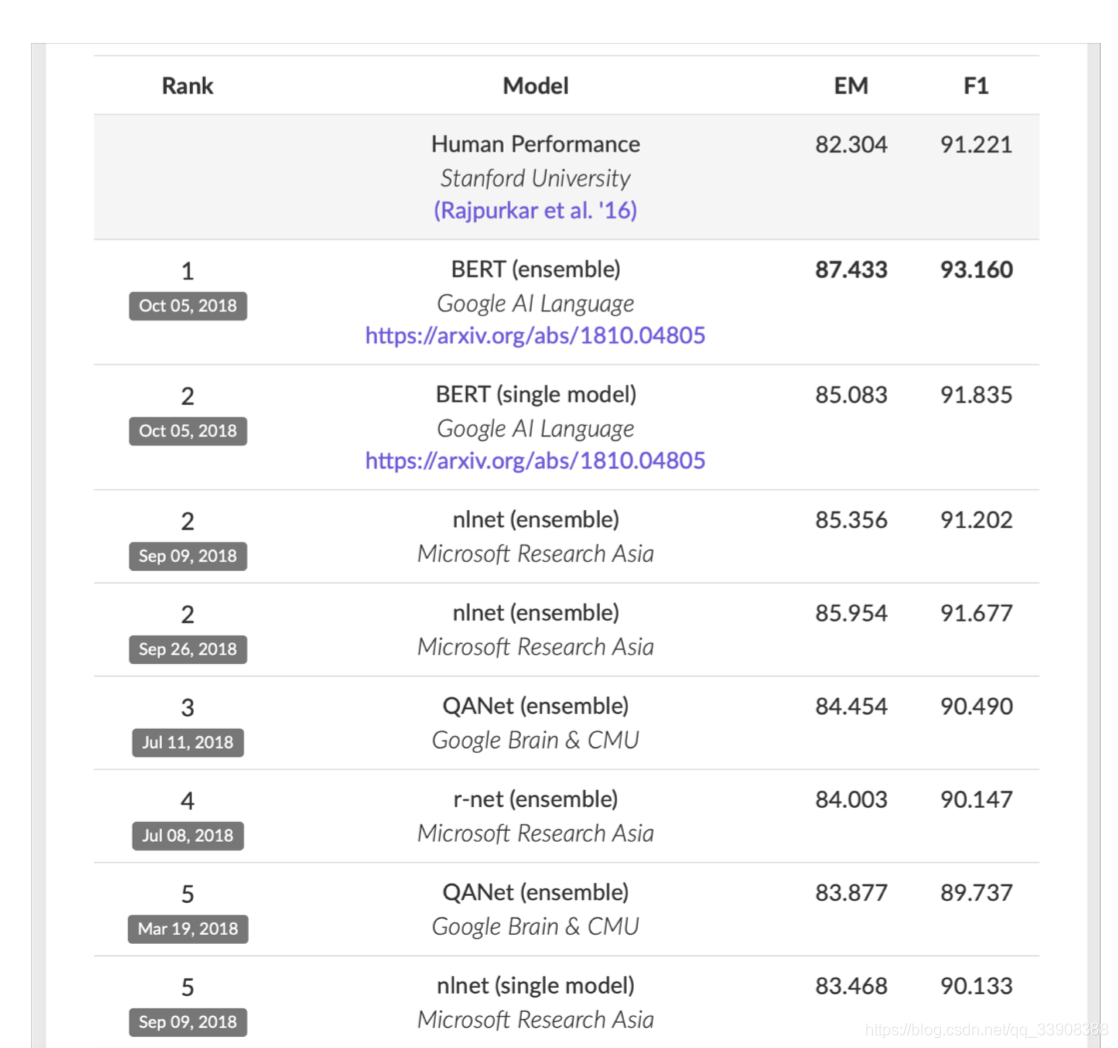
2019年02月07日的榜单:
机器的分数首次超过了人类的分数,bert的出现是一次革命
SQuAD 2.0
- 1.0的数据集中所有的问题都在段落中能找到答案
- Systems (implicitly) rank candidates and choose the best one(不懂怎么翻译)
- You don’t have to judge whether a span answers the question(不懂怎么翻译)
- 2.0中,1/3的训练数据没有答案,1/2的验证集和测试集数据没有答案 。对于没有答案的例子来说,如果回答没有答案,分数是1,否则是0,对EM和F1来说都是如此
- 实现了一个基本的系统,得出一个分数,将这个分数作为阈值分数
- 四、斯坦福的Attentive Reader
使用了双向LSTM
结合注意力机制预测了答案的开始位置(start标识符)和结束位置(end标识符)
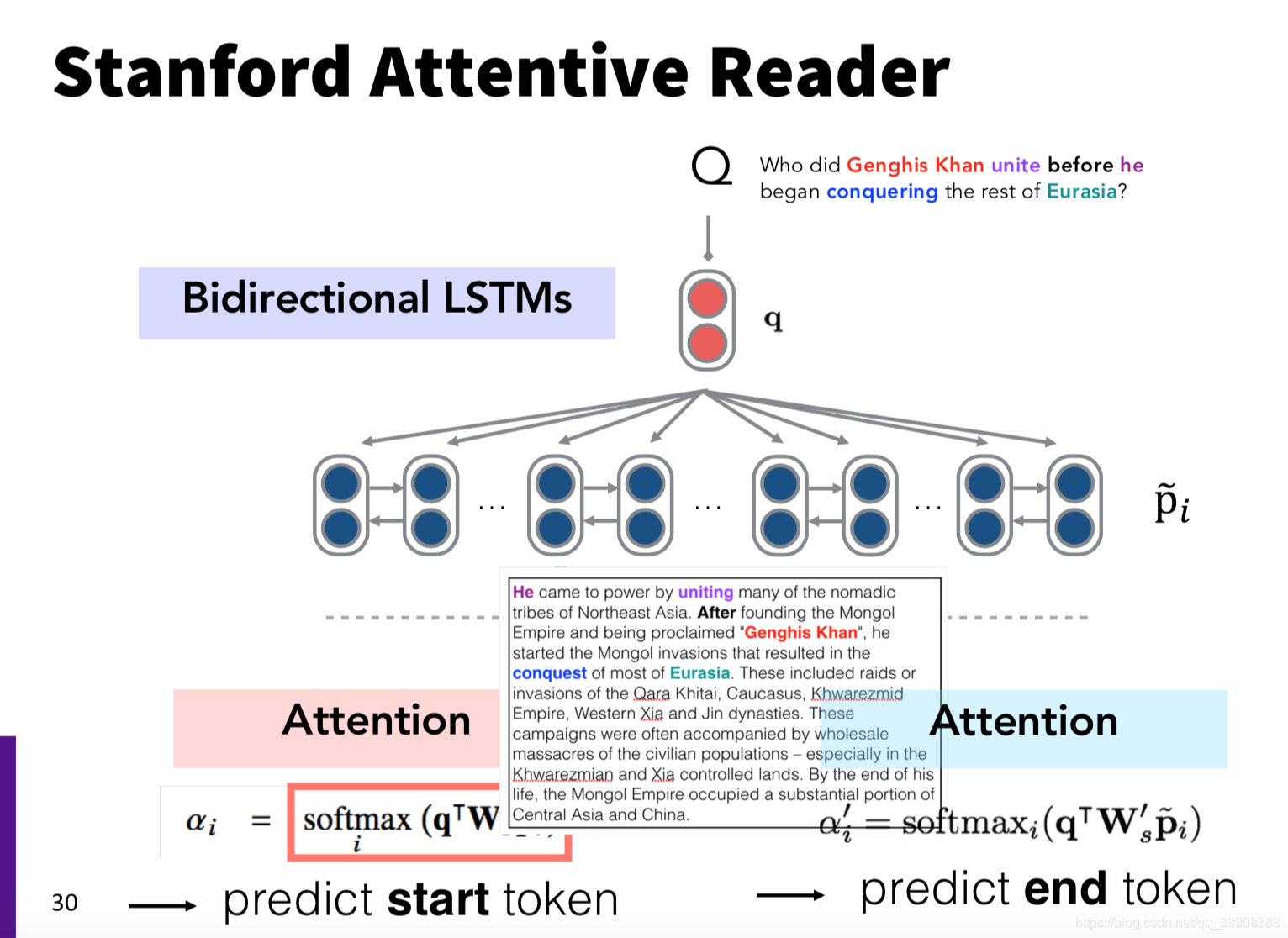
第一层使用glove模型进行词嵌入表示,将问题和文本进行相似度比较
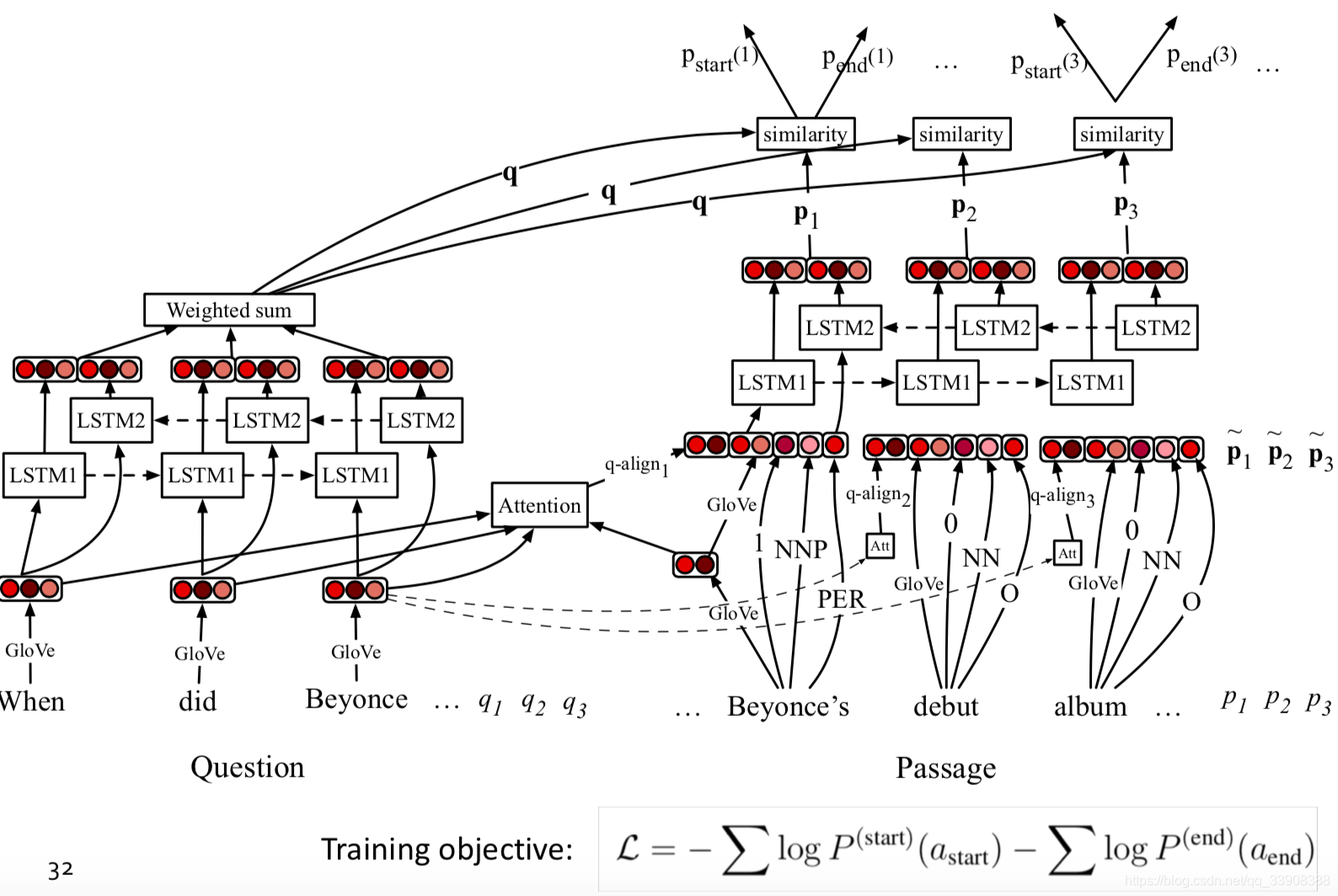
(不是很理解)
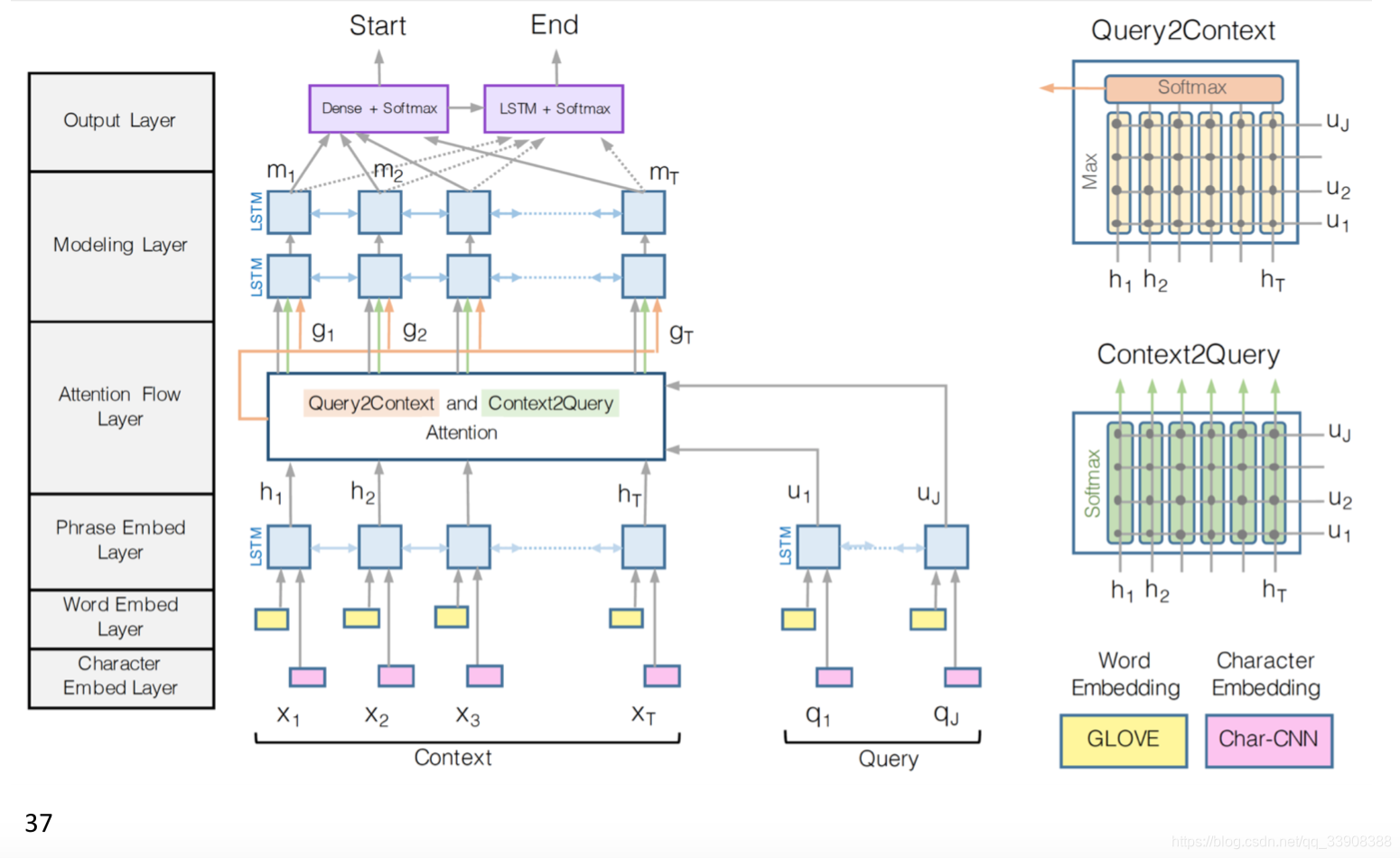
五、BiDAF:Bi-Directional Attention Flow for Machine Comprehension
最主要的突破是:注意力流层
注意力应该从两个方面流动:从文本到问题和从问题到文本
计算一个相似矩阵:
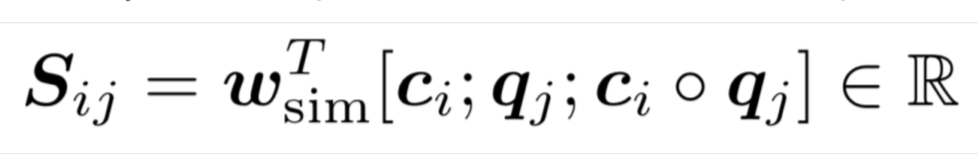
文本到问题的注意力:问题中的单词和每个文本的单词的相关性

问题到文本的注意力:
衡量出文本中最重要的单词,和问题相对应
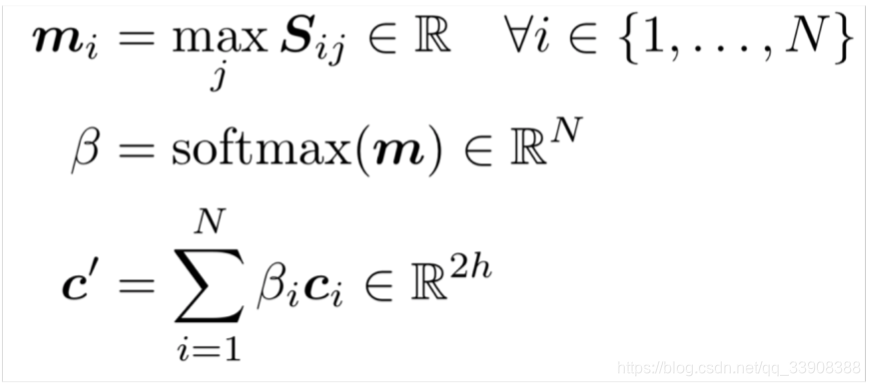
六、最近的更先进架构
1、用于回答问题的动态共注意网络:Dynamic Coattention Networks for Question Answering
缺点:问题具有独立于输入的表示
全面的QA模型需要相互依赖
2、FusionNet
多层内部注意力机制
(这节课ppt上给的内容不多,只听英文授课和字幕有点不太懂。打算二刷再来更新)
七、bert
没讲什么


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









