







 本文介绍如何选择自然语言处理项目及数据集,包括项目类型的建议、数据集来源、机器翻译模型及其评估方法等内容。
本文介绍如何选择自然语言处理项目及数据集,包括项目类型的建议、数据集来源、机器翻译模型及其评估方法等内容。
主要内容:
- 项目的选择:可以选择默认的问答项目,也可以自定义项目
- 如何发现自定义项目
- 如何找到数据集
- 门神经网络序列模型的复习
- 关于机器翻译的一些话题
- 查看训练结果和进行评估
一、项目的选择
默认项目:在SQuAD上构建一个文本问答系统
数据集地址SQuAD2.0:https://rajpurkar.github.io/SQuAD-explorer/
二、找到自己感兴趣的项目
找到一个感兴趣的领域的问题找到一个比现有的解决办法更好的办法
以一个感兴趣的技术方法开始,找到好的方法扩展或者提升它,或者是一个新的方法实现它
项目的类型:
找到一个感兴趣的应用或者任务,探索怎么通过已有的神经网络模型高效的实现它
实现一个复杂的神经架构证明它在一些新数据上的性能
提出一个新的或者变体的神经网络模型然后探索它的应用
分析项目。分析模型的行为,它的逻辑是怎么展开的,它能处理什么或者它可能会产生什么错误
罕见的理论项目,展示一些有趣的,没有见过的模型类型,数据或者数据表示
如何找到一个有趣的项目?
查看NLP论文的ACL选集:(ACL:The Association for Computational Linguistics Member Portal)
https://aclanthology.info
查看主要的机器学习会议的线上过程:
-
NeurIPS, ICML, ICLR
查看过去的cs224n的项目
查看课程网站
查看论文的预收录网站:
-
https://arxiv.org
这个网站的作用是:我们会将预稿上传到arvix作为预收录,因此这就是个可以证明论文原创性(上传时间戳)的文档收录网站。
http://www.arxiv-sanity.com(好像是斯坦福大学自己构建的网站?)
三、找到数据集
- 一些人为项目收集自己的数据
- 一些人从一个研究项目或者公司里获取数据
- 大部分人使用前人构建好的数据集
- 语言数据:
https://catalog.ldc.upenn.edu/
- 斯坦福大学的数据集:
- 机器翻译的数据:
http://statmt.org
- 依存分析:
https://universaldependencies.org
- 还有很多其他的途径找到数据集:
kaggle
- 研究论文
https://machinelearningmastery.com/datasets-natural-language-processing/
https://github.com/niderhoff/nlp-datasets
四、回顾门循环单元和机器翻译
梯度消失的原因:
反向传播时会经过所有直接相连的节点
可以通过给不相邻的节点增加一条路径的方式解决,使得信息不会丢失
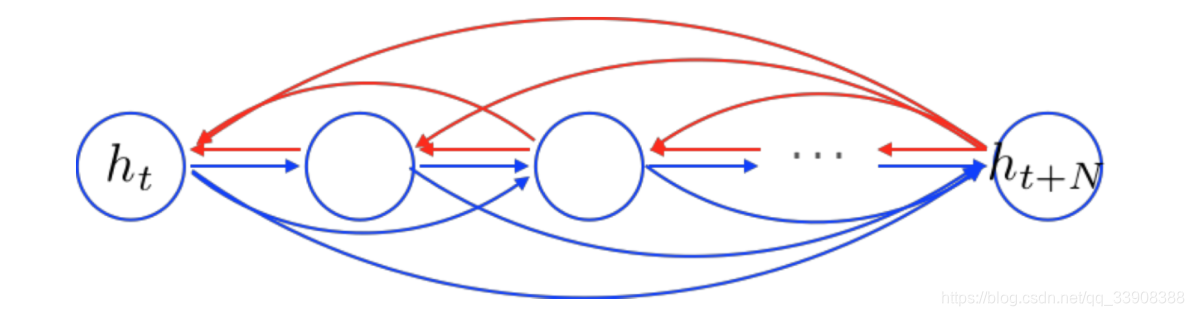
单词生成的过程中出现的问题:
单词库太大,训练时间很长
有些单词在单词库中不存在,所以翻译生成的是<unk>的形式

机器翻译的评估
- 人工评估
- 测试下游任务的性能
- 自动评估:
BLUE
BLUE的评估方法:(目前还不太理解这个方法的原理和应用)
n-gram精度
项目开展:
- 确定任务
- 确定数据集:寻找学术数据集,它们已经定义好了baselines,比如Newsroom Summarization Dataset:https://summari.es
- 确定自己的数据集,应该是要从上述数据集中抽取出自己需要的部分
- 分割数据集:训练集、验证集、测试集
- 定义评价指标
- 建立一个基线:
- 先实现最简单的模型(通常是在unigram或者平均词向量上实现逻辑回归)
- 评估模型
- 分析错误
- 继续开始
- 应用现有的神经网络模型
- 可视化数据,收集总结数据,查看错误,分析超参数
关于RNN训练的建议:


















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









