







参考博客:https://ai.yanxishe.com/page/TextTranslation/1971
1、梯度下降
2、小批量梯度下降
-
当batch_size = 训练集样本数时,这被称为批量梯度下降。此时会有遍历整个数据集后才开始学习的问题。
-
当batch_size = 1时,称为随机梯度下降。它没有充分利用矢量化,训练变得非常缓慢。
-
因此,通常的选择是64或128或256或512。这取决于具体案例和系统内存,如我们应该确保一个min-batch应该能够装入系统内存。
3、动量梯度下降法
为什么需要动量梯度下降法呢?
因为在使用小批量随机梯度下降时,每个小批量求的梯度与全批量的梯度是有差别的,就会导致梯度震荡,虽然总体是往最优梯度的方向走的。动量梯度下降是为了减缓梯度的震荡。

先介绍一个概念:指数加权平均。
指数加权平均中的指数表示各个元素所占权重呈指数分布。假设存在数列:
{Q1,Q2,Q3,Q4...........}
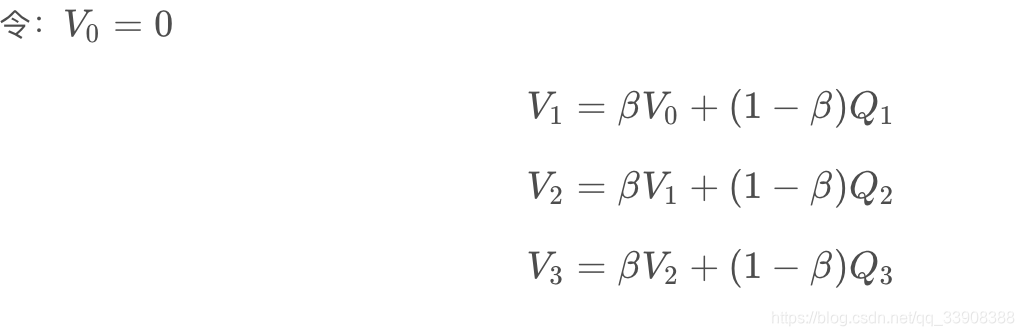

观察各项前面的系数不难得到从Q1到Q100 各数权重呈指数分布。
可以看出指数加权平均是有记忆平均,每一个V VV都包含了之前所有数据的信息。
接下来介绍动量梯度下降法:
回顾一下梯度下降法每次的参数更新公式:
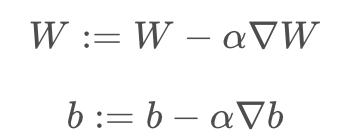

梯度更新的公式变为:
![]()
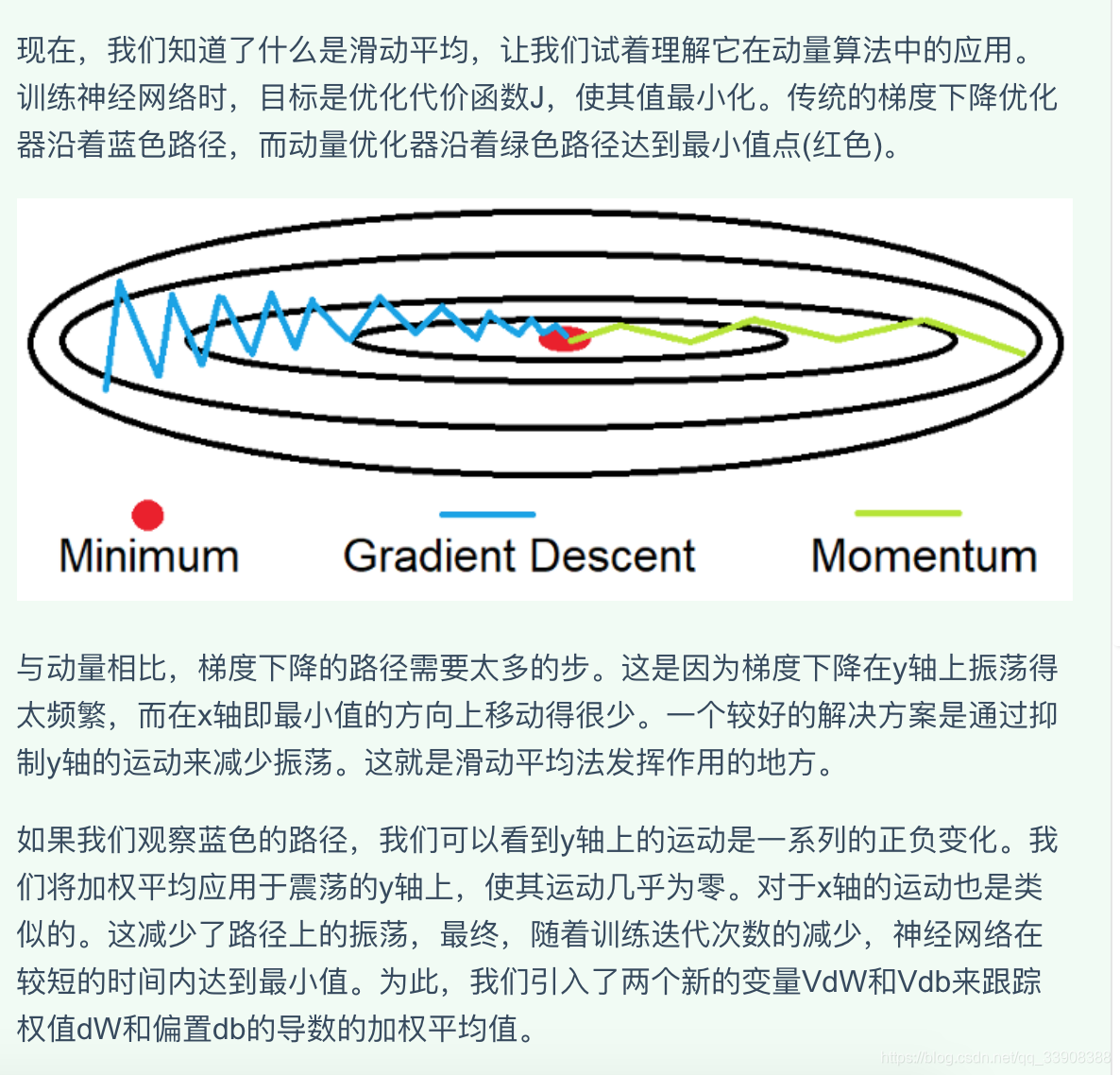
4、RMSProp均方根传播法
与动量类似,它是一种抑制在y轴上运动的技术
直觉告诉我们,当我们用一个大数除以另一个大数时,结果会变得很小。在我们的例子中,第一个大数是db,第二个大数是db的加权平均值²。我们引入了两个新的变量Sdb和SdW,以跟踪db²和dW²的加权平均。db和Sdb相除会得到一个更小的值,它抑制了在y轴上的运动。其中引进ε是为了避免除0异常情况。对于W的更新也是类似,也就是x轴上的值。
5、AdaM代表自适应动量法
它将Momentum法和RMSprop法结合一起,使Adam成为一个非常强大和快速的优化器。并利用误差修正方法解决加权平均计算中的冷启动问题,也就是加权平均值的前几个值与实际值相差太远。V和S分别源自于Momentum和RMSprop。
值得注意的是,在计算时,我们用了2个不同的β值。β1用于计算Momentum相关的部分,而β2用于计算RMSprop相关的部分。同样,我们仍然可以使用基于小批量方法的AdaM优化器,因为只有参数更新方法发生了更改。
这个论文感觉也没有讲的很清楚,看完了的我还是不是很理解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









