







 本文是作者对Faster R-CNN中Anchor机制的学习笔记,详细解释了从RCNN到Faster R-CNN的演进,特别是Faster R-CNN中Region Proposal Network如何通过Anchor生成提案。在Feature Maps上进行3*3卷积,结合不同比例和尺度产生9种Anchor Box,并通过分类和回归层确定其前景/背景概率及位置信息。
本文是作者对Faster R-CNN中Anchor机制的学习笔记,详细解释了从RCNN到Faster R-CNN的演进,特别是Faster R-CNN中Region Proposal Network如何通过Anchor生成提案。在Feature Maps上进行3*3卷积,结合不同比例和尺度产生9种Anchor Box,并通过分类和回归层确定其前景/背景概率及位置信息。
第一篇学习记录博客。
主要写一下自己对Faster rcnn中anchor机制的理解,便于以后查阅。
因为最近在看cvpr2019的anchor-free的FSAF,核心即anchor,对这个理解不透彻,所以回来搞搞清楚。
水平有限,有什么错误,希望大家指正。
一、Rcnn→Fast Rcnn→Faster Rcnn
RCNN:用Selective Search 方法直接在图像上画框框(region proposal:理解为区域提名,就是提名这个框框里可能有目标),然后对每个框框内的图像提取特征,再把特征送入SVM分类器进行分类(看看这个框框里的目标是哪一类),再使用回归器对这个框框的位置进行修正。
Fast RCNN:嫌弃RCNN太慢太慢了,每个框框都提一遍特征,但是很多框框有重叠啊!这样就等于做了很多重复计算。那对整个图像提完特征再在特征图上画框框岂不是更好?于是在SSPNet上改进,做了classification和regression,端到端进行训练。但是画框框(proposal)还是用Selective Search方法。
Faster RCNN:就是把proposal的过程也交给了CNN!也就是Region Proposal Network(RPN)
二、Faster Rcnn
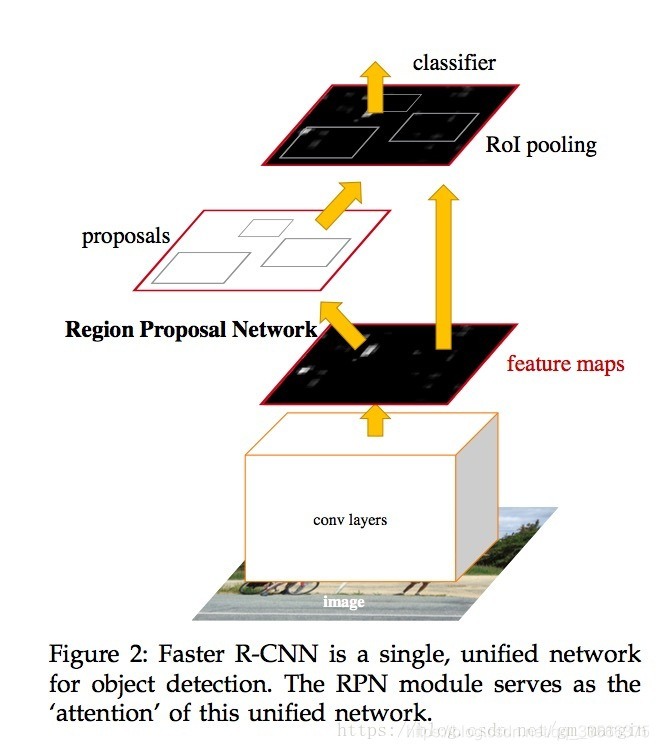
image→conv layers→feature maps
feature maps送入RPN
那么RPN如何产生proposal呢?
看下面这张图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5923
5923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









