









 本文提出了一种新颖的两流Transformer模型,用于骨架数据的人体行为识别。通过空间自注意力模块(SSA)理解和捕捉不同身体部位之间的帧内交互,而时间自注意力模块(TSA)则建模关节随时间的动态相关性。实验在NTU RGB+D 60和NTU RGB+D 120数据集上超越了当前最佳模型,证明了该方法的有效性。
本文提出了一种新颖的两流Transformer模型,用于骨架数据的人体行为识别。通过空间自注意力模块(SSA)理解和捕捉不同身体部位之间的帧内交互,而时间自注意力模块(TSA)则建模关节随时间的动态相关性。实验在NTU RGB+D 60和NTU RGB+D 120数据集上超越了当前最佳模型,证明了该方法的有效性。
Spatial Temporal Transformer Network for Skeleton-based Action Recognition
Author and Department
Chiara et. al. 米兰理工大学,意大利; 发表在上ICPR,2020.
论文有代码,但是复现不正确,之后跟踪继续。
目 录
文章目录
Abstract
分为三个部分:1.background 2.motivation 3.method 4. conclusion
-
Background: Skeleton data has been demonstrated to be robust to illumination changes(光线变化) etc. Nevertheless, an effective encoding of the latent information underlying the 3D skeleton is still an open problem(虽然骨架数据对于复杂环境鲁棒性较强,但是对于3D数据潜在信息的有效编码仍然是个问题)
-
Motivation:I think rubbing Transformer’s hotness. In addition, The existing methods ignore the correlation between joint pairs.
-
Method:Spatial-Temporal Transformer network(ST-TR)
-
Spatial Self-Attention module (SSA): Understand intra-frame interactions between different body parts;
-
Temporal Self-Attention module (TSA):model inter-frame correlations.
-
-
Conclusion:A two-stream network which outperforms state-of-the-art models on both NTU-RGB+D 60 and NTU-RGB+D 120.
Summary
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。注:写文章summary切记需要通过自己的思考,用自己的语言描述。忌讳直接Ctrl + c原文。
Research Objective(s)/Motivation
作者目的是通过Spatial Self-Attention module (SSA) 和Temporal Self-Attention module (TSA) 提取自适应低层特征,建模人类行为中的交互。
Contribution
-
Author propose a novel two-stream Transformer-based model (both the Termporal and spatial dimensions)
-
Spatial Self-Attention (SSA) & Temporal SelfAttention (TSA)
-
SSA module dynamically build links between skeleton joints, 该模块获取人体各部分之间的关系,与动作有关,而非完全遵守自然人体关节结构。
-
TSA study the dynamics of joints along time.
-
Background / Problem Statement(Introduction)
Problem Statement
- The topology of the graph representing the human body is fixed for all layers and actions, preventing the extraction of rich representations(图表示人体的拓扑结构都是固定的,不能够提取丰富的表达)
- 时空卷积都是基于2D卷积的,所以都受限于局部邻居的特征影响;
- correlations between body joints not linked in the human skeleton(人体的关节点未连接的部分同样有关联性)。
Method(s)
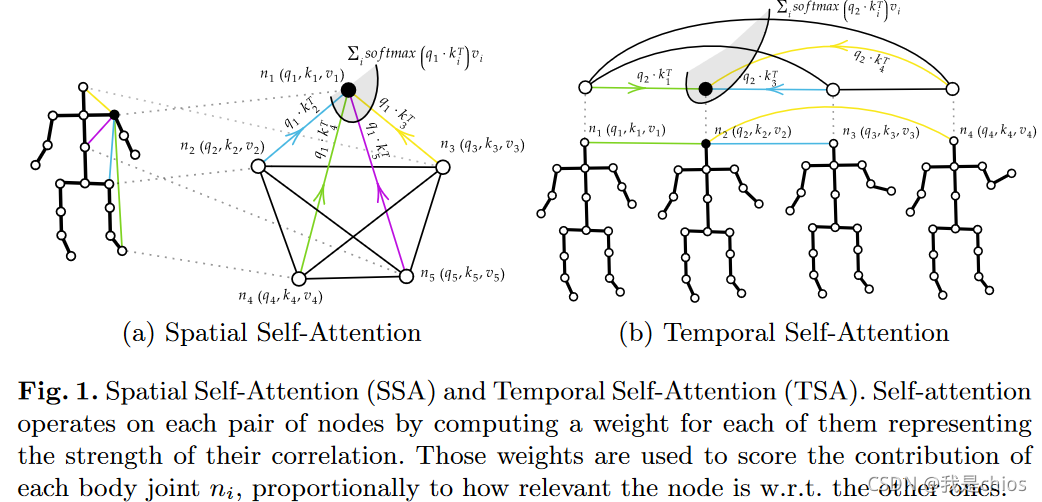
Spatial Self-Attention (SSA)
如图1(a)所示, first calculate
q
i
t
∈
R
d
q
q_i^t\in \mathcal{R}^{dq}
qit∈Rdq,
k
i
t
∈
R
d
q
k_i^t\in \mathcal{R}^{dq}
kit∈Rdq and
v
i
t
∈
R
d
q
v_i^t\in \mathcal{R}^{dq}
vit∈Rdq;Then, 计算a query-key dot product 获取权重
α
i
,
j
t
∈
m
a
t
g
h
\alpha_{i,j}^t\in matgh
αi,jt∈matgh(权重代表两个节点之间的关联性强度)。
a weighted sum is computed to obtain a new embedding for node
i
t
i^t
it(
∑
\sum
∑的目的是为了获取节点新的嵌入)
a
i
.
j
t
=
q
i
t
⋅
k
j
t
T
,
∀
t
∈
T
,
z
i
t
=
∑
j
s
o
f
t
m
a
x
j
(
a
i
.
j
t
d
k
)
v
j
t
(1)
a_{i.j}^t=\mathbf{q_i^t}\cdot \mathbf{k_j^t}^T,\forall{t}\in T, \mathbf{z}_i^t=\sum_jsoftmax_j(\frac{a_{i.j}^t}{\sqrt{d_k}})\mathbf{v}_j^t\tag{1}
ai.jt=qit⋅kjtT,∀t∈T,zit=j∑softmaxj(dkai.jt)vjt(1)
Multi-head 自注意力经过重复H次嵌入提取过程,每次采用不同集合的学习参数。,从而获得节点嵌入 z i 1 t , … , z i H t z_{i_1}^t,…,z_{i_H}^t zi1t,…,ziHt,所有参考 i t i^t it,如 c o n c a t ( z i 1 t , … , z i H t ) ⋅ W O concat(z_{i_1}^t,…,z_{i_H}^t)\cdot W_O concat(zi1t,…,ziHt)⋅WO,并且构成SSA的输出特征。
总结,这部分就是为了获取节点与其他节点在空间中的特征聚合
因此,如图1a所示,节点的关系( a i . j t a_{i.j}^t ai.jt score)动态的预测;所有动作的关系结构并不是固定的,都是随着样本自适应改变。SSA操作和全连接的图卷积相似,但是核心values( a i . j t a_{i.j}^t ai.jt score)是基于骨架动作动态预测的。
Temporal Self-Attention (TSA)
a
i
.
j
v
=
q
i
v
⋅
k
j
v
,
∀
v
∈
V
,
z
i
v
=
∑
j
s
o
f
t
m
a
x
j
(
a
i
.
j
v
d
k
)
v
j
v
(2)
a_{i.j}^v=\mathbf{q_i^v}\cdot \mathbf{k_j^v},\forall{v}\in V, \mathbf{z}_i^v=\sum_jsoftmax_j(\frac{a_{i.j}^v}{\sqrt{d_k}})\mathbf{v}_j^v\tag{2}
ai.jv=qiv⋅kjv,∀v∈V,ziv=j∑softmaxj(dkai.jv)vjv(2)
i
v
,
j
v
i^v,j^v
iv,jv分别表示节点v在时刻i,j的情况。其他和SSA一样。
Two-Stream Spatial Temporal Transformer Network
既然有了SSA和TSA,那么下一步就是为了合并。
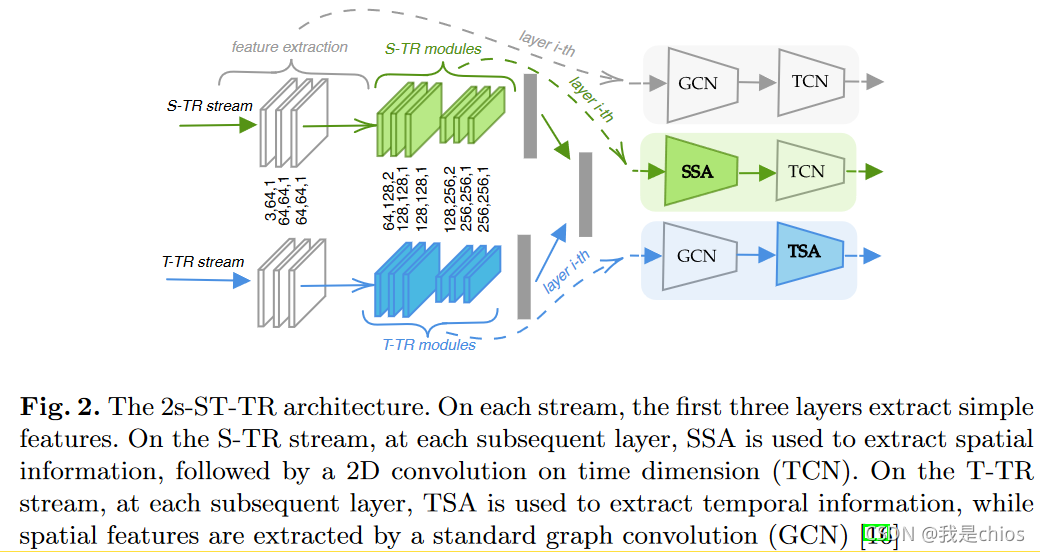
作者分别用SSA和TSA代替ST-GCN中的GCN和TCN
Spatial Transformer Stream (S-TR)
S
−
T
R
(
x
)
=
C
o
n
v
2
D
(
1
×
K
t
)
(
S
S
A
(
x
)
)
\mathbf{S-TR}(x)=Conv_{2D(1\times K_t)}(\mathbf{SSA}(x))
S−TR(x)=Conv2D(1×Kt)(SSA(x)). Following the original Transformer structure,Batch Normalization layer and skip connections are used。
Temporal Transformer Stream (T-TR)
T − T R ( x ) = T S A ( G C N ( x ) ) \mathbf{T-TR}(x)=\mathbf{TSA}(GCN(x)) T−TR(x)=TSA(GCN(x)).
Experiments
++Datasets++:NTU RGB+D 60 and NTU RGB+D 120.
Ablation Study
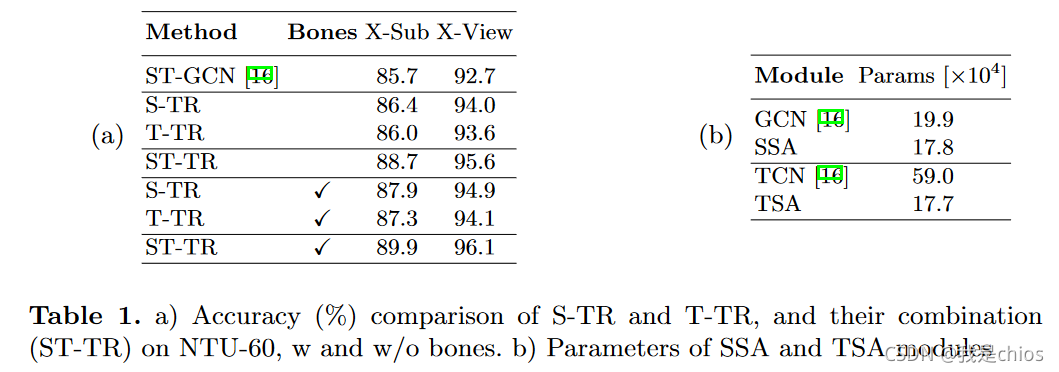
STR stream achieves slightly better performance(+0.4%) than the T-TR stream. 原因:S-TR的SSA只有25个关节点,而时间维度相关需要大量的帧。并且在参数方面也是下降了的
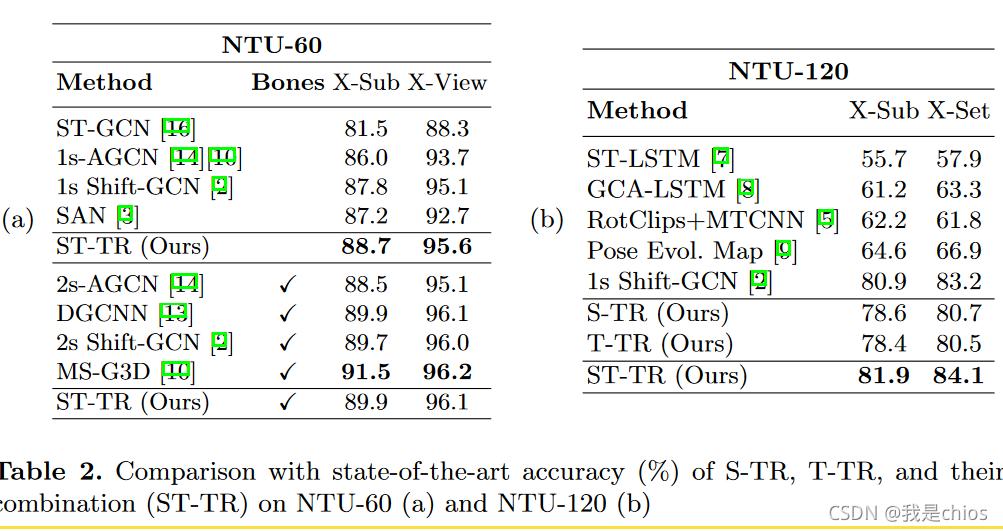
其中“playing with phone”,“typing”, and “cross hands” on S-TR 收益最大,上时间关联或者两个人的如:“hugging”, “point finger”, “pat on back”, on T-TR收益最大。
References(optional)
[1] Cho, S., Maqbool, M., Liu, F., Foroosh, H.: Self-attention network for skeletonbased human action recognition. In: The IEEE Winter Conference on Applications of Computer Vision. pp. 635–644 (2020)
[2]Zehui, L., Liu, P., Huang, L., Fu, J., Chen, J., Qiu, X., Huang, X.: Dropattention: A regularization method for fully-connected self-attention networks. arXiv preprint arXiv:1907.11065 (2019)
下一步任务,代码解析,因为代码复现目前有问题,还在进一步调整

















 4445
4445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









