









前言
最近Transformer很火,从NLP一直烧到了图像领域,不得不仔细研读一番。还记得初始看到Transformer在骨架识别应用是在2020年初疫情在家的时候,中科院Lei shi等人去除骨架中骨骼先验信息,采用Transformer自注意力寻找骨骼节点之间的关联性,当时感觉作者思路很惊奇。但是基于当时的理解,认为这仅仅是对Non-Local的一种泛化,没有细究,现在仔细想来,错过了一次技术热潮。算是一种教训,在今后学习中应该谨记,善于发现创新潮。
本文为Transformer系列最原始文章,其他文章后续更新。
Transformer: Attention is all your need
Informer
Performer
Reformer
Graph Transformer Networks
Vision Transformer
SETR
Transformer in Transformer
Attention is not all your need
Self-Attention Attribution
基础知识
自从Attention机制提出之后,Seq2seq模型在许多任务中都得到了提升,在Transformer之前,大多数方法都是RNN和attention的结合。然而,传统RNN一直被人诟病的收敛慢问题难以解决。为此,Transformer抛开了传统的CNN和RNN结构,利用self-attention机制实现快速并行,而且可以大幅增加模型深度,提升模型准确率。
物理意义
Transformer最早应用于机器翻译,类似于黑箱操作,如图1所示,输入为法语(我是一个学生),输出为英文。

黑箱里面到底是什么呢?非研究人员不必知道,能用就行,但是为了更好地剖析模型,本文将继续细化模型。如图2所示,Transformer采用了NLP最常用的Encoder-Decoder架构。


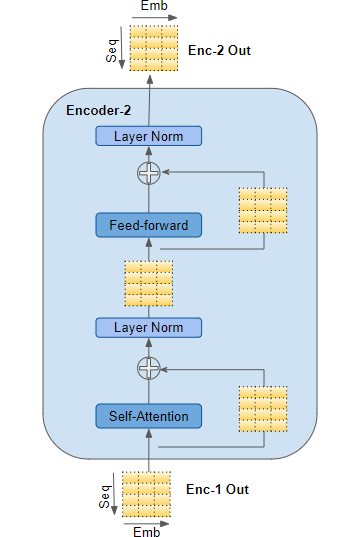
编码器和解码器堆栈各自具有用于其各自输入的对应嵌入层,编码层和解码层分别有3层,经过3层编码层后结果分别送入不同的解码层中(类似于残差),作者充分利用了Res模块,每一块都加入了残差单元,如图3所示。

具体编码和解码模块如图4所示:
- 编码器包含最重要的自我注意层和前馈层,前者用于计算序列中不同单词之间的关系,后者用于参数训练。
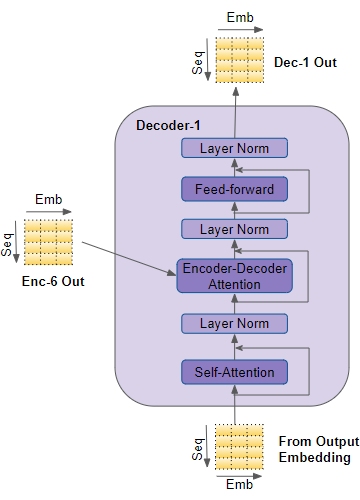
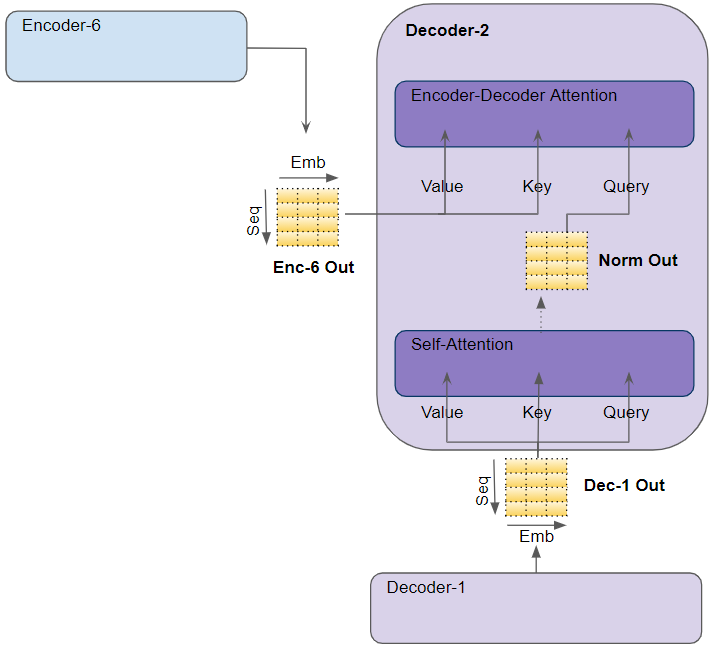
- 解码器与编码器唯一不同点在于增加了Encoder-Decoder Attention模块。
- Encoder-Decoder注意层的工作方式类似于Self-attention,不同之处在于它组合了两个输入源-位于其下方的Self-attention层以及Encoder堆栈的输出。
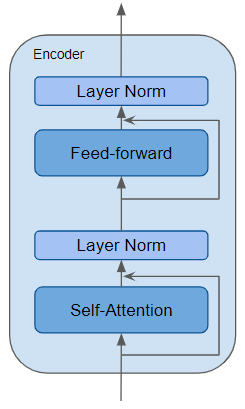
编码器是可重用的模块,是所有Transformer体系结构的定义组件。除了上述两层之外,它还具有围绕两个层以及两个LayerNorm层的残差跳过连接,见图5。
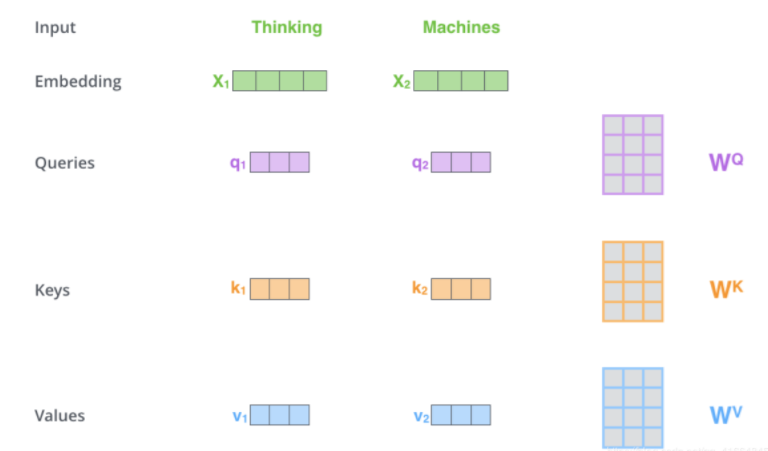
Transformer中的Q,K,V的理解
Query,Key,Value概念来源与信息检索系统,如某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,搜索引擎上输入的内容便是Query,然后搜索引擎会根据Query匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。–参考12
Q:查询向量
K:表示被查询信息与其他信息的相关性的向量
V:表示被查询信息的向量个人理解类似于soft查询方式
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \begin{split} …
x x x对应信息 V V V的注意力权重 与 Q × K T Q \times K^T Q×KT 成正比
eq: x x x的注意力权重,由 x x x自己来决定,所以叫自注意力。 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv会根据任务目标更新变化,保证了自注意力机制的效果。 以下是点乘自注意力机制的公式。
自注意力机制
Transformer突破性表现的关键是对注意力的使用(自注意力机制更早出现,很多人都用过,NL block就是应用之一)。
起源:Transformer体系结构通过将输入序列中的每个单词与其他每个单词相关联来使用自我注意。
句子:
-
猫喝牛奶是因为它肚子饿了。
-
猫喝牛奶是因为它很甜。
上面两个句子,“它”分别表示猫和牛奶。人很容易判断,但对计算机来说,太难了。
所以需要用到自注意力,通过句子本身查找它的含义。
计算self attention的第二步是计算得分。以上图为例,假设我们在计算第一个单词“thinking”的self attention。我们需要根据这个单词对输入句子的每个单词进行评分。当我们在某个位置编码单词时,分数决定了对输入句子的其他单词的注意程度。
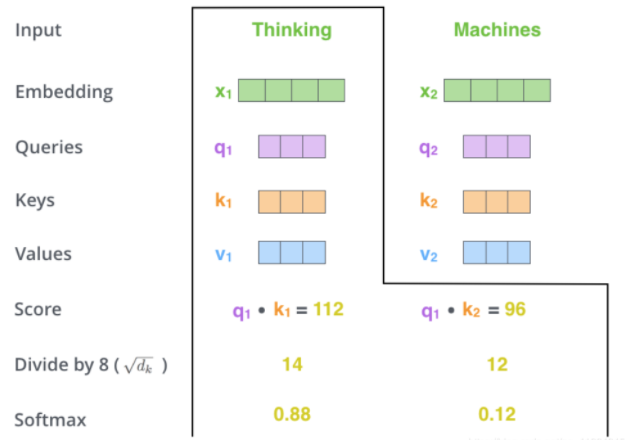
第三步和第四步的计算,是将第二部的得分除以8 d k \sqrt{d_k} dk(论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。这个 d k \sqrt{d_k} dk并不是唯一值,经验所得)。然后再将得到的输出通过softmax函数标准化,使得最后的列表和为1。
这个softmax的分数决定了当前单词在每个句子中每个单词位置的表示程度。很明显,当前单词对应句子中此单词所在位置的softmax的分数最高,但是,有时候attention机制也能关注到此单词外的其他单词,这很有用。

第五步是将每个Value向量乘以softmax后的得分。这里实际上的意义在于保存对当前词的关注度不变的情况下,降低对不相关词的关注。
第六步是 累加加权值的向量。 这会在此位置产生self-attention层的输出(对于第一个单词)。
具体流程动图如下:

一文读懂Transformer模型的位置编码 - 知乎 (zhihu.com)
Why: 为什么需要位置编码?
引入位置编码原因有二:
-
对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。
-
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
位置编码(Positional Encoding)是一种用词的位置信息对序列中的每个词进行二次表示的方法。Transformer模型本身不具备像RNN那样的学习词序信息的能力,需要主动将词序信息喂给模型。那么,模型原先的输入是不含词序信息的词向量,位置编码需要将词序信息和词向量结合起来形成一种新的表示输入给模型,这样模型就具备了学习词序信息的能力。
How:如何实现?
1.位置编码的一种做法就是分配一个0到1之间的数值给每个时间步,其中,0表示第一个词,1表示最后一个词。这种方法虽然简单,但会带来很多问题。其中一个就是你无法知道在一个特定区间范围内到底存在多少个单词。换句话说,不同句子之间的时间步差值没有任何的意义。
2.另一种做法就是线性分配一个数值给每个时间步。也就是,1分配给第一个词,2分配给第二个词,以此类推。这种方法带来的问题是,不仅这些数值会变得非常大,而且模型也会遇到一些比训练中的所有句子都要长的句子。此外,数据集中不一定在所有数值上都会包含相对应长度的句子,也就是模型很有可能没有看到过任何一个这样的长度的样本句子,这会严重影响模型的泛化能力。
位置编码方案需要满足以下几条要求:
- 它能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的;
- 它必须是确定性的。
Transformer的作者们提出了一个简单但非常创新的位置编码方法,能够满足上述所有的要求。首先,这种编码不是单一的一个数值,而是包含句子中特定位置信息的 d d d维向量(非常像词向量)。第二,这种编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息。换句话说,通过注入词的顺序信息来增强模型输入。
给定长度为
n
n
n的输入序列,让
t
t
t表示词在序列中的位置,
p
t
⃗
∈
R
d
\vec{p_t}\in\mathbb{R}^d
pt∈Rd表示t位置的对应向量,
d
d
d是向量维度。
f
:
N
→
R
d
f:\mathbb{N}\rightarrow\mathbb{R}^d
f:N→Rd是生成位置向量
p
t
⃗
\vec{p_t}
pt的函数,定义如下:
p
t
⃗
(
i
)
=
f
(
t
)
(
i
)
=
{
s
i
n
(
w
k
⋅
t
)
if
(
i
=
2
k
)
c
o
s
(
w
k
⋅
t
)
if
(
i
=
2
k
+
1
)
\vec{p_t}^{(i)}=f(t)^{(i)}=\begin{cases} sin(w_k\cdot t)& \text{if}({i=2k})\\ cos(w_k\cdot t)& \text{if}({i=2k+1}) \end{cases}
pt(i)=f(t)(i)={sin(wk⋅t)cos(wk⋅t)if(i=2k)if(i=2k+1)
其中。频率
w
k
w_k
wk定义如下:
w
k
=
1
1000
0
2
k
d
w_k=\frac{1}{10000^{\frac{2k}{d}}}
wk=10000d2k1
不同维度上应该用不同的函数操纵位置编码,这样高维的表示空间才有意义。
从函数定义中可以看出,频率沿向量维度减少。因此,在波长上形成从 2 π 2\pi 2π到 10000 ⋅ 2 π 10000\cdot 2\pi 10000⋅2π几何级数。
位置编码
p
t
⃗
\vec{p_t}
pt包含每个频率的正弦对和余弦对(d是可以被2整除)。
p
t
⃗
=
[
sin
(
w
1
⋅
t
)
cos
(
w
1
⋅
t
)
sin
(
w
2
⋅
t
)
cos
(
w
2
⋅
t
)
⋮
sin
(
w
d
2
⋅
t
)
cos
(
w
d
2
⋅
t
)
]
\begin{gathered} \vec{p_t}=\begin{bmatrix} \sin(w_1\cdot t) \\ \cos(w_1\cdot t) \\ \sin(w_2\cdot t) \\ \cos(w_2\cdot t) \\ \vdots \\ \sin(w_{\frac{d}{2}}\cdot t) \\ \cos(w_{\frac{d}{2}}\cdot t) \end{bmatrix} \end{gathered}
pt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(w1⋅t)cos(w1⋅t)sin(w2⋅t)cos(w2⋅t)⋮sin(w2d⋅t)cos(w2d⋅t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
性质1
对于固定偏移量k和位置t, P E t T P E t + k PE_t^TPE_{t+k} PEtTPEt+k取决于 k k k,也就是说两个位置编码的点积可以反映两个字间的距离。
性质2
对于偏移量k和位置t, P E t T P E t − k = P E t T P E t + k PE_t^TPE_{t-k}=PE_t^TPE_{t+k} PEtTPEt−k=PEtTPEt+k,意味着这种位置向量的编码是没有方向性的。
具体证明过程可参见邱希鹏老师论文
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
# Not a parameter
# register_buffer()向模块添加持久缓冲区。
# 这通常用于注册不应被视为模型参数的缓冲区
# 这部分不用做模型参数训练和反向传播
# d_hid 表示d(输入句子的维度,也就是单词embeding维度)
# n_position表示时间t
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
# 等价于self.pos_table = self._get_sinusoid_encoding_table(n_position, d_hid).register_buffer
def _get_sinusoid_encoding_table(self, n_position, d_hid):
''' Sinusoid position encoding table '''
# TODO: make it with torch instead of numpy
def get_position_angle_vec(position):
'''
"//"向下取整操作相当的给力!!!
这里的向下取整确保1,...d/2分别求sin和cos
$10000^{2i/d_{model}}$
'''
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])#[1,2,...,n_position]->[t/1,t/{10000^{2/d_{model}},...]
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 0::2表示从0开始,间隔为2
# [sin(pos/10000^{2i/d})]
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
# [sin(pos/10000^{(2i+1)/d})]
# dim = [n_position, d_hid//2]
return torch.FloatTensor(sinusoid_table).unsqueeze(0) # dim = [1, n_position, d_hid]
def forward(self, x):
'''
词嵌入+位置编码:x + pos
self.pos_table由构造函数定义
.detach()返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,
不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
:x.size(1)目的是防止d为奇数,导致最后pos_table为2 * d//2 == d + 1
'''
return x + self.pos_table[:, :x.size(1)].clone().detach()
Transformer中的Mask3
为了屏蔽某些句子影响,作者引入mask,使其不产生效果。Transformer模型里面涉及两种mask。分别是padding mask和sequence mask。
Mask在Transformer中主要作用:
- padding部分不参与attention操作,句子长短不一,部分短句需要加入padding操作,但是补0部分参与attention操作会干扰最后的注意力,所以引入mask,用于Scaled Dot-Product Attention中的mask操作;
- 生成当前词语的概率分布时,屏蔽未来时刻单词的信息,用于Masked Multi-Head Attention中的mask操作。
Mask
Sample:
如句子seq包含两个词,分别embedding为
[
1
,
1
,
1
,
1
]
[1,1,1,1]
[1,1,1,1]和
[
1
,
1
,
1
,
1
]
[1,1,1,1]
[1,1,1,1]。然而要求句子长度为4,所以,需要padding补0。如下式所示:
[
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
]
\begin{gathered} \begin{bmatrix} 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0\end{bmatrix} \end{gathered}
⎣⎢⎢⎡1100110011001100⎦⎥⎥⎤
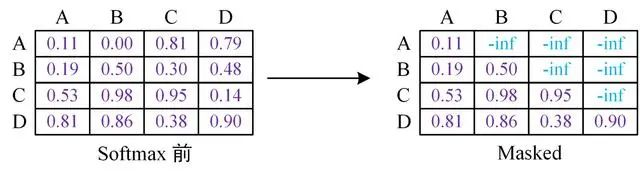
注意到句子后面补充的两个单词全部为0,但是attention不应该因为padding 0而受到大的影响,所以加入mark机制,将补0位置替换为负的极大值,这样的话,所有与这两个单词attention的结果都会是0。
Pad Mask
因为每个批次输入序列长度是不一样,需要对输入序列进行对齐。给较短的序列后面填充 0,对于输入太长的序列,截取左边的内容,把多余的直接舍弃。这些填充的位置,没什么意义,所以attention机制不应该把注意力放在这些位置上,需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。

def get_pad_mask(seq, pad_idx):
'''
Pad mask
seq: [batch_size, seq_len]
pad_idx: [batch_size, seq_len]
'''
return (seq != pad_idx).unsqueeze(-2) # bool类型 [batch_size, 1, seq_len] 个人理解,目的是为了和subseq Mask(batch_size,seq_len,seq_len)对齐
Subsequence Mask
Encoder中 self-attention 的 padding mask 如上,而 Decoder 还需要防止标签泄露,即在 t 时刻不能看到 t 时刻之后的信息,因此在上述 padding mask 的基础上,还要加上 sequence mask。
sequence mask 一般是通过生成一个上三角矩阵来实现的,上三角区域对应要 mask 的部分。
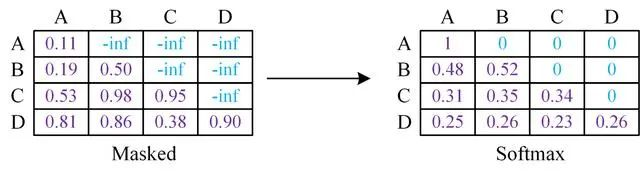
在 Transformer 的 Decoder 中,先不考虑 padding mask,一个包括四个词的句子 [A,B,C,D] 在计算了相似度 scores 之后,得到下面第一幅图,将 scores 的上三角区域 mask 掉,即替换为负无穷,再做 softmax 得到第三幅图。这样,比如输入 B 在 self-attention 之后,也只和 A,B 有关,而与后序信息无关。
def get_subsequent_mask(seq):
''' For masking out the subsequent info. '''
sz_b, len_s = seq.size()
# torch.triu(input, diagonal=0, out=None) 返回矩阵上三角部分,其余部分定义为0
# 如果diagonal为空,输入矩阵保留主对角线与主对角线以上的元素;
# 如果diagonal为正数n,输入矩阵保留主对角线与主对角线以上除去n行的元素;
# 如果diagonal为负数-n,输入矩阵保留主对角线与主对角线以上与主对角线下方h行对角线的元素;
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool() # Upper triangular matrix
return subsequent_mask
ScaledDotProductAttention

A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
V
)
Attention(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}}V)
Attention(Q,K,V)=softmax(dkQKTV)
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature # 热度?怀疑是\sqrt{d_k}
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))# \frac{QK^T}{\sqrt{d_k}}
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9) # 如Mask介绍,补0位全部置为10^{-9}
attn = self.dropout(F.softmax(attn, dim=-1))# 因为涉及到多头问题,所以第一列为头,所以softmax应该为dim=-1
output = torch.matmul(attn, v)
return output, attn
Multi Head 多头怪
Transformer将每个Attention处理器称为Attention Head,并行重复计算。这就是所谓的多头注意。通过组合几种类似的注意力计算,它赋予了注意力更大的辨别力。文中提到并行操作更加贴近于GPU运算方式,但是并不是指计算复杂度降低,相反,计算量比单头更大。

class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head # n_head=8
self.d_k = d_k # dimension of key
self.d_v = d_v # dimension of value
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False) # multi-head self-attention权重计算
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5) # 单头att
self.dropout = nn.Dropout(dropout) #很有灵性的调参手段!!!
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) #当时很火的layer normalization
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: batch x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
# n表示n_head
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1) #注意view处理整块内存,需要用.contiguous()函数将tensor变成在内存中连续分布的形式。
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
PositionwiseFeedForward
这部分就是一个两层线性映射并用激活函数激活
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
Encoder
class EncoderLayer(nn.Module):
''' Compose with two layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None):
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
class Encoder(nn.Module):
''' A encoder model with self attention mechanism. '''
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx) # 词嵌入 x
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) # 位置编码pos
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)]) #多头编码
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
# -- Forward
enc_output = self.src_word_emb(src_seq)
if self.scale_emb:
enc_output *= self.d_model ** 0.5
enc_output = self.dropout(self.position_enc(enc_output))# x + dropout(pos)
enc_output = self.layer_norm(enc_output)
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
Decoder
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask) # multi-head自注意力 q,k,v都是自己
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask) # encoder和decoder的注意力,如上图所示,K,V都是encoder 多层计算得到,Q是decoder得到的。
dec_output = self.pos_ffn(dec_output)# Feed-Forward
return dec_output, dec_slf_attn, dec_enc_attn
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward
dec_output = self.trg_word_emb(trg_seq)
if self.scale_emb:
dec_output *= self.d_model ** 0.5 # \sqrt{d_k}
dec_output = self.dropout(self.position_enc(dec_output))
dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output,
Transformer

class Transformer(nn.Module): ''' A sequence to sequence model with attention mechanism. ''' def __init__( self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx, d_word_vec=512, d_model=512, d_inner=2048, n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200, trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True, scale_emb_or_prj='prj'): super().__init__() self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx # In section 3.4 of paper "Attention Is All You Need", there is such detail: # "In our model, we share the same weight matrix between the two # embedding layers and the pre-softmax linear transformation... # In the embedding layers, we multiply those weights by \sqrt{d_model}". # # Options here: # 'emb': multiply \sqrt{d_model} to embedding output # 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output # 'none': no multiplication # 选择哪种scale,也就是除以$\sqrt{d_k}$ assert scale_emb_or_prj in ['emb', 'prj', 'none'] scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else False self.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else False self.d_model = d_model self.encoder = Encoder( n_src_vocab=n_src_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb) self.decoder = Decoder( n_trg_vocab=n_trg_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb) self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)#decoder输出后送入fc中 for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) assert d_model == d_word_vec, \ 'To facilitate the residual connections, \ the dimensions of all module outputs shall be the same.' if trg_emb_prj_weight_sharing: # Share the weight between target word embedding & last dense layer self.trg_word_prj.weight = self.decoder.trg_word_emb.weight if emb_src_trg_weight_sharing: self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight def forward(self, src_seq, trg_seq): src_mask = get_pad_mask(src_seq, self.src_pad_idx) trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq) enc_output, *_ = self.encoder(src_seq, src_mask) dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask) seq_logit = self.trg_word_prj(dec_output) if self.scale_prj: seq_logit *= self.d_model ** -0.5 return seq_logit.view(-1, seq_logit.size(2))

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









