







AANet
《AANet: Adaptive Aggregation Network for Efficient Stereo Matching》CVPR2020,针对双目匹配任务的论文。
论文:https://arxiv.org/abs/2004.09548v1
代码:https://github.com/haofeixu/aanet
一、目的和贡献:
目前最好的立体匹配模型基本都用3D卷积,计算复杂度高且占用大量存储空间,本论文的目的就是完全替代3D卷积;
提出:
尺度内代价聚合模块:基于稀疏点,缓解边缘视差不连续问题;
尺度间代价聚合:跨通道,解决大的无纹理区域问题;
二、相关工作
Local Cost Aggregation:
基于窗口的方法,假设窗口内都有相同视差,这样做不能处理好视差不连续的地方,目标边界或者精细结构边界变粗
Cross-Scale Cost Aggregation:
Stereo Matching Networks:
Deformable Convolution:
三、 方法:
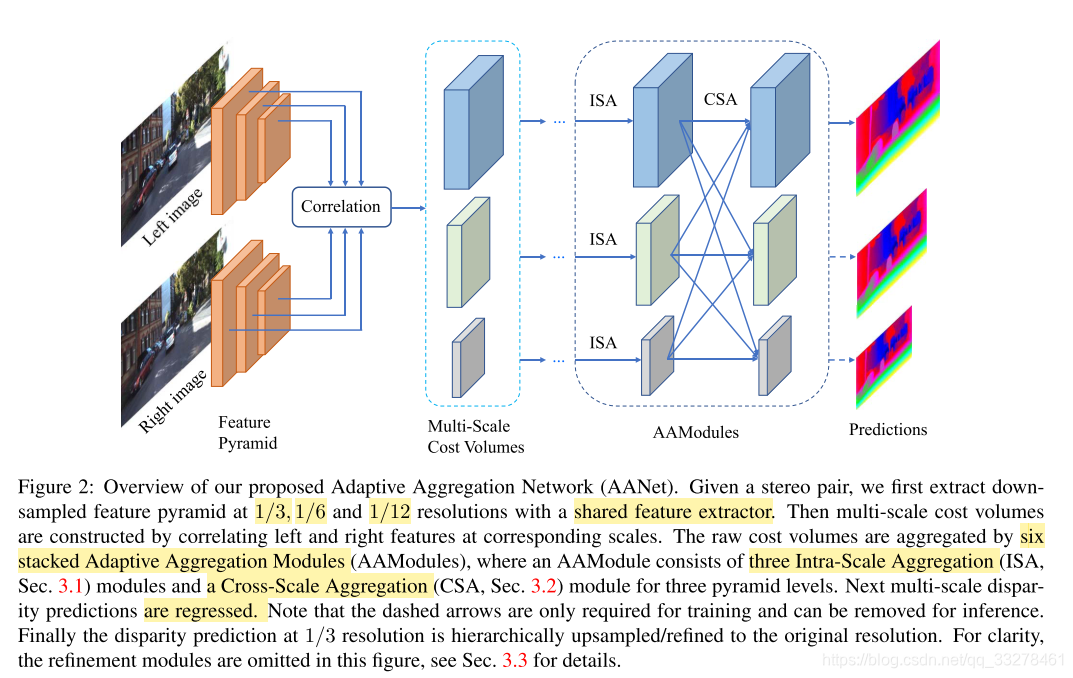
输入:rectify后的左图和右图;
共享权值抽取特征;
多尺度的3D cost volumes:3个尺度(实现方式和dispnet一样);
AA模块:堆叠6个;
refine模块:多个预测值上采样到原始分辨率。
3.1 Adaptive Intra-Scale Aggregation
-
目的
为了解决视差不连续处的边缘变粗的问题,提出基于稀疏点的高效、灵活的代价聚合方式,形式和可形变卷积类似; -
计算代价公式
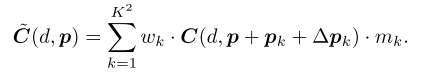
C ∈ R D ∗ H ∗ W C \in R^{D * H * W} C∈RD∗H∗W, D代表最大视差,H和W代表高和宽;
C ^ ( d , p ) \hat C(d,p) C^(d,p)是像素 p 位置在候选视差 d 处的代价值;
K 2 K^2 K2 是采样的点数(本文K=3), w k w_k wk$ 是k个点的权重, p k p_k pk是p的固定偏移(和window based代价聚合方法一致);
Δ p k Δp_k Δpk 是可学习的额外偏移,有了这一项对***目标边界和薄结构效果更好***。
m k m_k mk 是每个位置的权重,用来控制采样点的相对影响从而实现内容自适应的代价聚合,参照可形变卷积v2。
Δ p k 和 m k Δp_k和m_k Δpk和mk 由单独的卷积层计算,输入为cost volume C;
原始可形变卷积偏移 Δ p k Δp_k Δpk 和权重 m k m_k mk 所有通管道共享,这里把通道划分成组,组内共享。用了空洞卷积,设置组数G=2,dilation rate=2。 -
ISA结构:
Intra-Scale Aggregation(ISA)由三层卷积和残差连接堆叠而成,三个卷积1x1、3x3(deformable conv)、1x1,类似bottlenect结构,这里保持channel等于候选视差数不变。 -
其他:
这里把固定窗口代价聚合改进成了任意形状,输入是cost volume,参考了可形变卷积v2,仿照v2实现了不同偏移位置全中国不同(这里不同的是mk而不是wk,wk是窗口聚合权重,mk是对聚合权重的修正);
分组聚合有点group normalization或者gwc-net里group correlation的样子,算是一个对逐通道和全部通道的折中;
用了dilation conv;
3.2 Adaptive Cross-Scale Aggregation
- 目的
无纹理和低纹理区域,在粗糙的尺度先搜索视差效果会好一点,下采样的图有更具判别型的信息。所以用一个加入一个跨尺度的代价聚合模块CSA。 - 每个尺度经过cost volume如下:
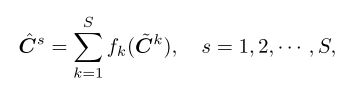
C ^ s \hat C^s C^s就是尺度s经过跨尺度代价聚合后的cost volime结果,s表示第几个尺度(s=1是最大分辨率),S是尺度总个数;
f k f_k fk 采用HRNET的方法,可以让多个尺度自适应的合并cost volume。 - 不同尺度的
f
k
f_k
fk 怎么计算?
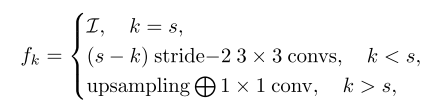
第一项 I I I 是恒等式,聚合尺度s的时候,当前尺度的cost volume直接用;
第二项是s-k个步长为2的3x3卷积,就是大尺度经过下采样为了和下尺度分辨率一致,当前cost volume尺度小于s时候;
第三项是bilinear upsampling后接1x1,当前cost volume尺度大于s时候;
这里其实就是不同尺度聚合的时候分辨率不同,用这种方法对齐分辨率,大的变小,小的变大,自身尺度恒等不变。
- 和HRNet的不同?
1)本文受传统跨尺度成本聚合算法的启发,目的是通过神经网络层来近似几何结论,HRNet旨在学习特征表示;
2)低尺度cost volume通道数(对应视差维度)减少一半,因为粗尺度的视差搜索范围小了;而HRNet增加了一倍,可以说明本文的更高效。
3.3 Adaptive Aggregation Network
堆叠6个AA Module做代价聚合,前三个的ISA只用普通2D卷积,后三个在用deformable conv(网络里一共用了9个做代价聚合);
特征提取器类似resnet,40层,其中6个conv被改为deformable conv;
FPN构建1/3,1/6,1/12分辨率特征;
用两个StereoDRNet里的refine模块分层上采样1/3的视察预测结果到原始分辨率(先到1/2再到原始);
3.4 Disparity Regression
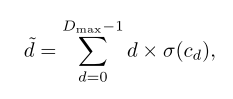
soft argmin方法, D m a x D_{max} Dmax 是最大视差范围, σ \sigma σ 是softmax,这种基于回归的方式可以实现亚像素精度,现在基本都是用这种方法。
soft argmin就是不直接选代价最小视差,cost volume用softmax转化为概率,对视差做个加权求和。
3.5 Loss Function
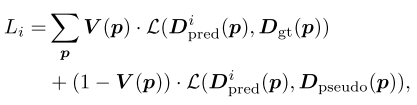
V
(
p
)
V(p)
V(p) 是mask,因为有些位置缺失标签所以用GANET预测pseudo的label。
四、实验
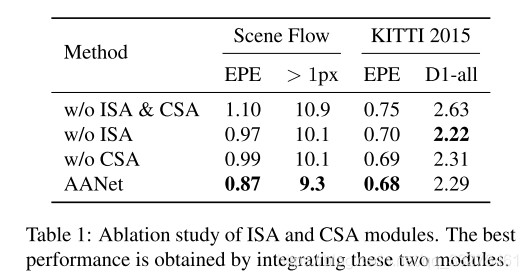
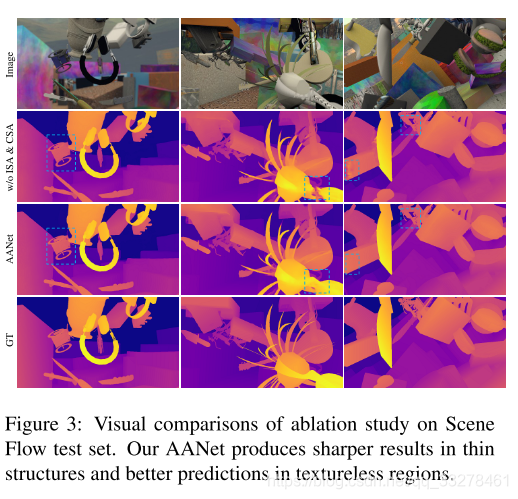

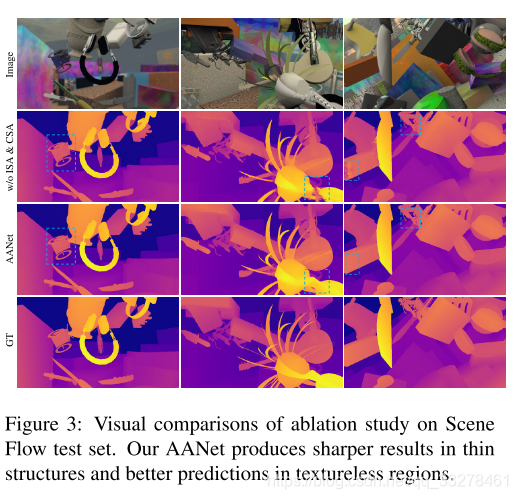
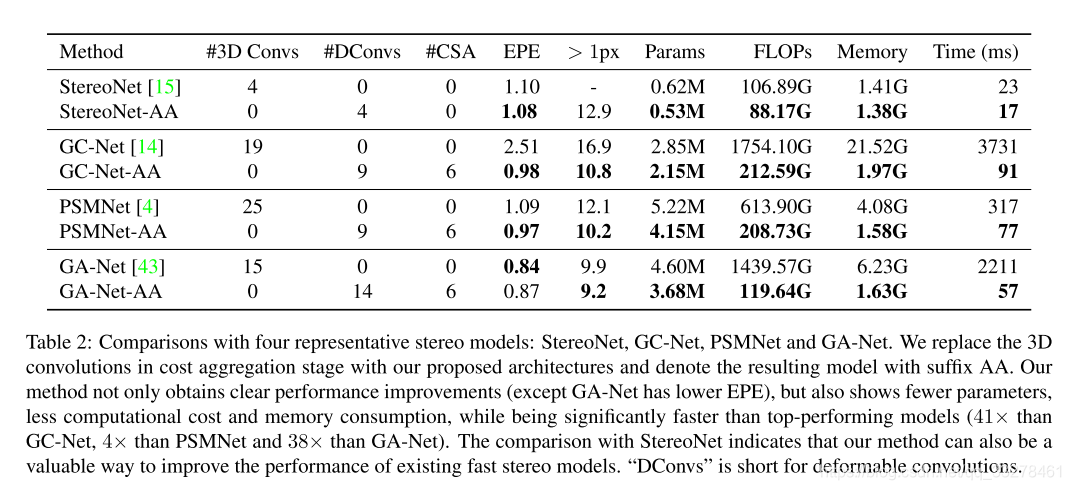

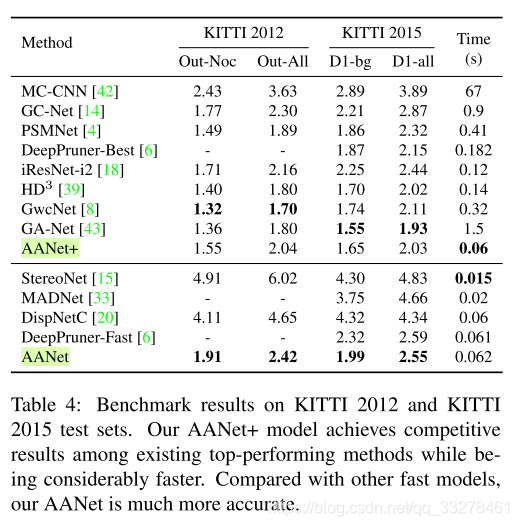

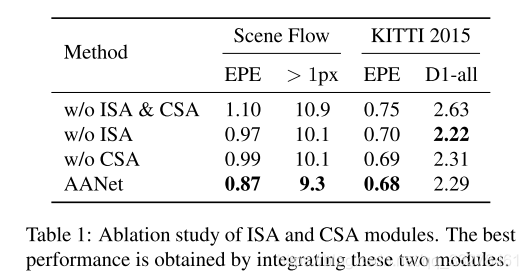

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









