







 本文介绍了集中趋势分析的概念,并详细讲解了众数(M0)和中位数(Me)。众数是一组数据中出现次数最多的值,不受极端值影响,适用于分类数据。中位数是排序后位于中间位置的值,同样不受极端值影响,主要用于顺序数据。文中通过实例解析了如何确定众数和中位数。
本文介绍了集中趋势分析的概念,并详细讲解了众数(M0)和中位数(Me)。众数是一组数据中出现次数最多的值,不受极端值影响,适用于分类数据。中位数是排序后位于中间位置的值,同样不受极端值影响,主要用于顺序数据。文中通过实例解析了如何确定众数和中位数。
目录
一、集中趋势分析
概念:
1.一组数据向其中心值靠拢的倾向和程度。
2.测度集中趋势就是寻找数据水平的代表值或中心值。
3.不同类型的数据用不同的集中趋势测度值。
4.低层次数据的测度值适用于高层次的测量数据,但高层次的数据的测度值并不适用于低层次的测量数据。
二、众数(M0)
1.一组数据中出现次数最多的变量值
2.适用于数据量较多时使用
3.不受极端值的影响
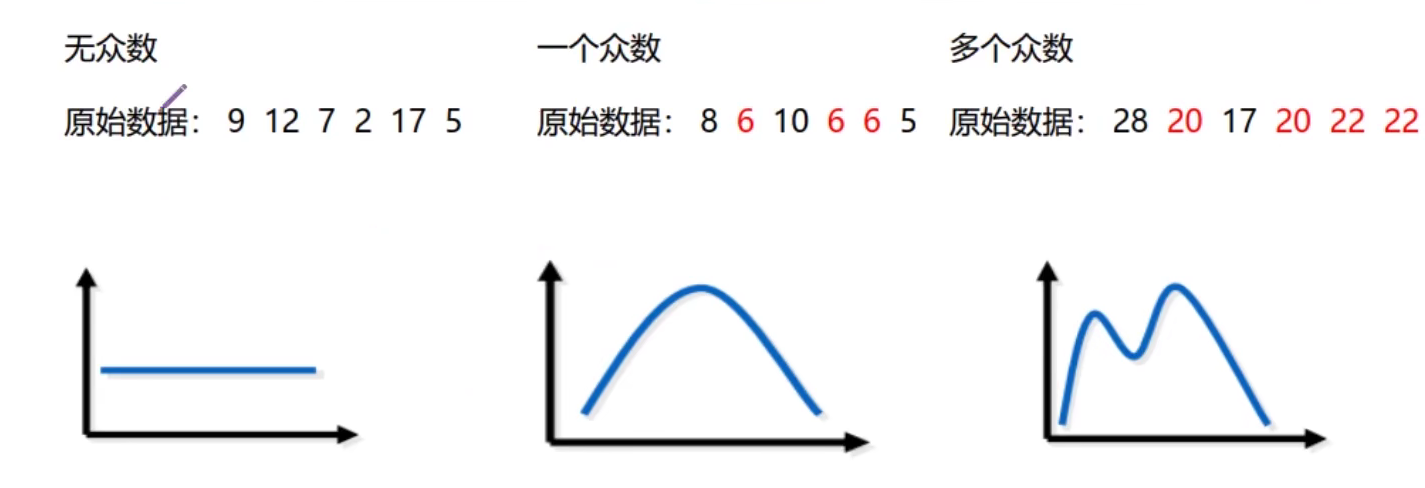
4.一组数据中可能没有众数或有几个众数
5.主要用于分类数据,也可用于顺序数据或数值型数据
在集中趋势分析中众数的三个表现形式
例1:
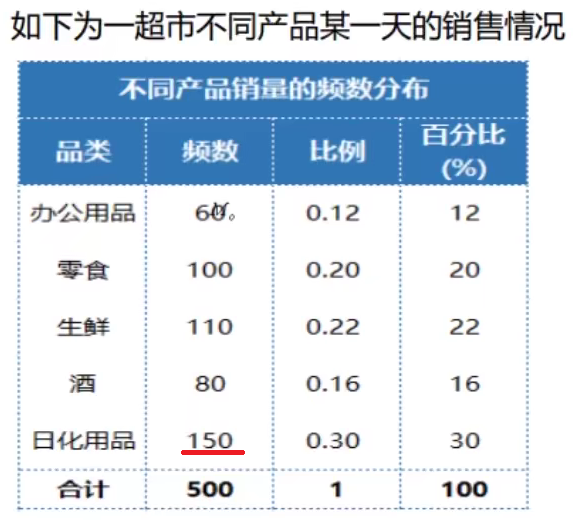
在这道题中,品类为分类变量,频数就是变量值,日化用品频数为150,占的比例最大,所以众数为日化用品这个品类,即M0=日化用品
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2041
2041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









