






在FATE中可以通过json格式的文件来上传数据并配置模型,使用json格式会减少很多操作,更加方便快捷的使用FATE联邦学习进行训练。官方文档解释地址参考tutorial - FATE
下面记录我根据文档并参考一些博客使用json格式来完成横向逻辑回归。
所使用的数据集为MNIST手写数字识别数据集,可以从MNIST in CSV | Kaggle中下载CSV格式的数据集,在下载过程中需要注册账号并登陆,在注册过程中可能会遇到一些问题,比如加载不出来验证码,如果遇到此问题可以通过以下方式解决
点击浏览器中的扩展图标
选择打开加载项
进入此页面,然后搜索
获取成功后进入此拓展程序。
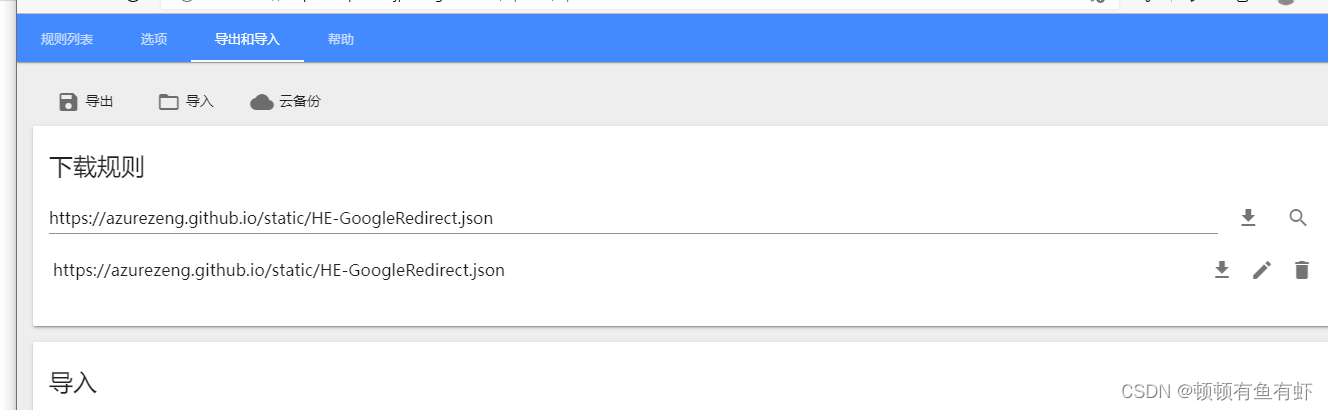
在导入中输入https://azurezeng.github.io/static/HE-GoogleRedirect.json
加载完成后点击保存,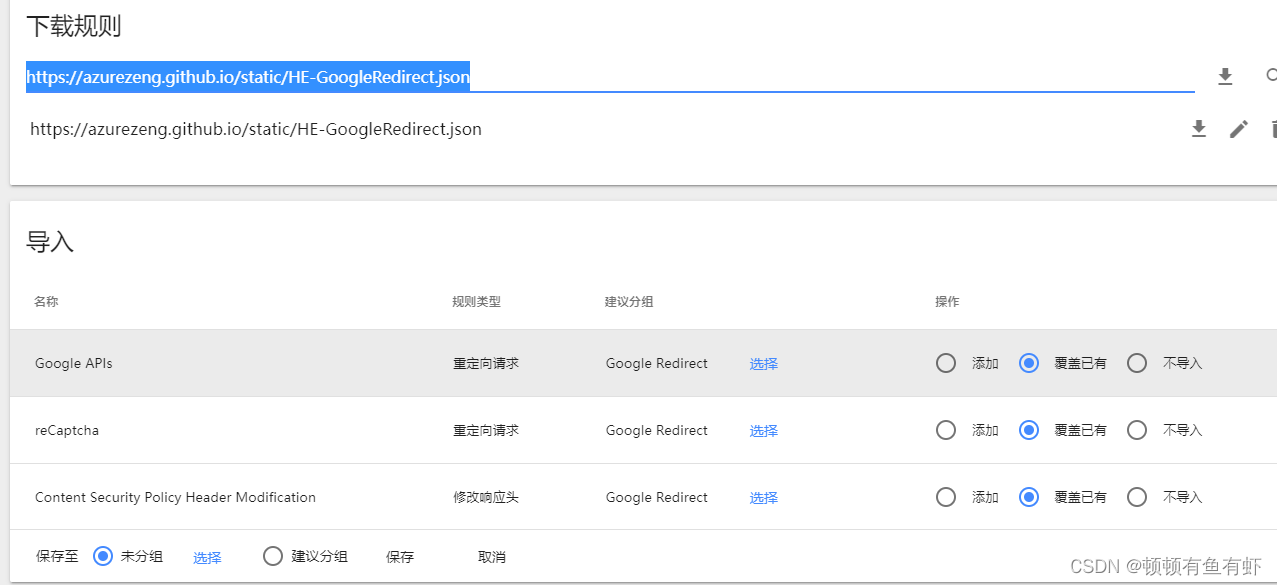
然后重新进去就可以下载了。
下面进入正题,完成FATE横向联邦学习的训练过程。
在成功获取MNIST数据之后我们需要对数据集进行处理
import pandas as pd
train=pd.read_csv("data/mnist_train.csv")
test=pd.read_csv("data/mnist_test.csv")
#筛选出标签为0和1的样本作为横向逻辑回归的训练样本
train_0_1=train[train['label']<2]
#添加id属性
train_0_1['idx']=range(train_0_1.shape[0])
idx=train_0_1['idx']
train_0_1.drop(labels=['idx'],axis=1,inplace=True)
train_0_1.insert(0,'idx',idx)
#将label标签修改为y
y=train_0_1['label']
train_0_1.drop(labels=['label'],axis=1,inplace=True)
train_0_1.insert(train_0_1.shape[1],'y',y)
#分割数据集
train_host=train_0_1.iloc[:6000]
train_guest=train_0_1.iloc[6000:]
#保存分割的数据集为csv格式
train_host.to_csv("data/mnist_host_train.csv",index=False,header=True)
train_guest.to_csv("data/mnist_guest_train.csv",index=False,header=True)
#对测试数据集进行处理
#筛选出标签为0和1的样本作为横向逻辑回归的测试样本
test_0_1=test[test['label']<2]
#添加id属性
test_0_1['idx']=range(test_0_1.shape[0])
idx=test_0_1['idx']
test_0_1.drop(labels=['idx'],axis=1,inplace=True)
test_0_1.insert(0,'idx',idx)
#将label标签修改为y
y=test_0_1['label']
test_0_1.drop(labels=['label'],axis=1,inplace=True)
test_0_1.insert(test_0_1.shape[1],'y',y)
#保存数据集为csv格式
test_0_1.to_csv("data/mnist_test_lg.csv",index=False,header=True)运行完此程序之后会得到三个新的scv格式的数据集
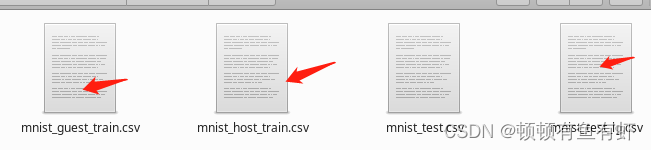
在数据处理完之后,我们需要进行对数据进行上传。我们采用json格式进行上传。在FATE项目中有写好的上传json文件,在examples/dsl/v2/upload文件夹中,upload_conf.json此文件。在我的实验中,我将此文件复制到了我在FATE目录下新建的工作目录下,并对其进行了修改。
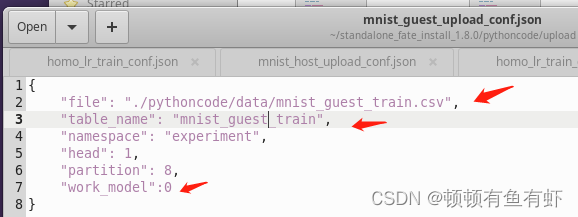
{
"file": "./pythoncode/data/mnist_guest_train.csv",
"table_name": "mnist_guest_train",
"namespace": "experiment",
"head": 1,
"partition": 8,
"work_model":0
}这里需要注意箭头标注的地方要换成自己的目录和表名,"work_model":0 表示为单机部署模式。
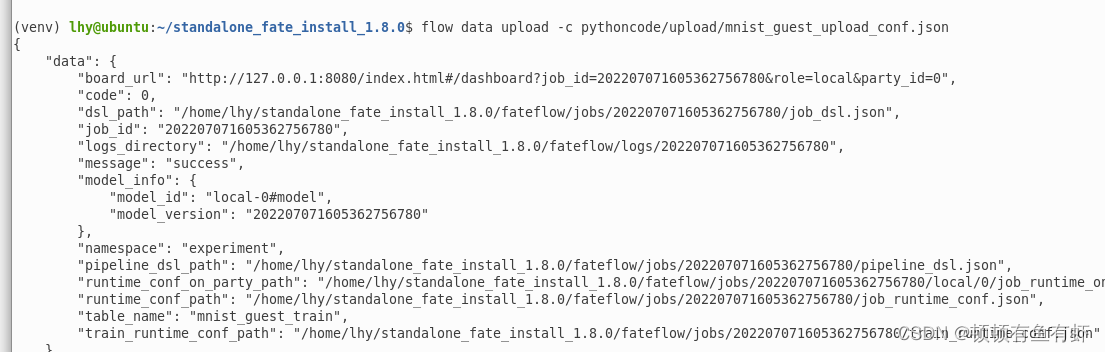
修改完成之后使用flow命令进行上传。
flow data upload -c pythoncode/upload/mnist_guest_upload_conf.json 成功后显示如图
同样的还需要上传host的数据集,
{
"file": "./pythoncode/data/mnist_host_train.csv",
"table_name": "mnist_host_train",
"namespace": "experiment",
"head": 1,
"partition": 8,
"work_model":0
}修改json文件完成后执行
flow data upload -c pythoncode/upload/mnist_host_upload_conf.json 在数据完成上传之后,下面需要对训练任务进行配置,在FATE项目中已经给出了很多写好的配置,我们可以在此基础上进行修改就能直接用了。
在这里我使用的是homo_lr_train_conf.json和homo_lr_train_dsl.json,这两个文件在examples/dsl/v2/homo_logistic_regression目录中能够找到。接下来我们需要对其进行修改
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"guest": [
9999
],
"host": [
10000
],
"arbiter": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"tol": 1e-05,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 30,
"early_stop": "diff",
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
},
"decay": 1,
"decay_sqrt": true
},
"evaluation_0": {
"eval_type": "binary"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "mnist_host_train", #注意此处换成对应的表名,在复制此代码时需要删除此注释
"namespace": "experiment"
}
},
"evaluation_0": {
"need_run": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "mnist_guest_train",#注意此处换成对应的表名,在复制此代码时需要删除此注释
"namespace": "experiment"
}
}
}
}
}
}
}接下来修改dsl.json文件,此处我并没有进行修改,当然也可以根据自己的需求添加或减少相应的模块,具体的格式参考官方文档job conf guide - FATE
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"scale_0": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_lr_0": {
"module": "HomoLR",
"input": {
"data": {
"train_data": [
"scale_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"homo_lr_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}在修改完成之后就可以提交任务了。
flow job submit -c pythoncode/dsl/homo_lr_train_conf.json -d pythoncode/dsl/homo_lr_train_dsl.json
提交成功后我们能够看到以下信息
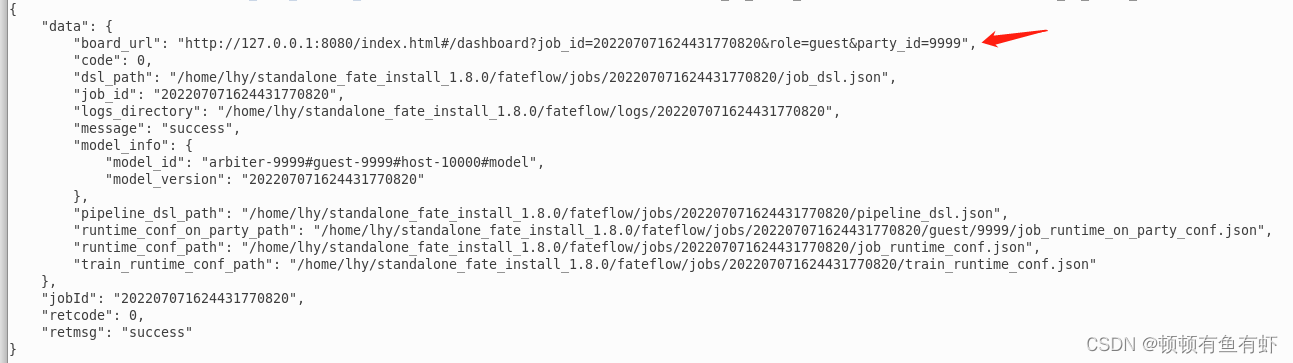
通过箭头所指地址我们可以在浏览器中查看任务进度和信息
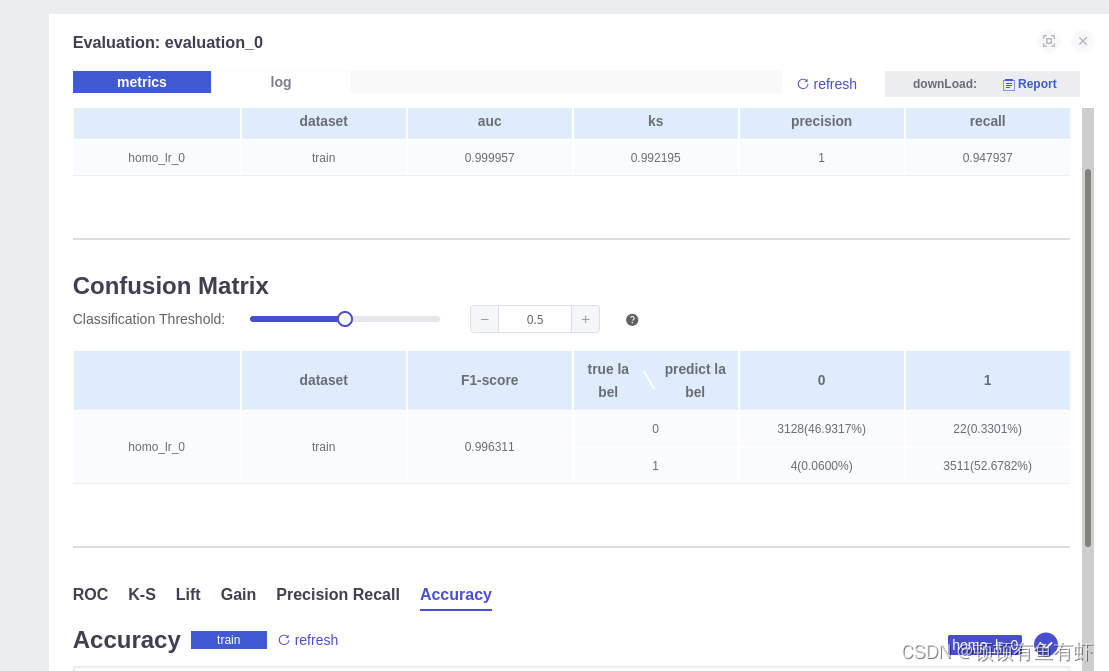 欢迎指正!
欢迎指正!

















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









