






作 者:echoy189
介 绍:spark数据处理与算法交流
公众号:spark推荐系统
PCA(Principal Component Analysis)即主成分分析方法,是一种使用最广泛的数据线性降维的算法主要思想是将n维特征映射到k维上(k<n),且尽量减少信息的损失。应用领域包括:维度降低,有损数据压缩,特征抽取,数据可视化等
目录
预备知识
降维的目的
PCA实现原理
PCA的最大方差形式
PCA算法总结
代码展示
一) 预备知识
1.矩阵乘法
2矩阵转置
3.矩阵的特征向量与特征值(定义及求解)
https://wenku.baidu.com/view/f14c18215901020207409c97?ivk_sa=1023194j
二) 降维的目的
1.使得数据集更易使用
2.降低算法的计算开销
3.去噪,降噪
4.使w参数变少,使用模型也会更快
5.数据可视化
6.数据压缩
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)。
三) PCA实现原理
首先考虑将数据X(n行D列)投影到一维空间中
我们可以使用D维向量u1来定义该D维空间上的一个方向,由于我们只关心u1的方向,并不关心u1的长度,所以假设 u1•u1转置=1
将x1:n条数据投影到该u1方向得到n个值,便是将m条D维的数据降维到1维的过程
向量的投影公式为:u1转置 • Xn
这样,每个数据点Xn被投影到一个标量u1转置 • Xn上,投影后数据的均值为u1转置•x拔
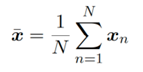
那么何种投影方式最好呢?
如下图展示,是一个二维的数据集合,将数据(n行2维)进行降维到(n行1维),选择一个u1特征向量(2维)进行投影,u1有无数组情况,那么u1如何选择?
==》
方法1:选择投影之后的数据,方差最大 那个的u1
方法2:选择投影之后的数据,离u1距离最近的u1
(两种方法结论一致,本文用方差最大进行求解)
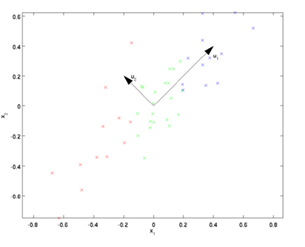
四) PCA的最大方差形式
方差最大的u1怎么找?

所以求S(数据集Xn协方差)中特征值最大所对应的特征向量,就是投影后方差最大的u1
注:特征值与特征向量求法参考预备知识
五) PCA算法总结
目标:在信息损失最小的基础上,将n个d维数据降维至k维
1.拿到n个d维数据
2.计算其协方差矩阵S(通常会先对数据进行标准化),此时 S = X转置•X (特征工程部分)
3.寻找方阵S的最大的k个特征值,找到对应这k个特征值的k个特征向量 u1:k (算法部分)
4.对n个数据中每一个分别计算其在u1:k 方向上的投影,得到k个实数值,作为新的k个维度的取值
5.4的操作等价于 将X 矩阵 乘以 u1:k向量组成的矩阵
6.新来的数据也可以按照4或5操作,直接进行映射
六) 代码展示
# python 实现pca
import numpy as np
'''
X: 样本
k: 降维后的维度数
'''
def pca(X, k):
# 获取样本条数,特征数
n_samples, n_features = X.shape
# 对每列求均值
mean = np.array([np.mean(X[:, i]) for i in range(n_features)])
# 协方差矩阵
norm_X = X - mean
scatter_matrix = np.dot(np.transpose(norm_X), norm_X)
# 求协方差矩阵中特征值域特征向量
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
# 取特征值top k个特征向量
eig_paris = [(np.abs(eig_val[i]), eig_vec[:, i]) for i in range(n_features)]
eig_paris.sort(reverse=True)
feature = np.array([ele[1] for ele in eig_paris[:k]])
# 根据top k特征向量进行降维
data = np.dot(norm_X, np.transpose(feature))
return data
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
# 将2维映射到1维
print(pca(X, 1))
降维结果
[[-0.50917706][-2.40151069][-3.7751606][1.20075534][2.05572155][3.42937146]]往期精选
机器学习-线性回归(一)

长按识别二维码关注我

















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









