






论文链接:https://arxiv.org/pdf/2502.18600
1. 概述
论文标题:Chain of Draft: Thinking Faster by Writing Less
作者:Silei Xu, Wenhao Xie, Lingxiao Zhao, Pengcheng He(Zoom Communications)
核心思想:
- 目前,Chain-of-Thought (CoT) prompting 使得大型语言模型在解决复杂推理任务时能逐步展现推理过程,但这种方法往往产生冗长的中间步骤,导致高成本和高延迟。
- 人类在解决问题时通常只记录下最关键的中间草稿,而非冗长的详细推理。论文提出的 Chain of Draft (CoD) 正是受此启发,要求模型在每一步只生成简洁且富有信息的“草稿”,从而大幅减少生成的 token 数量,同时保持甚至提升推理准确率。
2. 引言与动机
-
背景说明:
大型语言模型(LLMs)如 OpenAI o1 和 DeepSeek R1 已经通过 CoT prompting 在多步推理任务上取得显著成绩。然而,CoT 的缺点在于:- 冗长性:详细的逐步推理过程导致生成大量 token。
- 延迟高:生成冗长回答会增加推理时间和计算资源消耗。
-
人类思考启示:
与之不同的是,人类在解决问题时通常只记录下必要的关键信息。例如,在解决数学问题时,我们更倾向于写下“20 - x = 12; x = 20 - 12 = 8”这样的简洁草稿,而非详细描述每个步骤的背景信息。 -
论文目标:
提出一种新的提示策略——Chain of Draft (CoD),其核心在于:- 高效性:通过生成精炼的中间草稿,显著降低 token 数量(论文实验中最低仅为 CoT 的 7.6%)。
- 低延迟:减少冗余信息,降低推理所需时间和成本。
- 准确性:在多数任务上,CoD 的推理准确率可与传统 CoT 相媲美,甚至在部分任务上略有超越。
3. 方法:Chain of Draft (CoD) Prompting
3.1 思路与设计
-
基本理念:
CoD 借鉴了人类在解决问题时的草稿记录方式,要求模型在推理过程中只记录最核心的计算和判断信息,而不是逐字逐句展开解释。 -
与 CoT 的对比:
- 标准提示(Standard):直接给出最终答案,不展示推理过程。
- Chain-of-Thought (CoT):生成详细的逐步推理过程,虽然准确但冗长且耗时。
- Chain of Draft (CoD):在生成推理时,每一步只要求输出极简的草稿(例如限制每步不超过 5 个词),仅保留最关键信息。
3.2 算术问题示例
以一个简单的算术问题为例:
问题:Jason 有 20 支棒棒糖,送出一些后剩 12 支,请问他送了多少支?
-
标准提示:
模型可能直接回答答案:8
-
CoT 提示:

模型生成详细推理,例如:
“首先,Jason 一开始有 20 支棒棒糖;之后他送出一些,剩下 12 支;因此,送出的数量等于 20 减去 12,即 8。”
-
CoD 提示:

模型输出极简草稿:
20 − x = 12 ; x = 20 − 12 = 8 20 - x = 12; \quad x = 20 - 12 = 8 20−x=12;x=20−12=8
由此可见,CoD 在表达关键信息的同时大大减少了不必要的冗长描述。
4. 实验设计与结果
论文在多个任务上对 CoD 进行了验证,主要包括以下三个类别:
4.1 算术推理
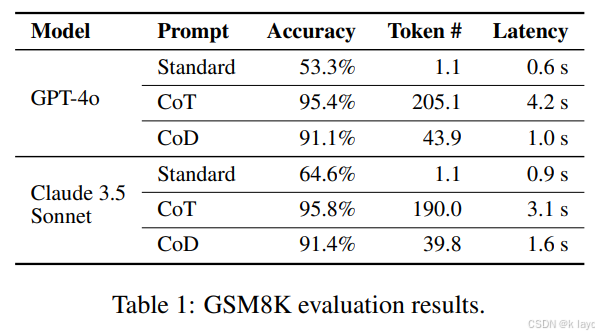
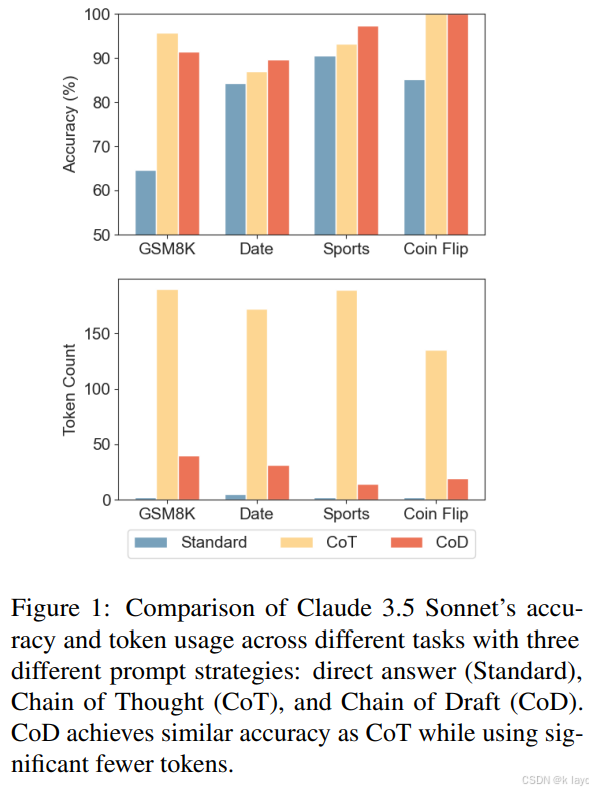
- 数据集:使用 GSM8K(Cobbe et al., 2021)。
- 实验比较:采用 GPT-4o 和 Claude 3.5 Sonnet 两个模型,对比标准提示、CoT 和 CoD 三种策略。
- 结果:
- 对于 GPT-4o:
- 标准提示准确率约 53.3%,输出 token 数极少,但缺乏推理过程;
- CoT 提高至约 95.4%准确率,但平均输出约 205 个 token,延迟较高;
- CoD 达到约 91.1%准确率,但仅使用约 43.9 个 token,延迟显著降低。
- 类似结果在 Claude 3.5 Sonnet 上也得到了验证。
- 对于 GPT-4o:
4.2 常识推理
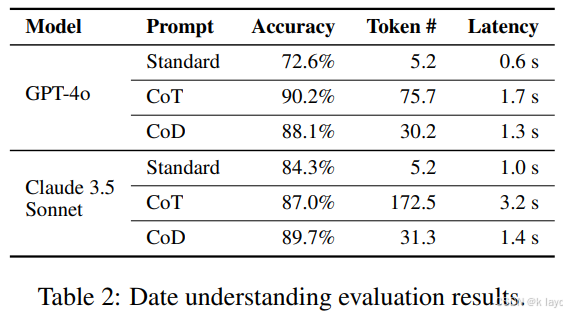
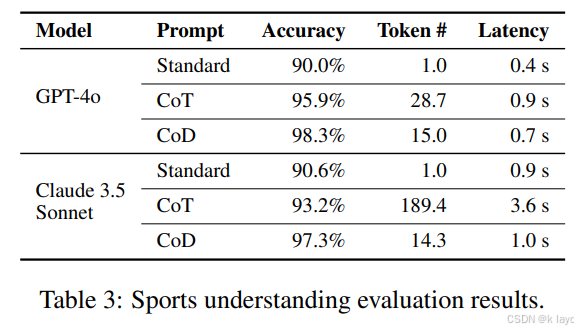
- 任务示例:日期理解和体育理解任务(来自 BIG-bench)。
- 对比结果:
- CoT 生成冗长输出(例如 Claude 3.5 Sonnet 在体育理解任务中输出接近 189 个 token),而 CoD 显著减少 token 数(降至大约 14-31 个 token),同时在准确率上保持甚至略高于 CoT。
4.3 符号推理
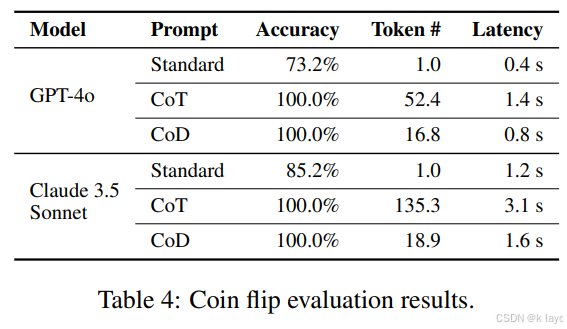
- 任务描述:类似硬币翻转任务,要求模型基于多步推理判断最终状态。
- 结果:
- 使用 CoT 和 CoD 后,模型均能达到 100% 准确率,但 CoD 显著降低了输出 token 数(例如 GPT-4o 从 52.4 个 token 降至 16.8 个 token)。
5. 局限性与讨论
5.1 零样本设置下的效果
- 当没有少样本示例(zero-shot)时,CoD 的效果会有所下降。这表明在缺乏 CoD 风格提示的情况下,模型难以自动生成足够简洁的中间草稿。
5.2 小模型表现
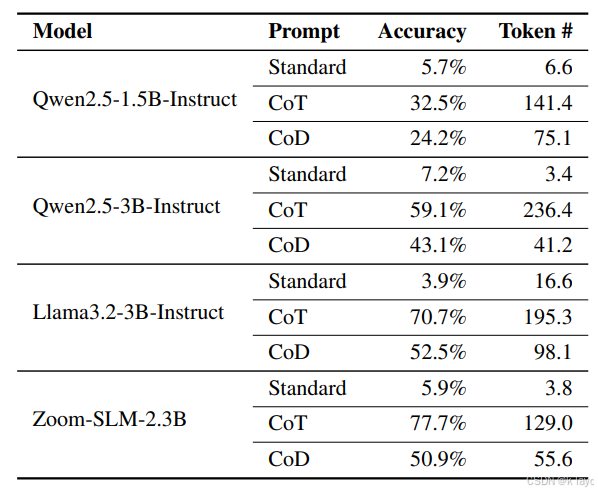
- 对于参数量小于 3B 的模型(如 Qwen2.5-1.5B/3B、Llama3.2-3B 以及 Zoom SLM 2.3B),虽然 CoD 仍能减少 token 数并提升一定准确率,但与 CoT 的性能差距更大。这可能是由于小模型在预训练时缺乏生成简洁草稿的数据支持。
5.3 推理延迟与成本
- CoD 显著降低了推理延迟和计算成本,对于实际应用场景尤其具有吸引力。论文讨论了如何在保证准确性的同时,通过减少 token 数来提高效率。
6. 结论
-
主要贡献:
- 提出了一种全新的 Chain of Draft (CoD) 提示策略,受人类思维过程启发,实现了在多步推理任务中生成极简中间草稿。
- 实验证明,CoD 能在保持较高准确率的同时,大幅减少生成 token 数(例如在 GSM8K 中仅使用 CoT 的约 20%-30%),从而降低延迟和计算成本。
- 在算术、常识和符号推理任务中,CoD 均展示了优异的性能,同时为解决推理冗长问题提供了新的思路。
-
未来方向:
- 探索在零样本场景和小模型上的进一步优化方法,例如通过专门的 CoD 风格微调数据来提升模型生成简洁草稿的能力。
- 结合其他延迟降低技术,如自适应并行推理或多遍验证,进一步压缩响应时间与计算成本。
7. 总结
论文 Chain of Draft: Thinking Faster by Writing Less 提出了一种创新的提示策略 CoD,该方法借鉴人类在复杂问题求解时只记录关键信息的特点,显著减少了中间推理过程中的 token 数量,从而降低了延迟和计算成本。实验结果表明,尽管 CoD 生成的中间草稿极为简洁,但在多数任务上其准确率与传统 CoT 相当甚至略有超越,为大规模语言模型在实际应用中的高效推理提供了有力支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









