






论文链接:https://arxiv.org/pdf/2502.02737
论文详细解读
1. 引言
-
研究动机与背景
- 当前大型语言模型(LLM)虽然在多项任务上取得了突破性进展,但其参数量通常在几十亿甚至更多,这导致了高昂的计算成本和部署难度。
- 针对资源受限的场景,研究者开始探索小型语言模型(参数量在 3 亿到 3 亿以下)的高性能实现途径。
- 本文提出的 SmolLM2 模型具有 17 亿参数,通过数据中心化(data-centric)训练策略,实现了在多项基准测试上超越其他同类小模型(如 Qwen2.5-1.5B、Llama3.2-1B)。
-
主要贡献
- 采用多阶段训练策略,总训练数据量约 11 万亿(11T)tokens。
- 融合了多种数据源:大规模的网络文本、专用数学数据、代码数据以及指令调优数据。
- 针对数据集稀缺或质量低下的问题,提出了新的数据集:FineMath、Stack-Edu 和 SmolTalk。
- 通过小规模消融实验与手动调整数据混合比例,实现了对训练过程的动态干预,从而最大化模型性能。
2. 背景
-
预训练与数据重要性
- 预训练阶段主要依赖大规模文本数据帮助模型捕捉语言结构和储存事实知识。
- 对于小模型而言,数据质量尤为关键,因为其容量有限,更容易受到噪声数据的影响。
- 现有数据预处理流程(如使用分类器过滤、重复数据消除等)在大型模型中已被广泛应用,而本论文则强调如何针对小模型进行“数据中心化”设计。
-
指令调优与偏好学习
- 除了预训练外,模型还需经过指令调优(Instruction Tuning)和偏好学习(Preference Learning)来调整输出,使其更符合用户预期。
- 指令调优使用指令/回答对,让模型学会如何按照指令生成回答;偏好学习则通过比较不同回答的好坏来进一步对齐模型输出。
3. 预训练数据集
论文在这一部分详细介绍了不同数据源及其消融实验的设计。
3.1 消融实验设置
- 实验条件
- 为保证对比公平,所有模型均使用相同的配置:
- 模型结构:基于 Llama 架构的 17 亿参数 Transformer
- 序列长度:2048
- 全局批次大小约 200 万 tokens
- 使用 GPT-2 分词器
- 学习率调度采用余弦退火,初始学习率为 3.0 × 1 0 − 4 3.0 \times 10^{-4} 3.0×10−4
- 每个消融实验均在随机采样的 3500 亿(350B)tokens 上训练,并通过 lighteval 工具在多个基准测试(例如 MMLU、HellaSwag、ARC 等)上进行评估。
- 为保证对比公平,所有模型均使用相同的配置:
3.2 英文网络数据
-
数据来源与处理
- 使用 Common Crawl 数据,通过分类器过滤技术提升数据质量。
- 介绍了两个主要的数据集:
- FineWeb-Edu:1.3T tokens,利用由 Llama3-70B-Instruct 生成的标注进行过滤,内容更倾向于“教育”材料。
- DCLM:3.8T tokens,通过 fastText 分类器过滤,捕捉更为多样化、对话式的内容。
-
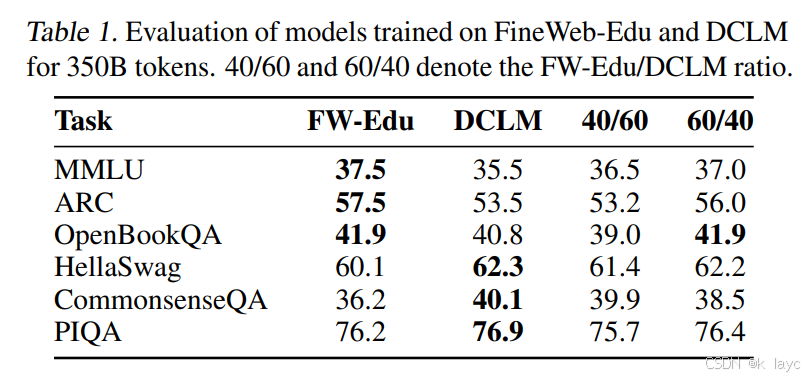
数据混合策略
- 消融实验显示,单独使用 FineWeb-Edu 或 DCLM 会在不同基准上表现出各自的优势。
- 最终将两者以 60%(FineWeb-Edu)与 40%(DCLM)的比例混合,获得了 5.1T tokens 的高质量英文文本,兼顾教育性和对话性。
3.3 数学数据
-
数学数据的重要性
- 对于数学推理能力的提升,精心筛选的数学内容至关重要。
- 现有数学数据集如 OpenWebMath (OWM) 和 InfiMM-WebMath 存在数据量不足及缺乏逐步推理的问题。
-
新数据集 FineMath 的构建
- 通过从 Common Crawl 中提取数学相关页面,并利用 Resiliparse 保留 LaTeX 格式与公式。
- 使用 Llama-3.1-70B-Instruct 进行分类评分(评分范围 1 到 3,3 表示提供了详细的逐步解题过程)。
- 对 FineMath 数据进行去重(采用 MinHash LSH 方法)和语言过滤(使用 fastText 分类器保留英文内容)。
- 构建了 FineMath4+(10B tokens)和 FineMath3+(34B tokens)两个版本,并在 GSM8K、MATH 以及 MMLU-STEM 上表现显著优于旧数据集。
3.4 代码数据
-
代码数据的双重作用
- 除了提升代码生成和理解能力,代码数据对自然语言推理和世界知识也有正向影响。
- 介绍了多个开源代码数据集,如 Stack v1、StarCoderData、Stack v2 以及 StarCoder2Data。
-
Stack-Edu 数据集
- 通过对 StarCoder2Data 进行教育性过滤,构建了 Stack-Edu 数据集,覆盖 15 种主流编程语言,约 125B tokens。
- 采用 StarEncoder 模型对每种语言进行分类过滤,确保数据的“教育”质量,从而在 MultiPL-E 等基准上获得更好的性能。
4. 预训练过程
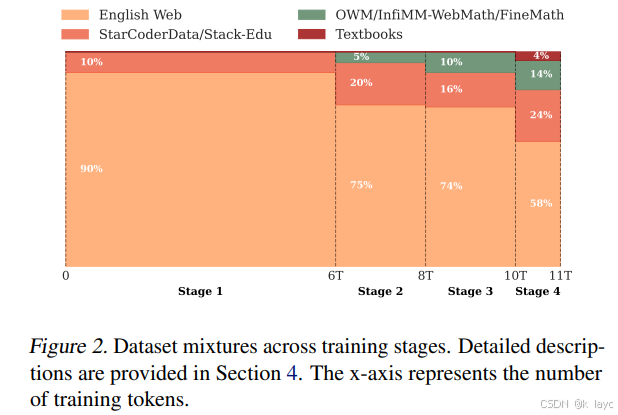
论文采用了多阶段训练策略,根据不同阶段的数据混合比例和任务需求进行调整,整个过程共分为四个阶段:
4.1 训练设置
-
模型与硬件
- 模型架构基于 Llama2,参数量为 17 亿。
- 训练使用 256 个 H100 GPU,采用 nanotron 框架。
- 优化器使用 AdamW,超参数设定为 ( β , β 2 ) = ( 0.9 , 0.95 ) (\beta, \beta_2) = (0.9, 0.95) (β,β2)=(0.9,0.95),并结合 Warmup Stable Decay(WSD)学习率调度。
- 学习率初始值为 5.0 × 1 0 − 4 5.0 \times 10^{-4} 5.0×10−4,并在最后 10% 的训练步骤内线性降至 0。
-
分词器
- 使用由 Allal et al. (2024) 开发的分词器,词汇量为 49,152。
4.2 稳定阶段:阶段 1
- 数据混合策略
- 阶段 1(0 至 6T tokens):采用 60% FineWeb-Edu 与 40% DCLM 的比例作为英文网络数据;代码数据部分采用 StarCoderData,占总混合的 10%;不包含数学数据。
- 目标:确保基础的知识与推理能力,但发现此时编码和数学表现较弱。
4.3 稳定阶段:阶段 2
- 数据混合调整
- 阶段 2(6T 至 8T tokens):在原有混合中增加 5% 的 OWM,并将代码数据比例提高到 20%,同时引入 5% 的数学数据。
- 效果:编码能力明显提升,但数学性能仍需后续增强。
4.4 稳定阶段:阶段 3
- 进一步调整数据混合
- 阶段 3(8T 至 10T tokens):加入了 InfiMM-WebMath 的纯文本部分,数学数据比例上升至约 10%。
- 同时调整英文网络数据中的 FineWeb-Edu 与 DCLM 比例为 40/60,并将代码数据来源替换为 Stack-Edu,还引入了 Jupyter Notebook 数据以丰富代码场景。
- 注意:此阶段出现了明显的损失波动,但最终大部分评估指标恢复。
4.5 衰减阶段:阶段 4
- 衰减与高质量数据注入
- 阶段 4(10T 至 11T tokens):在最后 10% 训练步骤内采用线性降学习率(从峰值降到 0)。
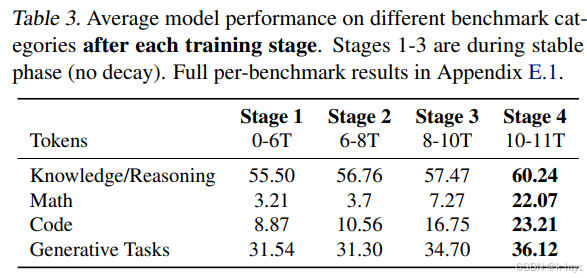
- 此阶段重点注入了最高质量的数学数据(InfiWebMath-3+ 和 FineMath 4+),同时对 OWM 和 AugGSM8K 数据也进行了少量分配;数学数据总占比达 14%,代码数据(扩展后的 Stack-Edu)占比 24%,其余为英文网络数据和 Cosmopedia v2 数据。
- 效果:显著提升了数学与编码任务的性能。
4.6 上下文长度扩展
- 为支持长上下文应用,在阶段 4 的中间检查点之后,将上下文长度从 2k 扩展到 8k。
- 这一过程采用了不同的数据混合比例,并调整了 RoPE 参数(设置为 130k),混合中引入了 40% 的长文本(8k tokens 以上)数据。
4.7 基础模型评估
- 评估对比
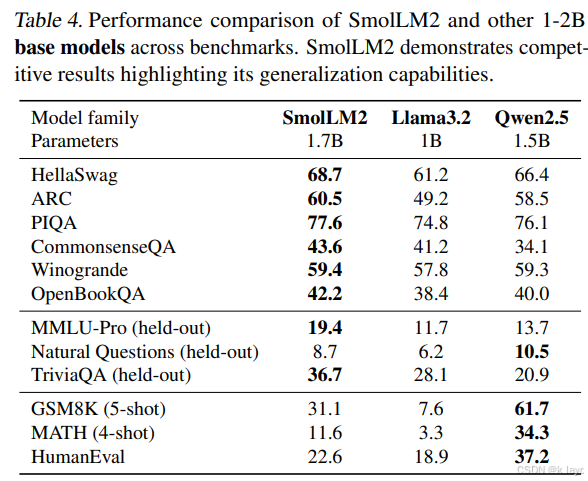
- 在 HellaSwag、ARC、PIQA、CommonsenseQA、Winogrande、OpenBookQA 等多项基准上,SmolLM2 的表现均与 Qwen2.5-1.5B 和 Llama3.2-1B 进行了对比。
- 特别是在 MMLU-Pro、TriviaQA 以及 Natural Questions 等 held-out 基准上,SmolLM2 展现了较好的泛化能力;例如 MMLU-Pro 上领先 Qwen2.5-1.5B 约 6 个百分点。
- 数学和代码任务上,SmolLM2 尽管略逊于 Qwen2.5-1.5B,但优于 Llama3.2-1B。
5. 后训练(Post-training)
在基础预训练完成后,论文还进行了后训练以进一步提升模型的实际应用能力:
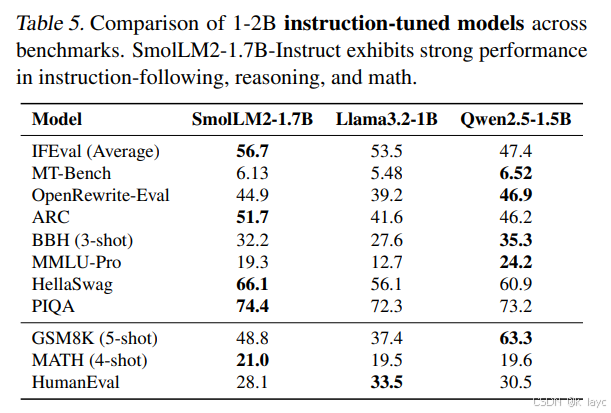
5.1 指令调优(SmolTalk)
-
SmolTalk 数据集
- 针对基础模型在指令调优后表现不佳的问题,构建了新指令数据集 SmolTalk。
- 数据集整合了已有数据(如 MagPie-Pro、OpenHermes2.5)与自生成数据,后者通过 Distilabel 框架生成,并包含了对话、重写、摘要等多种任务。
-
多任务数据
- 除了对话数据(如 MagPie-Ultra,多轮对话生成),还开发了专门的任务数据集:
- Smol-Constraint:包含约 36k 条带有详细约束条件的指令。
- Smol-Rewrite 和 Smol-Summarization:通过对电子邮件、推文等文本进行重写和摘要生成,扩展了模型的指令调优能力。
- 除了对话数据(如 MagPie-Ultra,多轮对话生成),还开发了专门的任务数据集:
5.2 监督微调(SFT)
- 对基础模型在 SmolTalk 数据集上进行了两轮(2 epochs)的监督微调,使用全局批次 128,序列长度 8192,学习率 3.0 × 1 0 − 4 3.0 \times 10^{-4} 3.0×10−4。
5.3 偏好学习(Alignment)
- 采用 Direct Preference Optimization (DPO) 方法,通过多种公开的反馈数据集(如 UltraFeedback、UltraInteract 等)进行训练,进一步调整模型以输出更符合人类偏好的回答。
- 训练设置为 2 个 epochs,学习率为 1.0 × 1 0 − 6 1.0 \times 10^{-6} 1.0×10−6,beta 参数为 0.5,批次大小 128,序列长度 1024。
5.4 指令模型评估
- 经过上述后训练步骤后,最终的 SmolLM2-Instruct 模型在 IFEval、MT-Bench、OpenRewrite-Eval、MMLU、GSM8K、MATH 以及 HumanEval 等多个任务上均表现出较强的指令遵循和任务解决能力。
6. 小模型扩展
- SmolLM2-360M 与 SmolLM2-135M
- 除了 17 亿参数的基础模型,论文还训练了更小的版本:360M 参数(训练 4T tokens)和 135M 参数(训练 2T tokens)。
- 这些小模型采用单阶段训练策略,并在数据预处理上进行了更严格的过滤(例如对 DCLM 数据进行筛选,去除低质量样本),以适应其较低的模型容量。
- 后训练阶段同样对这些模型进行了监督微调和偏好学习,确保在小模型场景下依然保持较好的指令遵循和生成质量。
7. 结论
-
主要结论
- SmolLM2 展示了通过精心设计的数据集和多阶段训练策略,如何使得参数量较小的模型在多个任务上达到接近甚至超越同类大型模型的性能。
- 数据中心化训练(data-centric training)在小模型上尤为重要,通过增加高质量、专用领域数据(数学、代码、指令数据)可以显著提升模型能力。
- 本论文不仅为小型模型的训练提供了详细的实验方法和数据混合策略,还公开了相应的数据集和训练代码,为后续研究提供了良好的基础资源。
-
未来展望
- 随着数据与模型训练技术的不断进步,如何在保持低计算成本的同时进一步提升小模型的泛化能力和任务特定能力仍然是一个开放的研究方向。
8. 总结与评价
-
创新点
- 提出了基于数据中心化的多阶段训练方法,通过不断调整数据混合比例和引入高质量专用数据集(FineMath、Stack-Edu、SmolTalk)提升小模型性能。
- 在预训练和后训练两个阶段均进行了详尽的消融实验,确保各项设计决策都有数据支持。
-
技术细节
- 学习率调度(例如 Warmup 和 线性衰减)以及数据比例的精细调整是论文的重要技术贡献。
- 模型在训练时采用的优化参数和分词器设置均经过精心设计,确保在有限计算资源下充分发挥小模型的潜力。
-
实验结果
- 在多个主流基准测试中,SmolLM2 在知识、推理、数学和代码任务上均展现出优异性能,验证了数据质量与训练策略对小模型的重要性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









