






思考题
-
到目前为止,我们已经使用了哪些LangChain输出解析器?请你说一说它们的用法和异同。同时也请你尝试使用其他类型的输出解析器,并把代码与大家分享。
- PydanticOutputParser:这个解析器使用Pydantic模型来定义输出的结构。它可以将模型的输出解析为Pydantic模型的实例,从而提供了一种结构化和类型安全的方式来处理输出。
- OutputFixingParser:这个解析器用于修复格式不正确的输出。它通过调用一个LLM模型来尝试修复格式错误的输出,使其符合预期的格式。
- RetryWithErrorOutputParser:这个解析器会在解析失败时尝试重新生成输出。它通过再次调用LLM模型来生成新的输出,直到成功解析为止。
这些解析器的用法和异同如下:
-
用法:
- PydanticOutputParser:需要先定义一个Pydantic模型,然后使用该模型来初始化解析器。解析时,将模型的输出字符串传递给解析器的
parse方法。 - OutputFixingParser:需要先定义一个基础解析器(如PydanticOutputParser),然后使用该基础解析器和一个LLM模型来初始化OutputFixingParser。解析时,将格式不正确的输出字符串传递给解析器的
parse方法。 - RetryWithErrorOutputParser:需要先定义一个基础解析器(如PydanticOutputParser),然后使用该基础解析器和一个LLM模型来初始化RetryWithErrorOutputParser。解析时,将格式不正确的输出字符串和提示模板传递给解析器的
parse_with_prompt方法。
- PydanticOutputParser:需要先定义一个Pydantic模型,然后使用该模型来初始化解析器。解析时,将模型的输出字符串传递给解析器的
-
异同:
-
相同点:它们都是LangChain库中的输出解析器,用于将LLM模型的输出解析为结构化的数据。
-
不同点:
- PydanticOutputParser:用于解析格式正确的输出,需要预先定义输出的结构。
- OutputFixingParser:用于修复格式不正确的输出,通过调用LLM模型来尝试修复错误。
- RetryWithErrorOutputParser:用于在解析失败时重试,通过再次调用LLM模型来生成新的输出。
-
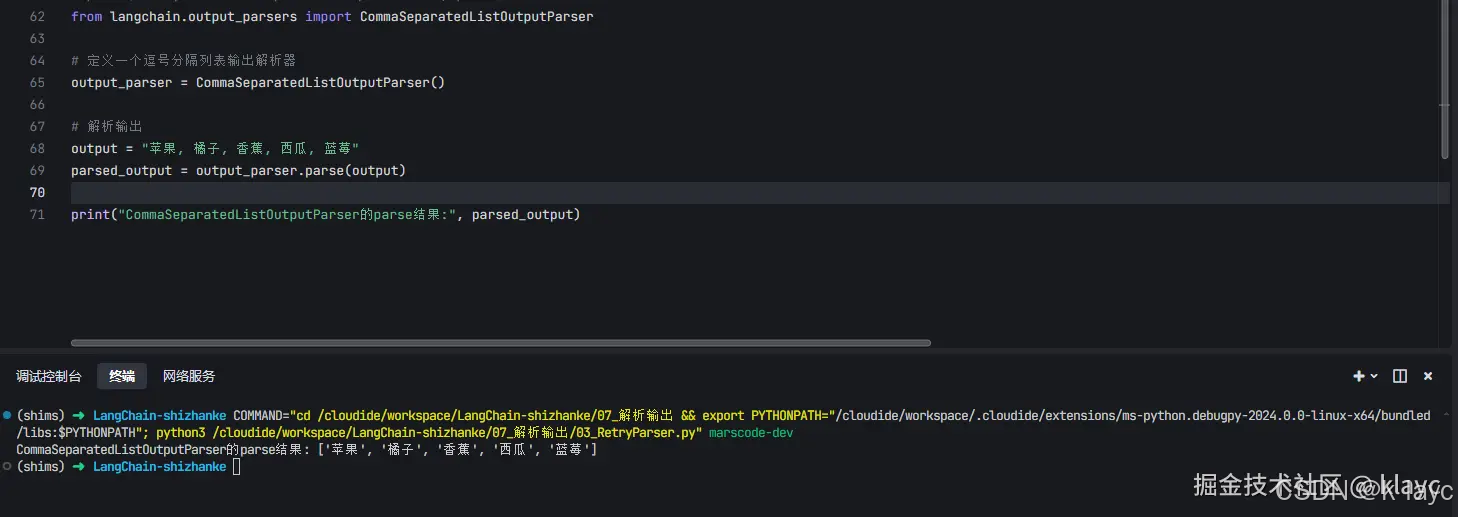
使用CommaSeparatedListOutputParser来解析一个逗号分隔的列表。
2. 为什么大模型能够返回JSON格式的数据,输出解析器用了什么魔法让大模型做到了这一点?
大模型能够返回JSON格式的数据,主要是因为模型在训练过程中学习了如何生成结构化的数据。在自然语言处理(NLP)领域,模型通过大量的文本数据进行训练,学习到了语言的结构和模式。当模型被问及需要以特定格式(如JSON)返回信息时,它会根据学习到的模式生成相应的文本。输出解析器在这个过程中起到了关键作用。它并没有对大模型施加魔法,而是利用了模型的生成能力。输出解析器的工作流程通常如下:
- 模型生成文本:大模型根据输入的提示或问题生成一段文本。
- 解析文本:输出解析器接收到模型生成的文本后,会根据预定义的规则或模式来解析这段文本。例如,如果输出解析器被设计为解析JSON格式,它会寻找文本中的特定模式,如
{}表示对象的开始和结束,,表示属性的分隔,:表示属性名和值的分隔等。 - 数据提取:解析器识别出JSON格式的文本后,会提取出其中的关键信息,如属性名和对应的值。
- 数据结构化:最后,解析器将提取出的信息组织成结构化的数据,如Python中的字典或列表,以便后续的处理和使用。
OutputFixingParser和RetryWithErrorOutputParser都是LangChain库中的输出解析器,它们的作用是将模型生成的文本解析成特定的格式(在这个例子中是Pydantic模型定义的格式)。这些解析器利用了模型的生成能力,并通过预定义的规则来解析和结构化模型的输出。总结来说,输出解析器并没有对大模型施加魔法,而是利用了模型的生成能力和预定义的规则来解析和结构化模型的输出。这使得大模型能够以一种更加结构化和易于处理的方式返回信息。
-
自动修复解析器的“修复”功能具体来说是怎样实现的?请做debug,研究一下LangChain在调用大模型之前如何设计“提示”。
自动修复解析器的“修复”功能是通过调用一个LLM模型来尝试修复格式不正确的输出来实现的。具体来说,当解析器无法正确解析模型的输出时,它会将原始输出和一个提示模板一起发送给LLM模型,请求LLM模型生成一个修正后的输出。这个提示模板通常会包含一些关于如何修正错误的指导信息。在LangChain中,自动修复解析器的实现主要涉及到两个类:
OutputFixingParser和RetryWithErrorOutputParser。这两个类都继承自BaseOutputParser类,并实现了parse或parse_with_prompt方法。 -
重试解析器的原理是什么?它主要实现了解析器类的哪个可选方法?
重试解析器(RetryWithErrorOutputParser)的原理是在解析器无法正确解析模型输出时,通过重试机制来尝试获取正确的解析结果。它主要实现了解析器类的
parse_with_prompt方法。具体来说,当使用
parse_with_prompt方法时,重试解析器会将原始的错误输出和提示模板一起发送给LLM模型,请求模型生成一个修正后的输出。这个提示模板通常会包含一些关于如何修正错误的指导信息。然后,重试解析器会再次尝试使用原始解析器来解析这个修正后的输出。如果解析成功,则返回解析结果;如果解析失败,则可以根据需要设置重试次数或其他逻辑。在LangChain中,重试解析器的实现主要涉及到以下几个步骤:
- 定义重试逻辑:确定在何种情况下需要重试,以及重试的次数限制等。
- 构建提示模板:根据错误类型和上下文信息,构建一个提示模板,用于指导LLM模型生成修正后的输出。
- 调用LLM模型:将原始的错误输出和提示模板一起发送给LLM模型,请求模型生成修正后的输出。
- 再次解析:使用原始解析器再次解析修正后的输出,如果解析成功,则返回解析结果;如果解析失败,则根据重试逻辑决定是否继续重试。
通过这种方式,重试解析器可以在一定程度上提高解析的成功率,尤其是在处理复杂或模糊的输出时。
总结
总结来说,LangChain解析器的主要作用是分析和理解输入数据的结构,无论是自然语言文本还是编程语言代码。它帮助我们提取有意义的信息,进行后续的处理和操作。

















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









