






论文地址 https://arxiv.org/pdf/2402.19427.pdf
代码地址 https://github.com/google-deepmind/recurrentgemma.git
(这是另一篇文章 RecurrentGemma 的代码,但与这里介绍的Griffin相通)
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models

基础想法:用RNN类的结构替换Transformer结构
主要优势:
- 空间/时间复杂度随输入长度线性变化;
- (实验表明)在训练token数较少的情况下能获得不错的效果;
- 更能处理长文本
整体结构如下图:
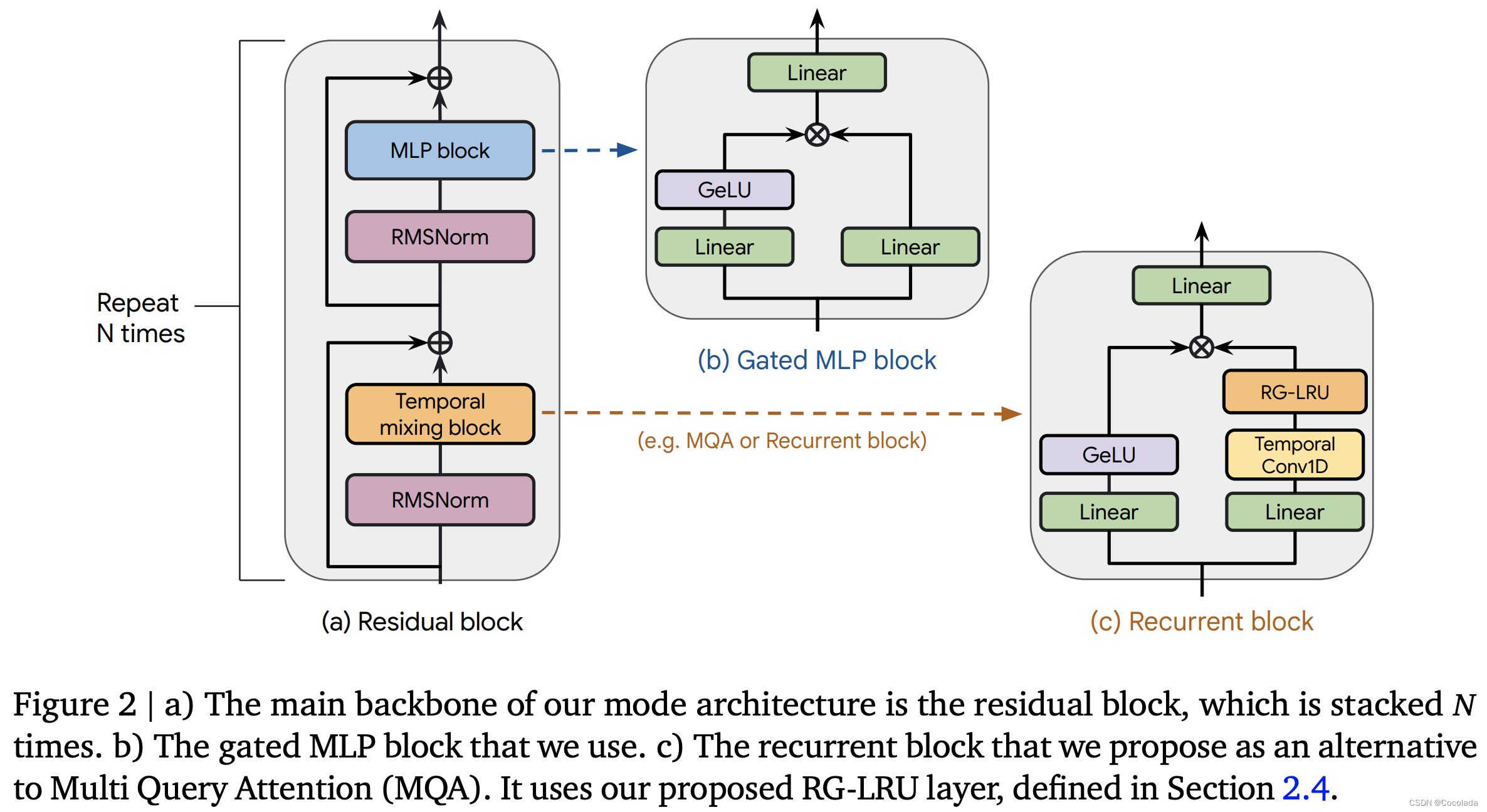
其中:
(b) Gated MLP block:
这是比较常见的MLP实现形式。LLAMA2 也使用了这种MLP模块
© Recurrent block:
带有门结构的循环网络模块。
左半边与(b)相同,组成门。
右半边是循环网络结构。Temporal Conv1D 和 RG-LRU 都是RNN结构。
Temporal Conv1D
这不是我们熟悉的一维卷积。
这是TCN, 可参考https://arxiv.org/pdf/1803.01271.pdf。
具体形式在文章内没详细介绍。下面是基于官方代码整理出来的简易表达形式,非严谨,仅供参考。
输入
x
x
x, 上一步的缓存
h
h
h, 卷积核
w
0
,
w
1
,
.
.
.
,
w
K
w_0, w_1, ..., w_K
w0,w1,...,wK, 偏置
b
b
b,
y
=
cat
(
x
,
h
,
dim
=
1
)
u
=
b
+
∑
t
=
0
K
y
(
t
:
t
+
K
)
w
t
sliding window
h
=
x
(
1
−
K
:
)
last elements with padding as cache
\begin{aligned} y &= \text{cat}(x, h, \text{dim}=1) \\ u &= b + \sum_{t=0}^{K} y(t: t+K) w_t ~~\text{sliding window}\\ h &= x(1-K:)~~ \text{last elements with padding as cache}\\ \end{aligned}
yuh=cat(x,h,dim=1)=b+t=0∑Ky(t:t+K)wt sliding window=x(1−K:) last elements with padding as cache
RG-LRU
文章正文提到的实现为,
σ
\sigma
σ: sigmoid,
a
t
=
σ
(
Λ
)
a_t = \sigma(\Lambda)
at=σ(Λ),
Λ
\Lambda
Λ 可学参数, 加sigmoid在于限制取值区间为
[
0
,
1
]
[0, 1]
[0,1]。
⊙
\odot
⊙: 对应元素相乘。
r
t
=
σ
(
W
a
x
t
+
b
a
)
,
recurrent gate
i
t
=
σ
(
W
x
x
t
+
b
x
)
,
input gate
a
t
=
α
c
r
t
,
h
t
=
a
t
⊙
h
t
−
1
+
1
−
a
t
2
⊙
(
i
t
⊙
x
t
)
.
\begin{aligned} r_t &= \sigma(W_a x_t + b_a), ~~\text{recurrent gate} \\ i_t &= \sigma(W_x x_t + b_x), ~~\text{input gate} \\ a_t &= \alpha^{c r_t}, \\ h_t &= a_t \odot h_{t-1} + \sqrt{1 - a_t^2} \odot (i_t \odot x_t). \\ \end{aligned}
rtitatht=σ(Waxt+ba), recurrent gate=σ(Wxxt+bx), input gate=αcrt,=at⊙ht−1+1−at2⊙(it⊙xt).
在代码中,
a
t
a_t
at 的计算形式为(文章附录有说明)
log
a
t
=
log
a
c
r
t
=
log
σ
(
Λ
)
c
r
t
=
−
softplus
(
Λ
)
⊙
r
t
\log a_t = \log a^{c r_t} = \log \sigma(\Lambda)^{c r_t} = - \text{softplus}(\Lambda) \odot r_t
logat=logacrt=logσ(Λ)crt=−softplus(Λ)⊙rt

















 2510
2510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









