









SVM支持向量机个人总结
最近在学习支持向量机的内容,总感觉对这块的东西比较模糊,为了加深自己的印象以及理解,写一篇note来帮助自己回忆(纯属个人理解,如有错误,烦请改正,谢谢各位!)
1.1简单介绍
支持向量机,也可以叫做大间距分类器,它的目标是当存在两个需要分类的集合的时候,求出一个超平面,能够尽可能保证划分出两种物体。这个超平面需要满足的条件是:
MAX{MIN(每类的点到超平面的最小距离)}

所以也就是说,也就是说两类物体之间的间隔越大越好。
通过对大量数据进行训练之后
他的判别公式是:
f ( w ) = s i g n ( W t X + b ) f(w) =sign(W^tX+b) f(w)=sign(WtX+b)
我们令 Z = W T X + b Z = W^TX+b Z=WTX+b
当Z >0,
f
(
w
)
=
1
f(w) =1
f(w)=1
当Z <0,
f
(
w
)
=
−
1
f(w) =-1
f(w)=−1
接下来注重回答一下我自己在学习过程当中产生的疑惑
//
//
1. 1W是什么?
W W W:代表的是超平面的法向量,这是数学知识,我们都知道,一条直线的系数抽成单独的向量就代表当前直线的法向量。
1.2 W*x是什么?
W
T
x
W^Tx
WTx:我们都知道,向量乘法相当于一个向量在另外一个向量方向上的投影。
W
T
x
W^Tx
WTx就相当于表示
x
x
x在
W
W
W方向上的投影,也就是在x在法向量当中的投影。
由点到直线的距离我们知道,此时如果将W标准化为单位长度,那么
W
T
x
W^Tx
WTx就相当于是再求点到直线的距离。
1.3 b是什么?
b b b:偏置量,不一定过原点。
2. SVM的工作流程
在开始正式介绍SVM的工作流程之前我们先介绍一下核函数,它在SVM当中非常重要。
2.1 核函数
核函数个人认为核函数最简单的理解就是对当前的数据量进行提升维度。在机器学习当中,高纬度数据比低纬度数据更加线性可分。举个例子,如下图所示

我们看左图,他是不容易分隔的,相反,右图是非常容易分离的,我们只需要在空间中画一个平面就可以分割。
核函数就是帮助数据容易分割的。
2.2 核函数的种类
-
线性核函数 (就是没使用核函数)
K ( x i , x j ) = x i T x j K(x_i,x_j)=x_i^Tx_j K(xi,xj)=xiTxj
一般用于线性可分的数据,特点就是不需要考虑调参问题,运行速度也快 -
多项式核函数
K ( x i , x j ) = ( C x i T x j + r ) d , C > 0 K(x_i,x_j)=(Cx_i^Tx_j+r)^d,C>0 K(xi,xj)=(CxiTxj+r)d,C>0 -
高斯核函数(RBF核函数)
K ( x i , x j ) = e x p ( − C ∣ ∣ x i − x j ∣ ∣ 2 ) , C > 0 K(x_i,x_j)=exp(-C||x_i-x_j||^2),C>0 K(xi,xj)=exp(−C∣∣xi−xj∣∣2),C>0
一般用于线性不可分的问题,他的参数很多,因此分类器的效果非常依赖的参数的选取。可以尝试通过交叉验证的方式来逐步改善参数问题 -
sigmoid核函数
K ( x i , x j ) = t a n h ( C x i T x j + r ) K(x_i,x_j)=tanh(Cx_i^Tx_j+r) K(xi,xj)=tanh(CxiTxj+r)
例外说一点:可以通过枚举法来尝试不同核函数的效果
另外吴恩达老师在视频中说:
N是特征的数量,m是训练样本的数量
a) 如果N非常大,(relative to相对于M来说)
一般使用逻辑回归或者线性svm
b) 如果n比较小,m不大也不小
使用高斯和函数的svm
c) 如果n非常小,m又特别大
尝试构建更多的特征,然后用逻辑回归或者线性svm
d) 神经网络能够适合大部分的场景,but他训练速度太慢了。
2.3 工作流程
- 首先拿到一批数据,对每个数据进行中心化操作(标准化,归一化)
- 使用和函数映射到高维,此时的
x
x
x----->
f
(
x
)
f(x)
f(x)

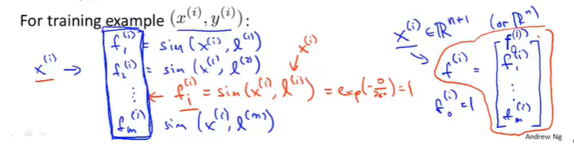
- 求θ,通过以下代价函数
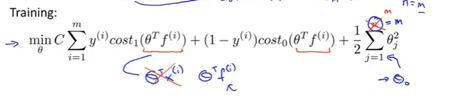
- 开始预测

参考
【1】https://blog.youkuaiyun.com/u011746554/article/details/70941587?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











