







学习ing
如果我们想要修改 tenso r的数值,但是又不希望被autograd记录,那么我么可以对 tensor.data 进行操作
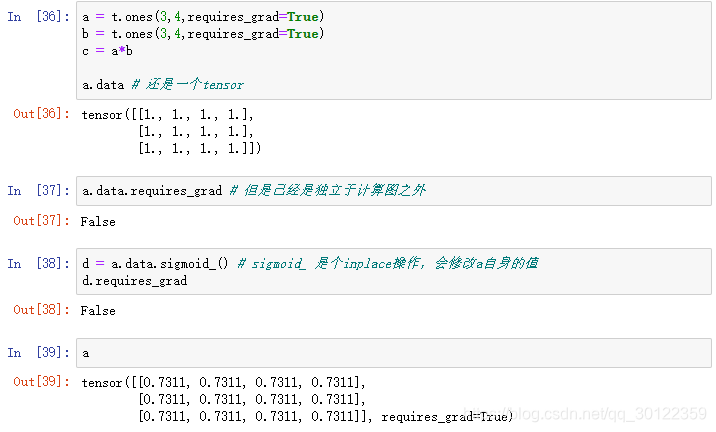
如果我们希望对tensor,但是又不希望被记录, 可以使用tensor.data 或者tensor.detach()
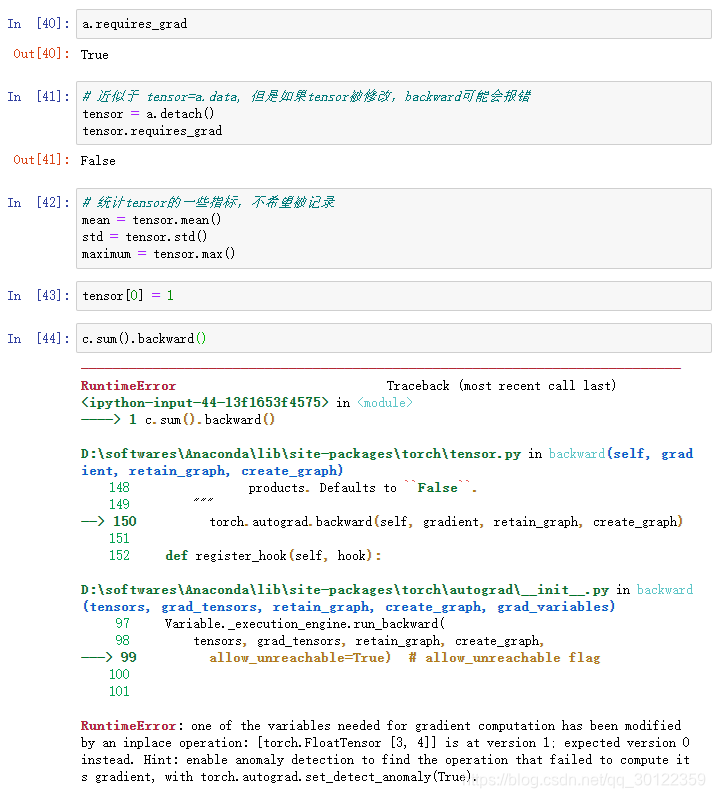
报错是因为 c=a*b, b的梯度取决于a,现在修改了tensor,其实也就是修改了a,梯度不再准确。
学习ing
如果我们想要修改 tenso r的数值,但是又不希望被autograd记录,那么我么可以对 tensor.data 进行操作
如果我们希望对tensor,但是又不希望被记录, 可以使用tensor.data 或者tensor.detach()
报错是因为 c=a*b, b的梯度取决于a,现在修改了tensor,其实也就是修改了a,梯度不再准确。
 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























