




 本文对比了三种目标检测算法:RCNN、SPP-net和Fast-RCNN。RCNN通过Selective Search生成建议区域,使用SVM分类和边框回归,存在计算冗余和存储需求。SPP-net改进了特征提取,但仍有多阶段计算和存储问题。Fast-RCNN引入RoI池化层,将分类和边框回归融合,提高了效率。
本文对比了三种目标检测算法:RCNN、SPP-net和Fast-RCNN。RCNN通过Selective Search生成建议区域,使用SVM分类和边框回归,存在计算冗余和存储需求。SPP-net改进了特征提取,但仍有多阶段计算和存储问题。Fast-RCNN引入RoI池化层,将分类和边框回归融合,提高了效率。
前言
最近在阅读目标检测方向的论文,遇到了很多困惑,尤其是Fast-RCNN算法里面一些细节,一直弄不明白,不禁发出感叹:都是认识的字,怎么放一起就看不懂了呢?所幸刚刚弄明白了,特做个梳理加深记忆。
一、RCNN
流程
一堆图片,对每一张图片都用Selective Search(选择性搜索)算法生成2000个region proposal(建议区域),调整到227*227的尺寸,然后让每一个region proposal,都经过若干卷积池化层提取出来feature map(特征图),最后通过一个全连接层整合成一个固定大小的feature vector(特征向量);再用SVM算法对它们分类;最后利用边框回归算法进行调整。
缺点
- 多阶段,包括提取特征,分类,边框回归
- 占用磁盘空间,SVM算法要对特征进行分类,所以这些特征都是要存下来的
- 计算冗余,1张图的2000个建议框很多事重叠的
二、SPP-net
流程
一堆图片,对每张图片用Selective Search算法生成2000个region proposal,让整张图片经过若干卷积池化层提取出来feature map,接下来是重点了,对于每个region proposal,我们都能在特征图里面找到相应的映射,这里画图解释一下(我当时就是这里没有搞懂)。
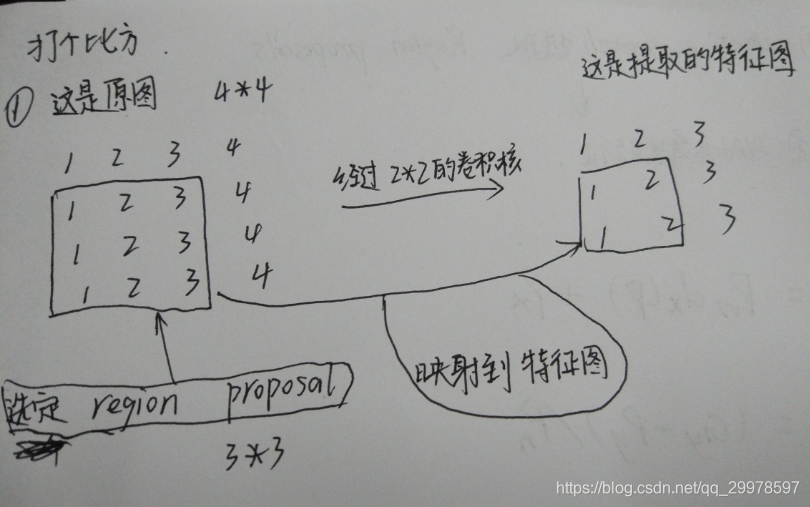
这个方法实在是太巧妙了,RCNN里面要对每一个region proposal进行卷积提取特征操作,这里只用对整张图进行提取,然后在整图产生的特征图里找到region proposal对应位置的映射就好了,减少了大量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









