



 在运行Jupyter时遇到CUDA error(35),解决方法包括检查CUDA驱动版本与PyTorch运行时版本的匹配。通过Pytorch官网选择正确版本的.whl文件,使用pip在Ubuntu终端安装,并确保torchvision的安装。正确操作后,通过命令确认安装成功。
在运行Jupyter时遇到CUDA error(35),解决方法包括检查CUDA驱动版本与PyTorch运行时版本的匹配。通过Pytorch官网选择正确版本的.whl文件,使用pip在Ubuntu终端安装,并确保torchvision的安装。正确操作后,通过命令确认安装成功。
在jupyter 运行时出现这样的错误

查看一下,是否是TRUE

Pytorch官网,选好对应版本,

网速快的直接复制粘贴到Ubuntu终端
网速渣的,下个轮子https://pytorch.org/get-started/previous-versions/#pytorch-linux-binaries-compiled-with-cuda-8

进入PyTorch的下载目录,使用pip命令安装:
pip install torch-1.0.0-cp36-cp36m-linux_x86_64.whl安装torchvision比较简单,可直接使用pip命令安装:
pip install torchvision最后检查一下
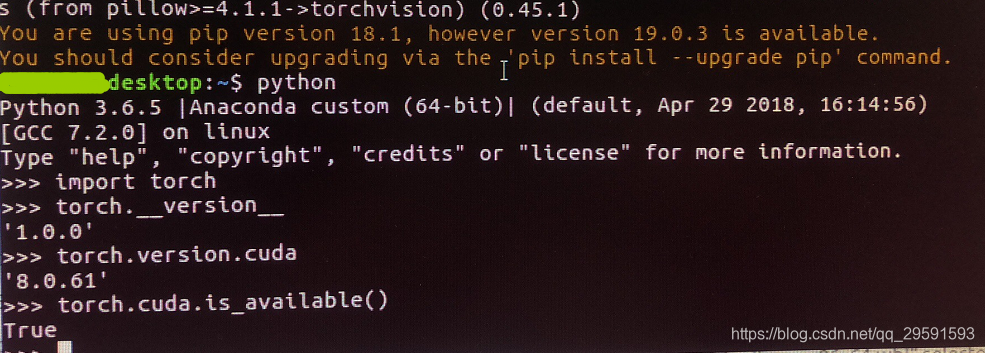
True,ok啦
过程很简单,主要是前期 .whl选错了,再有很蛋疼的就是网速太渣了
涉及的部分博客
https://blog.youkuaiyun.com/red_stone1/article/details/78727096
PS:
查看NVIDIA显卡信息
nvidia-smi
查看CUDA版本
nvcc --version

















 6945
6945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









