






B站一个不错的课程,老师除了开车猛还是有点内容的,适合新手
https://www.bilibili.com/video/av32585321?from=search&seid=8881547171717169037
#coding=utf-8
import requests
import urllib
import json
import jsonpath
#%E7%BE%8E%E9%A3%9F
#https://www.duitang.com/napi/blog/list/by_search/?kw=%E7%BE%8E%E9%A3%9F&type=feed&include_fields=top_comments%2Cis_root%2Csource_link%2Citem%2Cbuyable%2Croot_id%2Cstatus%2Clike_count%2Clike_id%2Csender%2Calbum%2Creply_count%2Cfavorite_blog_id&_type=&start=24&_=1547548611250
url='https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'
label="英雄联盟" #在代码中直接改搜索内容即可下载搜索图片
#转码字符
label=urllib.quote_plus(label)
#print(label)
num=0
for index in range(0,2400,24):
#print(index)
u=url.format(label,index)#转码信息和翻页数字,每一个Jason 文件
# print(u)
we_data = requests.get(u).text #请求网站 并返回网页源代码的文本形式
# print(we_data)
html =json.loads(we_data) #Json格式的字符串解码转换成Python能够识别的
photo =jsonpath.jsonpath(html,"$..path")
# count = jsonpath.jsonpath(html,"$..count")
# print(count)
#print(photo)
for i in photo:
a = requests.get(i)
with open(r"E:\2333\{}.jpg".format(num),"wb") as f:
f.write(a.content)
num+=1
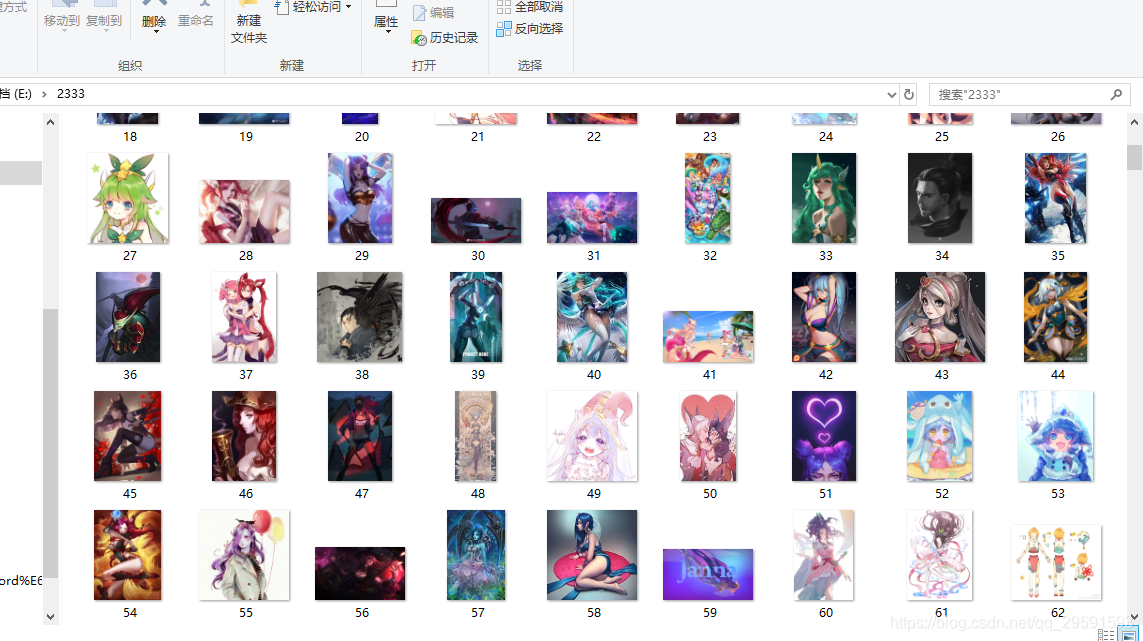
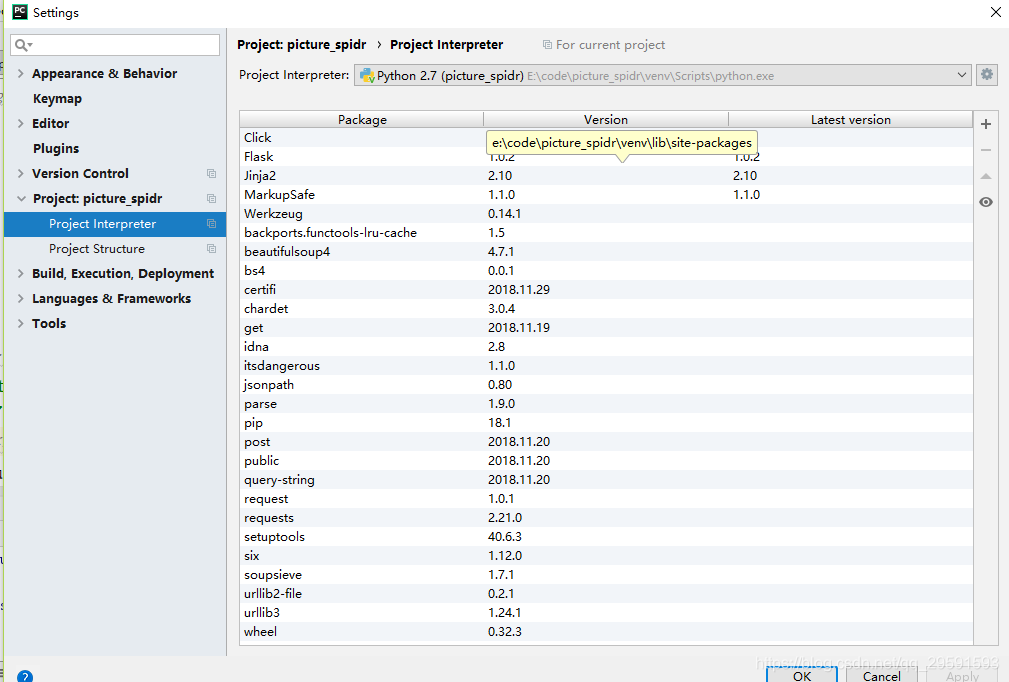
代码运行出来的效果以及运行环境


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









