








Abstract
小样本学习相当于学习表示和获取知识,以便可以在监督和数据有限的情况下解决新颖的任务。通过可同时使用整个测试集的直推式推理和可使用更多未标记数据的半监督学习,可以提高性能。针对这两个设置,我们引入了一种新算法,该算法利用标记和未标记数据分布的流形结构来预测伪标签,同时平衡类并使用有限容量分类器的损失值分布来选择最干净的标签,迭代地提高伪标签的质量。
代码:
https://github.com/MichalisLazarou/iLPC https://github.com/MichalisLazarou/iLPC
https://github.com/MichalisLazarou/iLPC
Introduction
小样本学习正在挑战深度学习范式,因为不仅监督是有限的,而且数据也是有限的。尽管元学习 最初有希望,但迁移学习在将表示学习与学习有限数据上的新任务解耦方面正变得越来越成功。半监督学习是处理有限监督的主要方法之一,实际上,它的小样本学习对应物是微型版本,其中标记和未标记数据按比例受到限制,而表示学习可以解耦。这些方法更接近于直推式推理 ,后者是深度学习之前的半监督学习的支柱。
在这项工作中,我们利用这些想法来改进直推和半监督的小样本学习。如图 1 所示,着重于直推,给出了一组标记的支持示例 S 和未标记的查询 Q,通过映射 f 在特征空间中表示。通过标签传播,我们获得了一个将示例与类相关联的矩阵。对应于未标记示例的子矩阵 P 使用 Sinkhorn-Knopp 算法对示例和类进行归一化,假设类上是均匀分布的。我们从 P 中提取伪标签,我们按照 O2U-Net 对其进行清理,每个类只保留一个示例。最后,受的启发,我们将这些示例从 Q 移动到 S 并迭代直到 Q 为空。
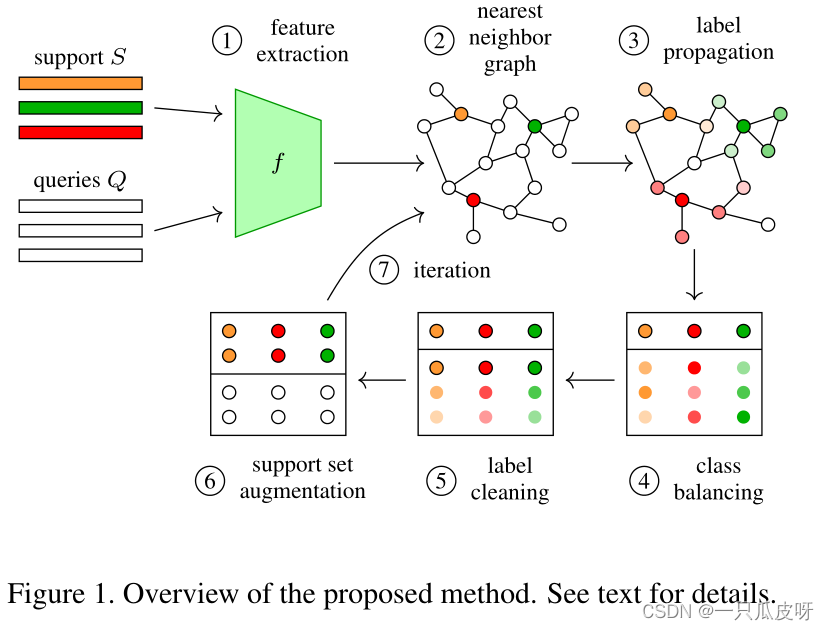
Method
1 问题定义
在表示学习中,我们假设访问标记数据集 Dbase,每个示例在 Cbase 中的一个类中都有一个标签。该数据集用于学习从输入空间 X 到 d 维特征或嵌入空间的映射 f : X→ 𝑅^𝑑。
在表示学习中获得的知识用于解决新任务,假设访问数据集 Dnovel,每个示例都与 Cnovel 类之一相关联,其中 Cnovel 与 Cbase 不相交。 Dnovel 中的示例可以标记或不标记。
在小样本分类中,通过从 Dnovel 采样支持集 S 来定义一项新任务,该支持集由 N 个类组成,每个类有 K 个标记示例,总共有 L := N K 个示例。给定映射 f 和支持集 S,问题是学习一个 N-ways分类器,该分类器对也从 Dnovel 采样的未标记查询进行预测。查询彼此独立处理。这被称为归纳推理。
在直推式推理中,由 M 个未标记示例组成的查询集 Q 也是从 Dnovel 中采样的。给定映射 f、S 和 Q,问题是对 Q 进行预测,而无需学习分类器。这样做时,可以利用 Q 中示例的分布,这很重要,因为假设 M 大于 L。
在半监督小样本分类中,还从 Dnovel 中采样了 M 个未标记示例的未标记集 U。给定 f 、 S 和 U ,问题是学习对来自 Dnovel 的新查询进行预测,就像在归纳推理中一样。同样,M > L,我们可以利用 U 的分布。
2 最近邻图

我们构建了 V 中特征的 k-最近邻图,由稀疏 T × T 非负亲和矩阵 A 表示,其中:
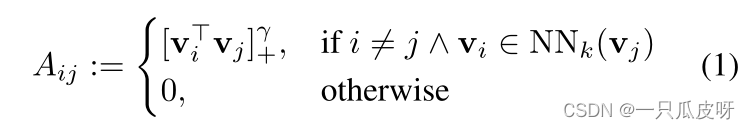
然后我们获得对称的TXT的邻接矩阵W:
最后,进行归一化:
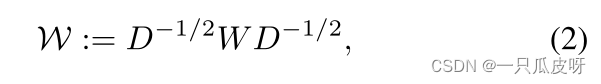
3 标签传播
我们将 T × N 标签矩阵 Y 定义为:
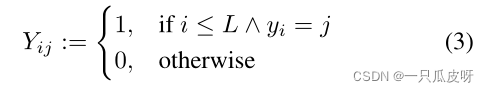
矩阵 Y 每个类一列,每个示例一行,它是 S 的 one-hot 编码标签和 Q 的零向量。也就是说,每行是一个样本的向量,支持集为独热编码,查询集为零向量。
标签传播相当于求解 N 个线性系统:
![]()
在做出预测之前,我们会平衡类别。
4 平衡类别
我们关注 M × N 子矩阵:
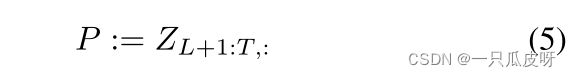
对应于未标记查询的 Z 的(最后 M 行)。
我们首先执行元素级幂变换:

我们将 P 归一化为给定的行式总和 p∈ 𝑅𝑀 和列式总和 q∈ 𝑅𝑁 。p 的每个元素 pi∈ [0, 1] 表示对于 i∈ [M] 的示例 𝑥𝐿+𝑖 的置信度;它可以是 P 的第 i 行的函数或设置为 1。q 的每个元素 𝑞𝑗≥ 0 表示 j∈ [N] 的 j 类权重。在没有此类信息的情况下,我们设置:
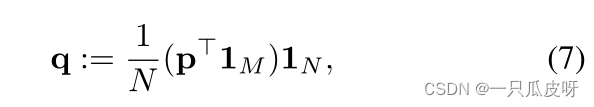
假设查询在类上均匀分布。
归一化本身是 P 在非负 M × N 矩阵的集合 S(p, q) 上的投影,该矩阵具有行和 p 和列和 q,
![]()
我们使用 Sinkhorn-Knopp 算法进行这个投影,它在重新缩放 P 的行以求和为 p 并将其列重新缩放以求和为 q 之间交替,直到收敛。
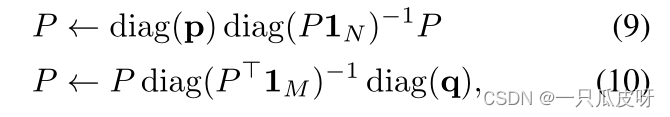
最后,对于每个查询 xL+i, i∈ [M ],我们预测伪标签:
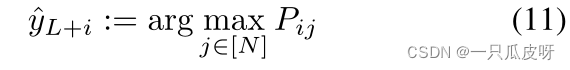
5 标签清理
预测的伪标签不一定正确,但分类器可以对此类噪声具有鲁棒性。当有足够的数据可用于调整表示 时,就会出现这种情况,这样伪标签的质量会随着训练而提高。由于这里的数据有限,我们希望在 Q 中选择最有可能正确的伪标记查询,将它们视为真正标记并将它们添加到支持集 S。迭代此过程是提高质量的另一种方法的伪标签。

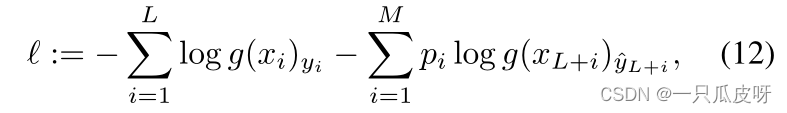
其中 pi 是示例 𝑥𝐿+𝑖 的置信度权重。
对应于伪标记查询 𝑥𝐿+𝑖 的损失项ℓi :=−pi log g(xL+i)^yL+i 用于选择。在 O2U-Net之后,我们使用大学习率并收集所有时期的平均损失 ¯li,对于 i∈ [M]。在使用噪声标签进行学习时,通常会根据干净和噪声标签的损失统计数据来检测噪声标签。然而,这不适用于预测的伪标签,因此我们选择平均损失最小的查询。由于我们迭代了这个过程,我们采取了每个类选择一个查询示例的极端情况:
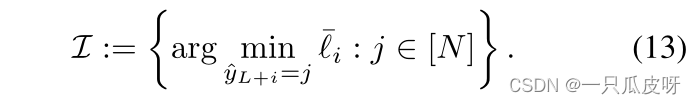
最后,我们用选定的查询及其伪标签来扩充支持集 S,同时从 Q 中删除选定的查询:
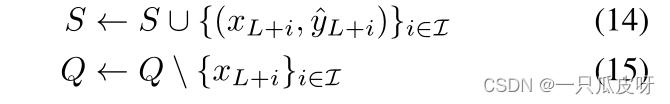
6 迭代推理



















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









