




 本文介绍了伪标签(Pseudo-Label)在半监督学习中的应用,核心思想是利用训练模型为无标签数据生成伪标签,并结合熵正则化进行模型训练。文章提到了去噪自动编码器(DenoisingAuto-Encoder,DAE)作为预训练方法,并展示了在有限有标签数据情况下,如何通过调整权重系数平衡有标签和无标签数据的损失函数,以提高模型性能。实验结果显示,伪标签方法在数据量较少时能显著提升模型效果。
本文介绍了伪标签(Pseudo-Label)在半监督学习中的应用,核心思想是利用训练模型为无标签数据生成伪标签,并结合熵正则化进行模型训练。文章提到了去噪自动编码器(DenoisingAuto-Encoder,DAE)作为预训练方法,并展示了在有限有标签数据情况下,如何通过调整权重系数平衡有标签和无标签数据的损失函数,以提高模型性能。实验结果显示,伪标签方法在数据量较少时能显著提升模型效果。
Pseduo-Label
论文地址:Pseduo-Label
从DAFomer溯源到的论文
伪标签的介绍
伪标签的介绍可以参考:伪标签(Pseudo-Labelling)——锋利的匕首,详细介绍了什么是伪标签方法以及伪标签方法的分类,本论文用到的方法就是上文中的 创新版伪标签的方法(将没有标签的数据的损失函数也加入进来,就是最后公式后边那一坨,具体如下图)
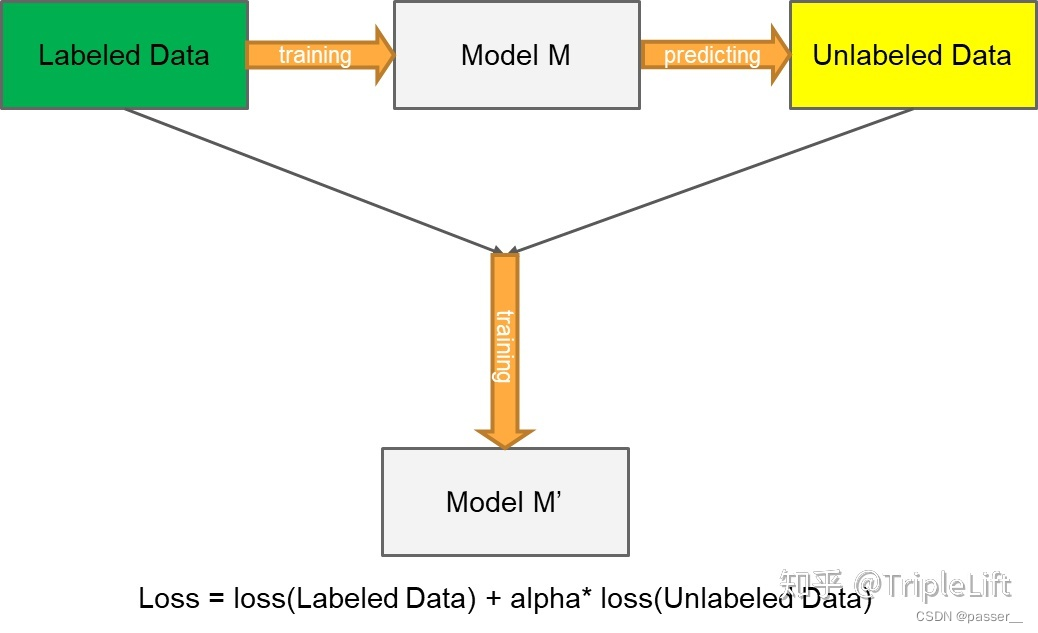
论文介绍
核心思想
Pseudo-Label 模型作为一个简单、有效的半监督学习方法早在 2013年就被提出,其核心思想包括两步:
- 第一步:运用训练出的模型给予无标签的数据一个伪标签。方法很直接:用训练中的模型对无标签数据进行预测,以概率最高的类别作为无标签数据的伪标签
- 第二步:运用 entropy regularization(熵正则化化) 思想,将无监督数据转为目标函数的正则项(如下文公式)。实际中,就是将拥有伪标签的无标签数据视为有标签的数据,然后用交叉熵来评估误差大小
相关流程
使用有标签数据和无标签数据同时以有监督的方式训练预训练网络。对于无标签的数据,在每次权值更新时重新计算的伪标签,被用于与监督学习任务相同的损失函数计算(即每次权值更新时,都重新计算伪标签,并将该伪标签当作真是标签用于计算损失函数)。
相关函数
Denoising Auto-Encoder
去噪自动编码器是一种无监督学习算法,基于使学习的表示对输入模式的部分破坏具有鲁棒性的思想。该方法可以用于训练自动编码器,这些微分代数方程组(DAE)可以堆叠起来初始化深度神经网络:
h i = s ( ∑ j = 1 d v W i j x ~ j + b i ) h_i=s(\sum_{j=1}^{d_v}W_{ij}\tilde x_j+b_i) hi=s(∑j=1dvWijx~j+bi)
x ^ j = s ( ∑ i = 1 d h W i j h i + a j ) \widehat x_j=s(\sum_{i=1}^{d_h} W_{ij}h_i+a_j) x
j=s(∑i=1dhWijhi+aj)
● x ~ j \tilde x_j x~j是第 j 个输入值的损坏版本
● x ^ j \widehat x_j x
j是第 j 个输入值的重构
自动编码训练在于最小化 x j x_j xj 和 x ^ j \widehat x_j x
j重构误差(error)。对于二分类输入值,常用的重构误差选择是交叉熵:
L ( x , x ^ ) = ∑ j = 1 d v − x j l o g
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









