







 本文详细介绍了一个基于深度学习的图像分割任务实现流程,包括数据集构建、数据预处理、数据增强、模型训练及评估等关键步骤。文章展示了如何使用PIL、numpy、torch等库进行图像读取、转换和增强,并介绍了自定义数据集类和数据加载器的实现方法。
本文详细介绍了一个基于深度学习的图像分割任务实现流程,包括数据集构建、数据预处理、数据增强、模型训练及评估等关键步骤。文章展示了如何使用PIL、numpy、torch等库进行图像读取、转换和增强,并介绍了自定义数据集类和数据加载器的实现方法。
总览
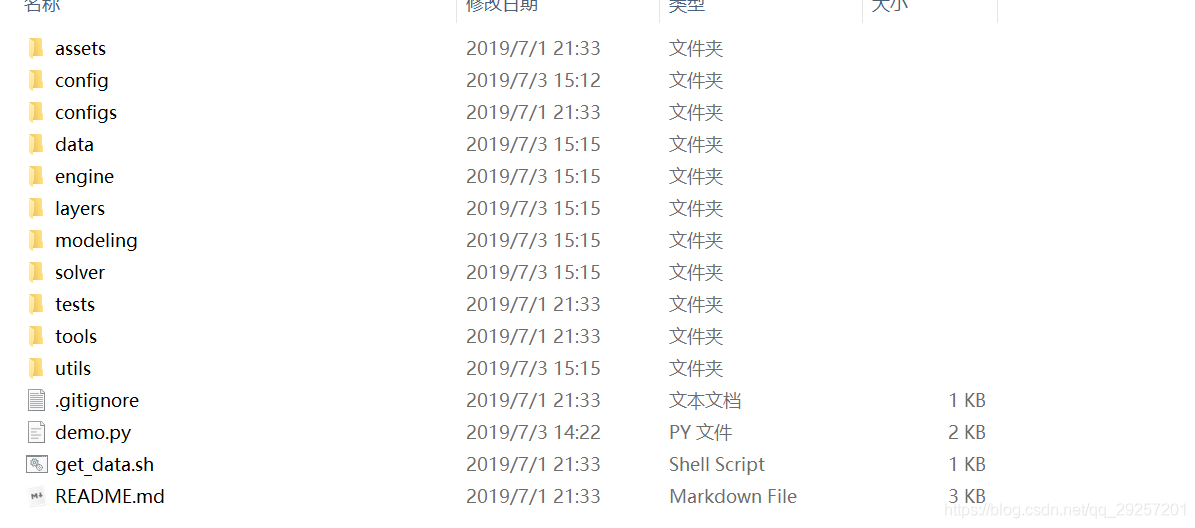
data文件
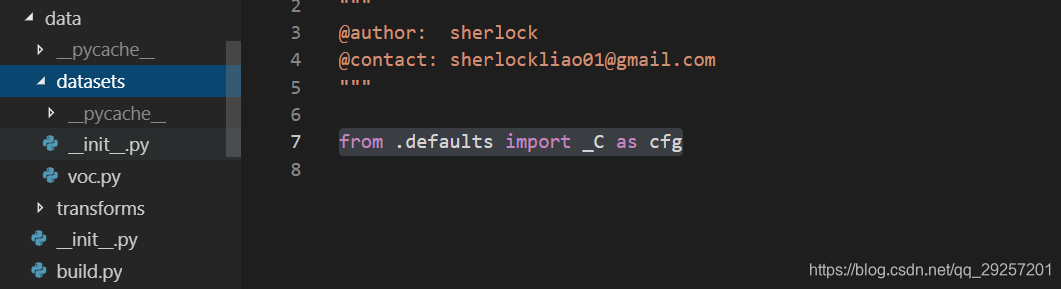
一、dataset
dataset:负责定义个数据库文件,__init__.py 空文件,申明dataset文件是package
import os
import numpy as np
from PIL import Image
from torch.utils import data
# 根据root,读每个文件的地址
def read_images(root, train):
txt_fname = os.path.join(root, 'ImageSets/Segmentation/') + ('train.txt' if train else 'val.txt')
with open(txt_fname, 'r') as f:
images = f.read().split()
data = [os.path.join(root, 'JPEGImages', i + '.jpg') for i in images]
label = [os.path.join(root, 'SegmentationClass', i + '.png') for i in images]
return data, label
class VocSegDataset(data.Dataset):
def __init__(self, cfg, train, transforms=None):
self.cfg = cfg
self.train = train
self.transforms = transforms
self.data_list, self.label_list = read_images(self.cfg.DATASETS.ROOT, train)
def __getitem__(self, item):
img = self.data_list[item]
label = self.label_list[item]
img = Image.open(img)
# load label
label = Image.open(label)
img, label = self.transforms(img, label)
return img, label
def __len__(self):
return len(self.data_list)
二、transforms
transforms负责数据增强和转换,下图可以看下结构布局:
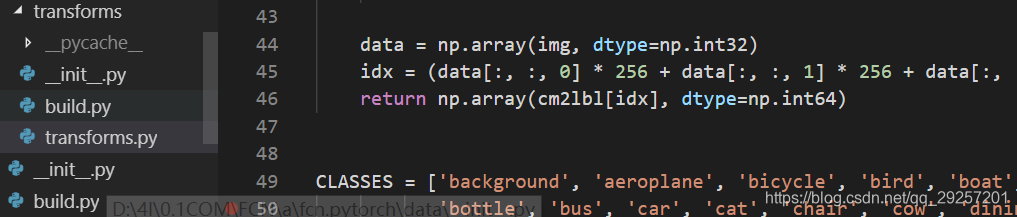
import random
import numpy as np
import torchvision.transforms.functional as F
# 定义数据增强类
# 数据增强类的三个成员函数,__init__,__call__,__repr__
class RandomHorizontalFlip(object):
"""Horizontally flip the given PIL Image randomly with a given probability.
Args:
p (float): probability of the image being flipped. Default value is 0.5
"""
def __init__(self, p=0.5):
self.p = p
# 调用实例的方法,一般是instance.method, instance(),的方法调用__call__函数
def __call__(self, img, target):
"""
Args:
img (PIL Image): Image to be flipped.
Returns:
PIL Image: Randomly flipped image.
"""
if random.random() < self.p:
return F.hflip(img), F.hflip(target)
return img, target
# 程序调试用的函数,返回字符串,比如这里返回:RandomHorizontalFlip(p=0.5)
def __repr__(self):
return self.__class__.__name__ + '(p={})'.format(self.p)
# 返回image大小图像,image:[h, m,3] 变为[h, m, 1]
def image2label(img):
cm2lbl = np.zeros(256 ** 3)
for i, cm in enumerate(COLORMAP):
cm2lbl[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i
data = np.array(img, dtype=np.int32)
idx = (data[:, :, 0] * 256 + data[:, :, 1] * 256 + data[:, :, 2])
return np.array(cm2lbl[idx], dtype=np.int64)
# 映射list
CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable',
'dog', 'horse', 'motorbike', 'person', 'potted plant',
'sheep', 'sofa', 'train', 'tv/monitor']
# RGB color for each class.
COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
[128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0], [192, 0, 0],
[64, 128, 0], [192, 128, 0], [64, 0, 128], [192, 0, 128],
[64, 128, 128], [192, 128, 128], [0, 64, 0], [128, 64, 0],
[0, 192, 0], [128, 192, 0], [0, 64, 128]]
build.py 负责返回两个函数,一个原图——网络图——transforms、网络图——原图——untransforms
import numpy as np
import torch
import torchvision.transforms as T
from .transforms import RandomHorizontalFlip
def build_transforms(cfg, is_train=True):
normalize = T.Normalize(mean=cfg.INPUT.PIXEL_MEAN, std=cfg.INPUT.PIXEL_STD) # 归一化
if is_train:
def transform(img, target):
img, target = RandomHorizontalFlip(cfg.INPUT.PROB)(img, target) # 转换
img = T.ToTensor()(img) # 变为tensor,这里img,应该PIL.image类
img = normalize(img)
# label = image2label(target)
label = np.array(target, dtype=np.int64)
# remove boundary
label[label == 255] = -1 # 这里将背景去掉
label = torch.from_numpy(label) # numpy转为tensor
return img, label
return transform
else:
def transform(img, target): # 测试
img = T.ToTensor()(img)
img = normalize(img)
# label = image2label(target)
label = np.array(target, dtype=np.int64)
# remove boundary
label[label == 255] = -1
label = torch.from_numpy(label)
return img, label
return transform
def build_untransform(cfg):
def untransform(img, target):
img = img * torch.FloatTensor(cfg.INPUT.PIXEL_STD)[:, None, None] \
+ torch.FloatTensor(cfg.INPUT.PIXEL_MEAN)[:, None, None]
origin_img = torch.clamp(img, min=0, max=1) * 255
origin_img = origin_img.permute(1, 2, 0).numpy()
origin_img = origin_img.astype(np.uint8)
label = target.numpy()
label[label == -1] = 0
return origin_img, label
return untransform # 转回原图
__init__.py:还是包管理
from .build import build_transforms, build_untransform
data.build
data文件下的build.py:负责返回一个dataloader 数据加载器
from torch.utils import data
from .datasets.voc import VocSegDataset
from .transforms import build_transforms
def build_dataset(cfg, transforms, is_train=True):
datasets = VocSegDataset(cfg, is_train, transforms)
return datasets
def make_data_loader(cfg, is_train=True):
if is_train:
batch_size = cfg.SOLVER.IMS_PER_BATCH
shuffle = True
else:
batch_size = cfg.TEST.IMS_PER_BATCH
shuffle = False
transforms = build_transforms(cfg, is_train)
datasets = build_dataset(cfg, transforms, is_train)
num_workers = cfg.DATALOADER.NUM_WORKERS
data_loader = data.DataLoader(
datasets, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers, pin_memory=True
)
return data_loader
总结:
通过以上操作,在最终的训练文档中,我们可以通过,from data import make_data_loader ,来实例化一个dataloader。

















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









