







 本文详细介绍了使用Hive处理数据及HDFS文件操作的步骤,包括创建Hive表、上传数据到HDFS、加载数据到Hive、数据转换以及遇到的问题和解决方案。内容涵盖数据上传、加载、统计分析以及Python脚本在Hive中的应用。
本文详细介绍了使用Hive处理数据及HDFS文件操作的步骤,包括创建Hive表、上传数据到HDFS、加载数据到Hive、数据转换以及遇到的问题和解决方案。内容涵盖数据上传、加载、统计分析以及Python脚本在Hive中的应用。
写在前面:
本想使用hive调用python脚本实现统计分析movielens数据,但是最后一步调用脚本的地方不成功没找到问题所在,于是将过程中的一些经验写出来,非常详尽,对新手来说应该挺有用的。
另外调用脚本的程序和报错我会贴出来,应该是脚本写的有问题,后面找到问题或者有人告诉我我会更新。
还拿hive与movie lens数据说事儿。
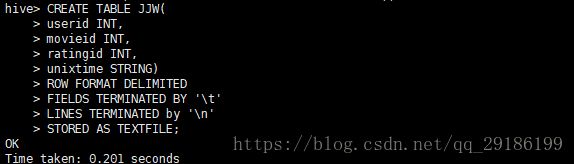
1、首先进入hive数据库创建基表:
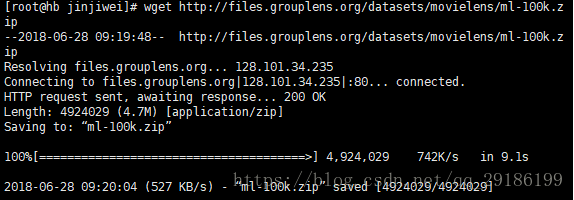
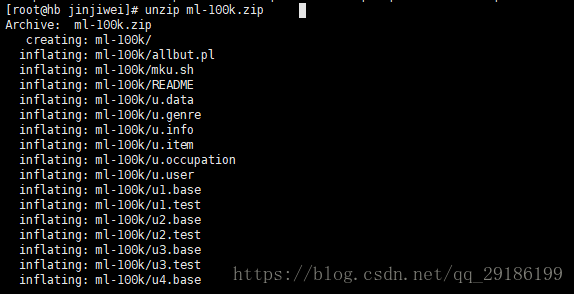
2、在linxu文件工作文件夹下下载数据资源并且解压,我的目录是opt/jskp/jinjiwei:
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip
3、在hdfs上新建自己的工作文件夹,我的是hdfs dfs -mkdir 文件名(JJW)

4、将本地解压的文件上传到hdfs:
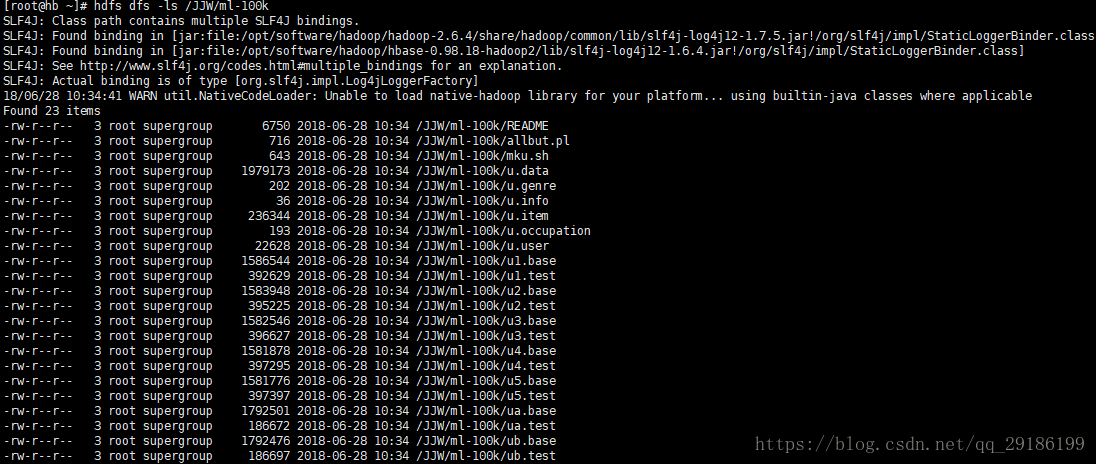
hdfs dfs -put /opt/jskp/jinjiwei/ml-100k /JJW(hdfs目录)在hdfs上面查看上传结果:
5、将ml-100k文件下的u.data文件加载到hive数据库前面建的基表JJW中:

可以看到我第一次加载文件路径是本地路径是错误的,第二次是hdfs上面路径,结果正确,下面验证加载结果:

可以在hive中及进行一些简单的统计如:
6、创建子表JJW_new,用于把基表JJW数据导入子表(因为我调用python脚本不成功,这里就直接导入了)
CREATE TABLE JJW_new (
userid INT,
movieid INT,
rating INT,
weekday INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
7、编写python脚本,功能仅仅将unix时间改为正常时间戳:
import sys
import datetime
for line in sys.stdin:
line = line.strip()
userid, movieid, rating, unixtime = line.split('\t')
weekday=datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([userid, movieid, rating, str(weekday 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









