






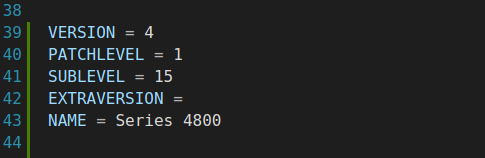
一上来就是版本号
以下是对VERSION、PATCHLEVEL、SUBLEVEL、EXTRAVERSION和NAME的详细解释:
VERSION
定义:VERSION是主版本号,它代表了软件的主要发布版本。
示例:在Linux内核中,VERSION可能被设置为5,表示这是一个主要的发布版本,如5系列的版本。
PATCHLEVEL
定义:PATCHLEVEL是补丁版本号,用于标识在主版本之间的小幅度更新或修复。
示例:在Linux内核中,PATCHLEVEL可能被设置为12,表示这是在主版本5之后的第12次小幅度更新。
SUBLEVEL
定义:SUBLEVEL是次版本号,通常用于进一步细分版本,特别是在开发过程中或当有多个分支同时进行时。然而,在某些情况下,SUBLEVEL可能不被使用或保持为空。
示例:在Linux内核中,如果SUBLEVEL被设置为0,则表示当前没有特定的次版本号。但在其他情况下,它可能被设置为一个具体的数字,以表示更细致的版本控制。
EXTRAVERSION
定义:EXTRAVERSION是附加版本信息,通常用于标识预发布版本、测试版本或包含特定修复的版本。它是一个可选字段,如果为空,则表示这是一个稳定的发布版本。
示例:在Linux内核中,EXTRAVERSION可能被设置为-rc3(rc代表“release candidate”,即发布候选版),表示这是一个预发布版本,并且是该版本的第三个候选发布。
NAME
定义:NAME通常与软件的名称相关,但具体含义可能因上下文而异。在Makefile或其他构建系统中,NAME可能用于指定生成的目标文件名或安装包名的一部分。然而,在直接描述VERSION、PATCHLEVEL、SUBLEVEL和EXTRAVERSION的上下文中,NAME的具体含义可能不那么明确,或者可能不直接关联到这些版本控制字段。
综上所述,VERSION、PATCHLEVEL、SUBLEVEL、EXTRAVERSION和NAME共同构成了软件版本控制系统中的核心元素,它们帮助开发者和用户准确地识别和管理软件的不同版本。 综上所述,上图中表示linux4.1.15稳定版本。
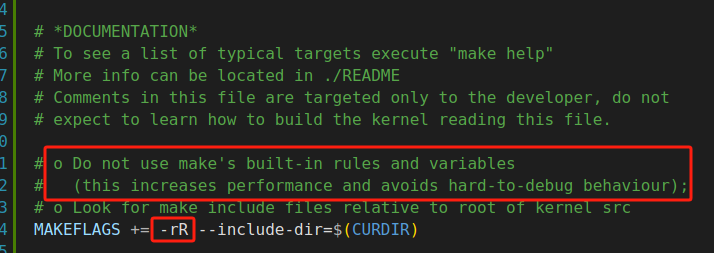
使用-r和-R,linux里建议不要使用make的内置规则和变量,也就是隐含规则和变量,这样做可以提升性能,并且避免产生难以调试的问题。
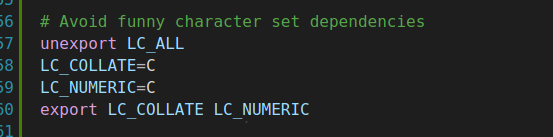
“Avoid funny character set dependencies”
这句话的意思是“避免因使用特殊字符集而产生的依赖问题”。 LC_ALL是一个特殊的环境变量,它用于覆盖所有其他与区域设置相关的环境变量(如LC_COLLATE、LC_CTYPE等)。当设置了LC_ALL的值后,它会强制使所有其他LC_*变量的值与LC_ALL的值保持一致。它不是一个普通的环境变量,而是一个在glibc中定义的宏。通过这个宏的设置,可以一次性地改变程序运行时的整个区域环境。 在Linux系统中,LC_COLLATE=C 和 LC_NUMERIC=C 是与区域设置(locale)相关的环境变量,用于指定程序在排序和数值处理方面的默认行为。以下是对这两个变量的解释:
LC_COLLATE=C
含义:LC_COLLATE 是一个用于指定排序规则的本地化参数。当设置为 "C" 时,它表示使用传统的 C 语言排序规则,即按照字符的 ASCII 值进行排序,不区分大小写,并且不使用任何特殊字符集或语言特定的排序顺序。
影响:这种设置会影响字符串比较和排序的行为。例如,在排序文件名、目录名或其他文本数据时,会按照 ASCII 值的顺序进行排列,而不是根据当前系统的语言环境或文化背景来决定排序顺序。
LC_NUMERIC=C
含义:LC_NUMERIC 是一个与数值(numeric)类型相关的区域设置。当设置为 "C" 时,它表示使用经典的 C 语言格式来显示数值,即小数点为点号(.),不使用千分位分隔符。
影响:这种设置会影响数值的显示格式以及一些数值计算的结果。例如,在显示货币金额时,不会添加货币符号或进行其他格式化;在进行数值计算时,可能会得到更简洁但不够直观的结果。
总的来说,将 LC_COLLATE 和 LC_NUMERIC 设置为 "C" 可以去除本地化设置的影响,使程序在这些方面表现得更加一致和可预测。然而,这也可能意味着失去了一些本地化特性,如特定语言的排序顺序和数值格式。
“avoid interference with shell env settings” 避免干扰shell环境设置。在编程或系统管理中,shell环境设置包含了许多变量、函数、别名等,这些设置会影响命令的执行方式、程序的行为以及输出结果等。有时候,某些操作可能会意外地修改或覆盖这些环境设置,导致不可预期的行为或结果。因此,需要采取措施来避免对shell环境设置造成干扰。 GREP_OPTIONS通常用于设置grep命令的搜索属性或选项,比如是否高亮显示搜索结果等。如果在shell中设置了GREP_OPTIONS变量,并且在子进程中也继承了这个设置,可能会导致一些意想不到的行为或与子进程中的预期设置冲突。通过使用unexport GREP_OPTIONS,可以确保子进程不会受到父进程中GREP_OPTIONS设置的影响,从而按照子进程自己的逻辑和配置来执行相关的操作。 这里的to get the ordering right说的是,我们正在进行递归构建,所以要想点办法来保证构建顺序的正确性。
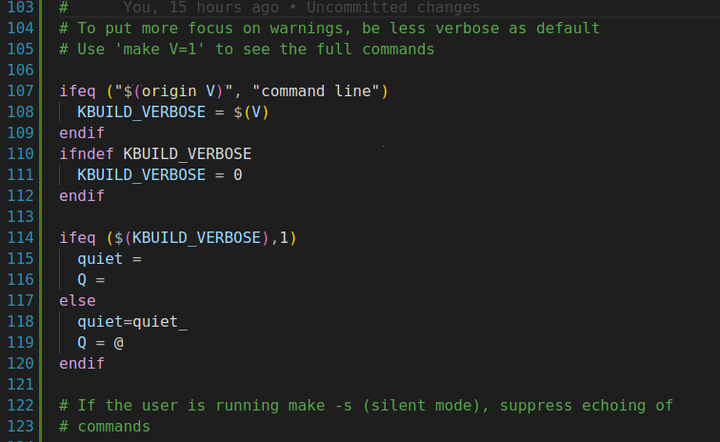
在 Makefile 中,origin 函数用于查询变量的定义来源,它并不会对变量的值进行任何操作。因此,严格来说,origin 函数后面的变量不需要提前定义。 这段话的最终结果就是,如果命令行里在执行make时,指定了变量V=1,那么就会让Q= ,后面会用到Q来让命令都显示出来。
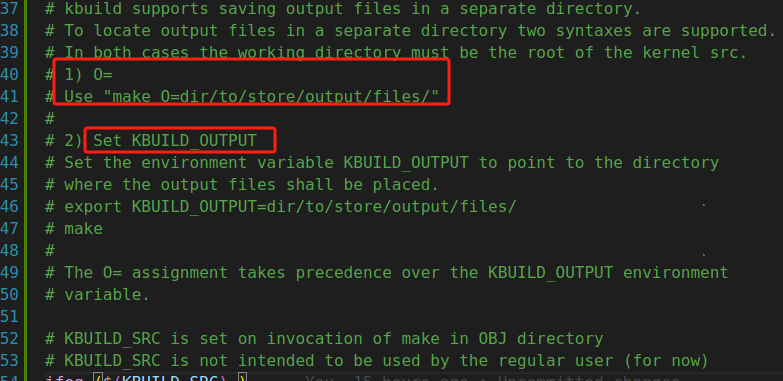
如果不指定V或者V=0,就会让命令静默输出。 接下来主要是指定构建的目标文件的存放路径

有两种方式,一种是命令行里用O变量来指定,另一种就是直接修改顶层Makefile文件里的KBUILD_OUTPUT变量
PHONY变量是用来记录所有的目标的,文件的最后会将PHONY声明为伪目标
在Makefile中,error函数是一个用于生成错误消息并终止Makefile执行的特殊函数。以下是关于它的详细介绍:
基本语法
$(error text...):其中text...是要显示的错误消息,可以是任意文本字符串。
功能作用
当Makefile执行到包含error函数的命令时,会立即输出指定的错误消息,并停止Makefile的进一步执行。这对于在构建过程中检测到严重问题,需要立即中断构建以避免后续步骤产生错误结果或造成更大的损失时非常有用。例如,在检测到某个必要的环境变量未设置、编译所需的工具未安装等情况下,可以使用error函数来中止构建过程。
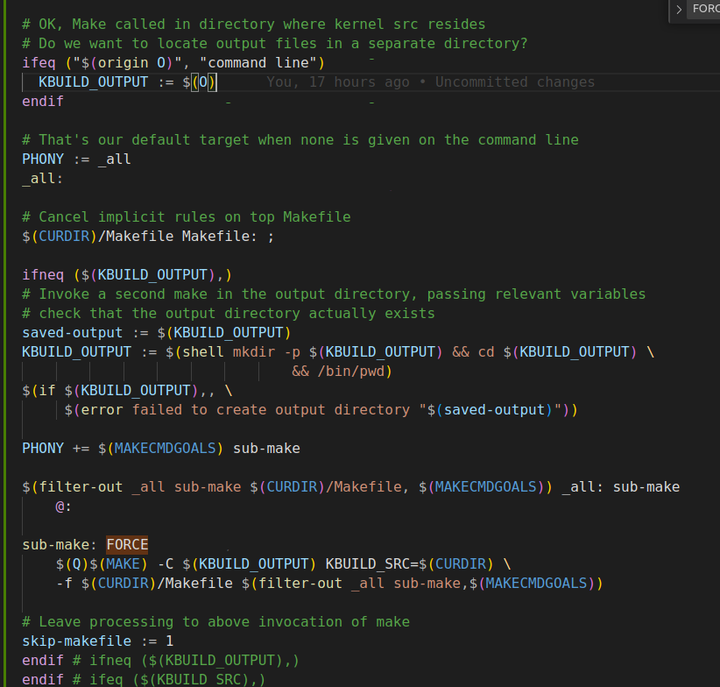

在Makefile中,sub-make是一种用于处理子目录中的Makefile的机制。 当一个项目包含多个子目录,每个子目录下都有自己的Makefile时,sub-make可以让主Makefile调用子目录中的Makefile,从而实现对整个项目的递归构建。在 执行sub-make之前,主Makefile会将一些必要的变量传递给子make过程。这些变量可能包括编译选项、安装路径、目标名称等,以便子Makefile能够根据主Makefile的配置进行正确的构建。
进入子目录并执行Makefile:主Makefile使用特定的命令(如$(MAKE) -C $(dir))进入子目录并执行子目录中的Makefile。这里的$(MAKE)是GNU make工具的命令,-C选项表示切换到指定的目录,$(dir)是一个自动变量,代表当前规则所在的目录。
返回主Makefile:子make过程完成后,控制会返回主Makefile,继续执行主Makefile中的其他操作。 当用户执行make命令时,如果指定了输出路径(使用O=选项),那么主Makefile会在该输出路径下再次运行make,这就是一个典型的sub-make的过程。
在Makefile中,输出目标文件默认会放在当前目录下。 例如,当执行make命令时,如果没有特别指定输出目录,生成的目标文件(如可执行文件、库文件等)通常会被创建在执行make命令的当前工作目录下。这是因为Makefile中规则的定义和执行都是在当前目录的上下文中进行的,除非在规则中明确指定了输出目录,否则就会默认使用当前目录作为输出位置。
MAKECMDGOALS是Makefile中的一个特殊变量,用于记录用户在命令行中输入的终极目标列表,例如,当执行make are you ok cmdgoals时,MAKECMDGOALS的值就是are you ok cmdgoals。它主要用于在Makefile中进行一些特殊的判断。通过检查MAKECMDGOALS的值,可以确定用户指定的目标,从而根据不同的目标执行相应的操作或输出特定的信息。 可见,make可以一次性执行多个目标 方式之一就是在命令行中指定多个目标:直接在 make 命令后面列出多个目标文件,用空格隔开。
例如,如果 Makefile 中有目标 target1、target2 和 target3,那么可以执行 make target1 target2 target3,这样 make 会按照 Makefile 中定义的规则依次构建这些目标。 通常会使用一个特殊的变量(如 skip-makefile)来标记是否要跳过当前 Makefile 的处理。在检测到某些条件满足时(例如,已经设置了输出目录 KBUILD_OUTPUT 等),将该变量设置为 1,表示跳过后续的处理步骤。如果变量的值表示需要跳过处理,那么就不会再执行当前 Makefile 中的其他规则和命令,而是直接结束或者进行一些必要的清理工作。这里是因为指定了目标的输出目录,所以接下来会到目标路径下去执行Makefile,当前Makefile就会不再执行后续内容了。
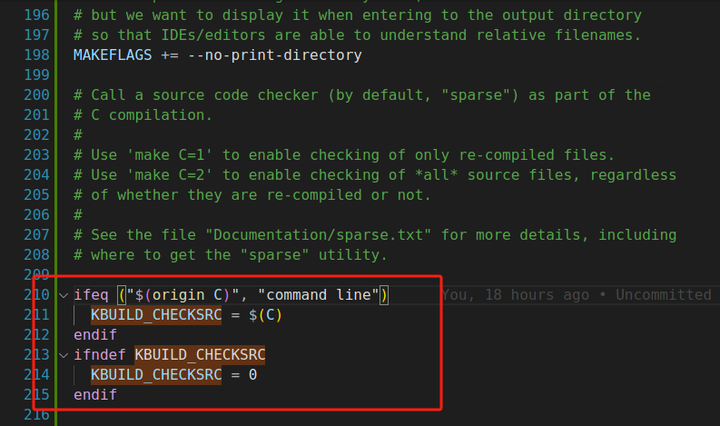
再往下看看代码检查机制
KBUILD_CHECKSRC用于在编译过程中对源代码进行检查。通过设置这个变量,可以指定是否对需要重新编译连接的代码或所有代码进行检查,以发现潜在的问题,如代码风格错误、可能的bug等。 当通过命令行使用make C=1时,KBUILD_CHECKSRC被设置为1,此时只会对需要重新编译的文件进行源码检查。 使用make C=2时,KBUILD_CHECKSRC被设置为2,这会检查所有的源码文件,无论它们是否需要重新编译。 如果未在命令行中指定C的值,那么KBUILD_CHECKSRC默认为0,即不进行源码检查。
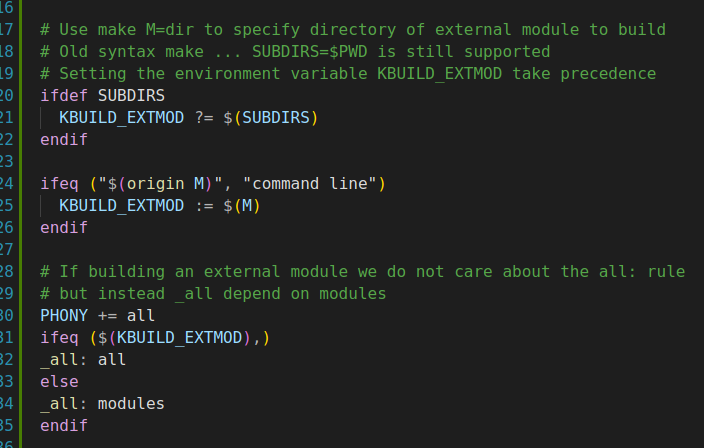
KBUILD_EXTMOD是Linux内核编译系统中的一个重要变量,主要用于在编译外部模块时设置内核源码查找路径。 当需要编译外部模块时,KBUILD_EXTMOD可以帮助Makefile找到正确的内核源码路径。这对于确保外部模块能够正确编译和链接到内核中是非常重要的。 设置方式 命令行指定:可以通过在命令行中使用“M=...”的形式来设置KBUILD_EXTMOD的值。例如,执行“make M=/path/to/kernel/source”命令时,会将KBUILD_EXTMOD设置为指定的内核源码路径。这种方式会覆盖其他可能的设置方式。
环境变量设置:也可以通过设置环境变量来指定KBUILD_EXTMOD的值。如果设置了环境变量KBUILD_EXTMOD或SUBDIRS,那么它们的值也会被用作内核源码查找路径。
优先级关系
如果同时使用了命令行指定和环境变量设置两种方式来配置KBUILD_EXTMOD,那么命令行中的“M=...”设置将会覆盖环境变量中的设置。
这些路径信息之后会给到VPATH变量,VPATH是一个特殊的变量,用于指定额外的搜索路径,指示 make 如何查找文件。当文件夹找不到需要的文件时,VPATH就会被调用。
再接下来就是指定架构和交叉编译器等信息了
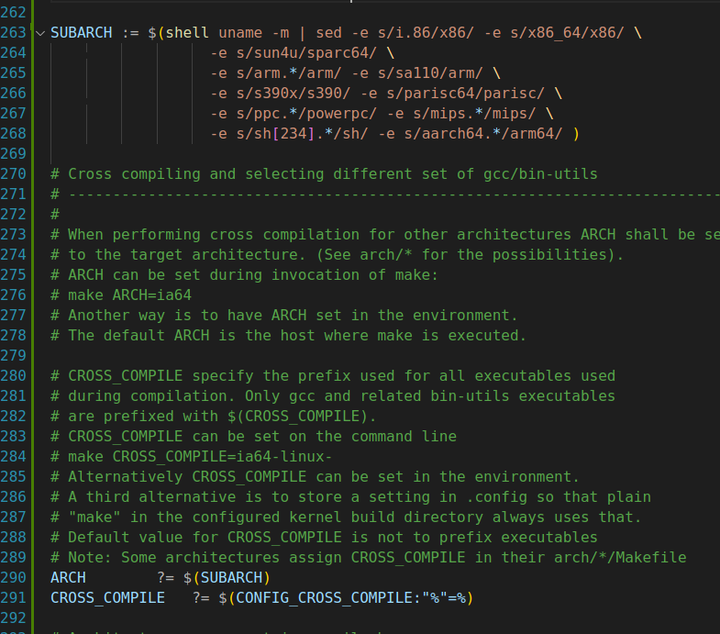
SUBARCH用于指定当前正在构建的体系结构子目录。在Linux内核源码中,不同体系结构的代码通常被存放在不同的子目录下,而SUBARCH变量可以帮助Makefile找到这些与特定体系结构相关的源文件和头文件。
当在配置阶段选择了特定的体系结构(如通过make ARCH=...指定),并且该体系结构有对应的子目录时,SUBARCH会被自动设置为该子目录的路径。例如,如果配置的是ARCH=arm,并且存在arch/arm子目录,那么SUBARCH通常会被设置为arch/arm。
在某些情况下,也可以通过手动设置环境变量的方式来覆盖默认的SUBARCH值,但这种做法相对较少见,一般不推荐除非有特殊需求。
如果同时使用了命令行指定和环境变量设置两种方式来配置SUBARCH,那么命令行中的设置将会覆盖环境变量中的设置。不过在实际的Linux内核编译过程中,很少会出现这种冲突情况,因为通常都是由配置系统根据选择的体系结构自动设置SUBARCH的值。
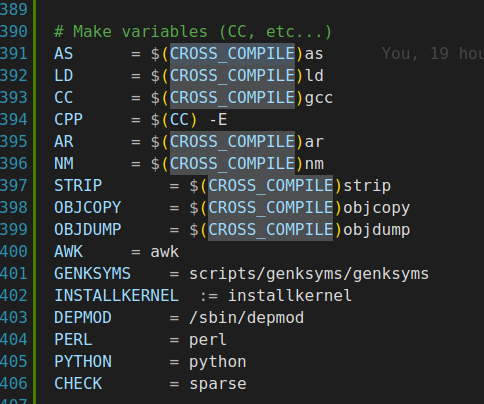
CROSS_COMPILE是交叉编译过程中使用的一个环境变量,在构建系统(如Makefile、CMake等)中配置使用CROSS_COMPILE环境变量指定的交叉编译工具链。在这里使用CROSS_COMPILE环境变量指定工具链的前缀:例如,如果使用的是ARM架构的工具链,并且工具的名称前缀为“arm-linux-gnueabi-”,则可以设置CROSS_COMPILE为这个前缀。这样,当构建系统需要编译器、链接器或其他工具时,它就会知道使用哪个工具链。 因为交叉编译工具链有好多具体的工具,功能不同,但是工具名称的前缀是相同的,后面会根据前缀拼接上后缀,从而指定工具的全名,如下所示:
这里有个.config相关的内容
这表示如果 KCONFIG_CONFIG 环境变量未被设置,则默认使用当前目录下的 .config 文件作为配置文件。

Kbuild 是 Linux 内核开发过程中用于自动化编译和配置的核心机制,以下是关于它的详细介绍:
基本概念
定义与作用:Kbuild 是 Linux 内核构建系统的重要组成部分,它使得内核构建过程更加模块化、可维护和灵活。通过 Kbuild,开发者可以使用简单的 Makefile 配置文件来管理和控制整个内核的编译过程,包括选择编译哪些内核组件、配置编译选项等。
组成结构:主要由 Makefile 和配置文件等组成。Makefile 定义了各种编译规则和目标,而配置文件如 .config 则包含了用户对内核的配置选项,决定了哪些功能和组件需要被编译进内核。
核心功能
自动化编译:根据预设的规则和配置,自动完成内核源代码的编译工作。它会遍历内核源代码树中的各个目录和文件,按照依赖关系依次编译各个模块和组件。
配置管理:允许用户通过多种方式进行内核配置,如使用图形化界面的 make menuconfig 命令或基于文本的 make config 命令等。配置的结果会生成 .config 文件,该文件记录了用户的配置选择,后续的编译过程会根据这个文件来确定需要编译的内容。
模块化支持:可以方便地将内核功能划分为不同的模块,用户可以根据自己的需求选择将某些功能编译为内核模块而不是直接编译进内核,这样可以减小内核镜像的大小,同时提高系统的灵活性。
主要目标与实现细节
vmlinux:这是内核编译过程中的一个重要目标,代表着最终生成的内核镜像文件。Kbuild 会收集所有必要的目标文件(.o 文件)并将它们链接在一起形成 vmlinux 文件。在这个过程中,涉及到众多变量、规则链和链接过程等复杂操作。
modules:用于处理模块化编译的目标。当用户选择了某些功能作为模块编译时,Kbuild 会负责编译这些模块并将其放置在指定的位置,以便在需要时可以动态加载到内核中。
综上所述,Kbuild 是 Linux 内核开发中不可或缺的重要工具,它极大地简化了内核的编译和配置过程,提高了开发效率和代码管理能力。对于从事 Linux 内核开发的人员来说,深入理解和熟练使用 Kbuild 是非常重要的。
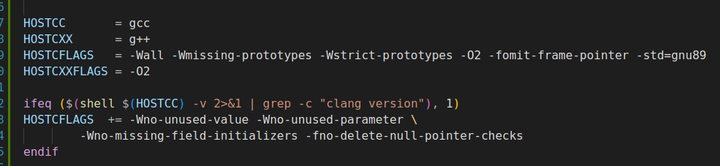
与 CC(通常用于指定目标平台编译器)相对应,HOSTCC 专门用于主机编译器的指定,使得构建系统能够清晰地分辨在不同环境下的编译操作,避免因编译器使用不当而导致的编译错误或兼容性问题。可以在命令行中通过导出 HOSTCC 环境变量来指定主机编译器。例如:export HOSTCC=gcc。这样,在后续的构建过程中,如果没有在构建脚本中明确指定编译器,那么默认就会使用 gcc 作为主机编译器。 内核配置与构建:在 Linux 内核的编译过程中,当进行交叉编译时,除了需要为目标平台指定编译器(如通过 ARCH 和 CROSS_COMPILE 等变量),还需要使用 HOSTCC 来指定主机编译器,以确保在主机上运行的配置文件生成、测试等操作能够正常进行。例如,在配置内核时,可能会执行一些自动检测主机环境的操作,这些操作就需要使用 HOSTCC 指定的编译器来编译相关的检测程序。 嵌入式系统开发中的交叉编译:在开发嵌入式系统时,通常会在性能较强的主机上进行交叉编译,为目标嵌入式设备生成可执行程序。此时,对于在主机上运行的开发工具、测试框架等的编译,就需要使用 HOSTCC 来指定合适的主机编译器,以保证开发环境的正常运行。
接下来就是模块编译的处理
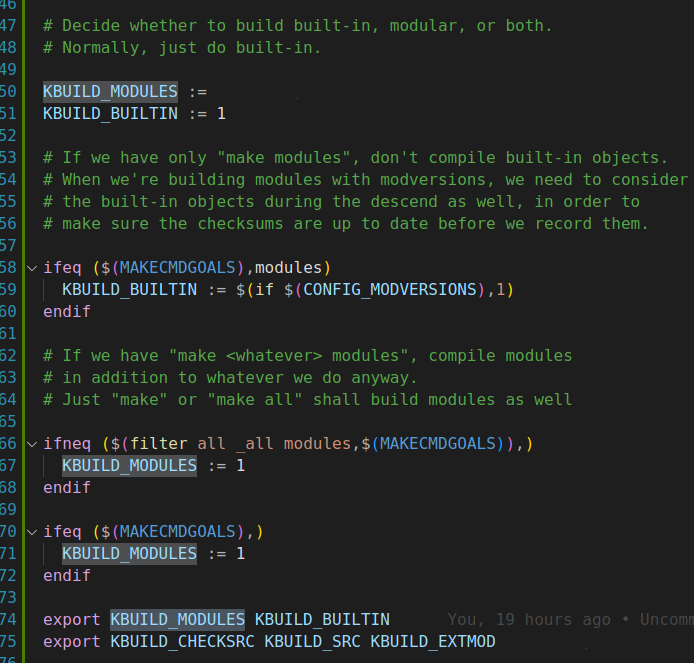
如果执行make时带的目标是modules,这里的内容就会执行 KBUILD_MODULES 用于指定需要进行模块编译的目录或文件列表。在 Linux 内核构建过程中,如果希望将某些代码编译为可加载的内核模块而不是直接编译进内核镜像,就可以通过设置这个变量来告知构建系统。例如,当开发一个新的内核功能或驱动程序时,在开发和测试阶段可能不想将其直接编译到内核中,而是作为一个模块来编译和加载,这时就可以使用 KBUILD_MODULES 来指定相关的源码目录或文件。 控制构建行为:它影响着构建系统对代码的处理方式。如果设置了 KBUILD_MODULES,构建系统会将这些指定的部分按照模块的方式进行编译和链接,生成相应的 .ko 文件(内核模块文件),而不是将它们与其他内核代码一起编译成一个单一的内核镜像文件。这样可以使内核更加灵活,用户可以根据需要动态地加载或卸载这些模块,而无需重新编译整个内核。 在项目的 Makefile 或其他构建脚本中,可以直接引用 KBUILD_MODULES 变量来实现更复杂的构建逻辑。例如:make -C $KDIR M=$(KBUILD_MODULES),其中 $KDIR 是内核源代码树的根目录,M=$(KBUILD_MODULES) 表示在指定的模块目录下进行构建。
再接下来就是设置各种编译选项,以及头文件路径等等
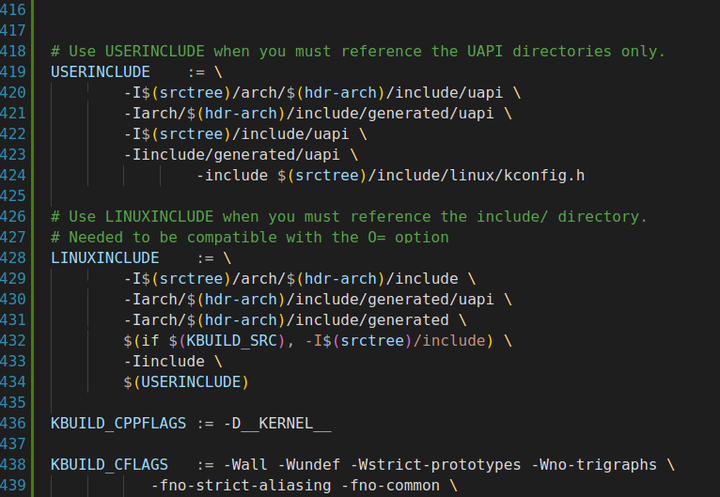
在Linux内核的构建和开发过程中,USERINCLUDE和LINUXINCLUDE是两个重要的变量,它们在内核源码的包含路径管理中扮演着关键角色。 USERINCLUDE 定义:USERINCLUDE 是一个用于指定用户API相关头文件路径的变量。它通常包含了与用户空间程序交互相关的头文件目录。 作用:通过设置 USERINCLUDE,可以确保在编译内核模块或应用程序时,编译器能够找到并包含正确的用户空间头文件。这对于实现内核与用户空间之间的接口、系统调用以及设备驱动编程至关重要。 示例:假设有一个用户空间库的头文件位于 /usr/include/mylib 目录下,为了在编译内核模块时能够包含这个头文件,可以在 Makefile 中设置 USERINCLUDE 变量,如下所示: USERINCLUDE += -I/usr/include/mylib 这样,在编译内核模块时,编译器会搜索 /usr/include/mylib 目录以查找所需的头文件。 LINUXINCLUDE 定义:LINUXINCLUDE 是一个用于指定Linux内核源码头文件路径的变量。它包含了内核的各个子系统和组件的头文件目录,如内核架构相关的头文件、内核通用代码的头文件等。 作用:通过设置 LINUXINCLUDE,可以确保在编译内核模块或内核本身时,编译器能够找到并包含正确的内核头文件。这对于内核开发和模块编写来说是非常必要的,因为只有包含了正确的内核头文件,才能使用内核提供的接口和功能。 示例:在Linux内核源码的顶层Makefile中,通常会定义 LINUXINCLUDE 变量,如下所示: LINUXINCLUDE := -I./arch/$(ARCH)/include \ -I./include \ -I./arch/$(ARCH)/include/generated/uapi \ -I./include/uapi \ -I./include/generated/uapi \include/linux/kconfig.h 这个变量包含了与特定架构相关的头文件目录(如 ./arch/$(ARCH)/include)、内核通用代码的头文件目录(如 ./include)以及自动生成的uapi头文件目录(如 ./arch/$(ARCH)/include/generated/uapi 等)。 总之,USERINCLUDE 和 LINUXINCLUDE 都是在Linux内核开发中非常重要的环境变量,它们分别指定了用户空间头文件和内核空间头文件的搜索路径。正确设置这些变量对于确保编译过程能够正确地找到并包含所需的头文件至关重要。
继续往下看
KBUILD_CFLAGS 是定义在 Linux 内核根目录 Makefile 中的变量,它用于存放传递给 gcc 编译器的编译选项。这些选项适用于整个内核树的构建过程,除非某个文件在被编译时有特殊的要求,否则就会使用 KBUILD_CFLAGS 中指定的编译选项。例如,可以通过修改 KBUILD_CFLAGS 来添加宏定义、优化选项、警告选项等,以控制内核编译的过程和行为。 需要注意的是,从 Linux 内核 2.6 开始,Linux 内核的编译采用 Kbuild 系统,Kbuild 会两次扫描 Makefile。首先读取内核顶层的 Makefile,然后根据读到的内容第二次读取 Kbuild 的 Makefile 来编译内核。在这个过程中,KBUILD_CFLAGS 起到了统一指定编译选项的作用,但对于特定的文件或模块,也可以在相应的 Makefile 中使用其他变量(如 ccflags-y 等)来覆盖或补充 KBUILD_CFLAGS 中的设置。 更多待补充。。。。。。 通常,同一个路由器的WAN口和LAN口通常不在同一网段。因此,如果A和B两个路由器级联,比如A路由器的LAN接B路由器的WAN,这时候A路由器的LAN就是B路由器的WAN,根据“同一个路由器的WAN口和LAN口通常不在同一网段”,那么A路由器的LAN和B路由器的LAN可能就不在同一个网段。 这个问题在什么场景下需要特别关注呢?比如,对于某个路由器A,我们现在让一台音箱连在路由器的wifi上,然后让一台电脑通过网线连接到A路由器上,但是此时如果电脑离A路由器比较远,我们通过B路由器级联A路由器,A路由器的LAN接B路由器的WAN,然后电脑再接到B路由器的LAN上,此时,如果想让音箱和电脑处于同一局域网段,可能就无法实现了,因为这时候,音箱处于路由器A的局域网段内,电脑处于路由器B的局域网段内,二者不处于同一网段,这时候,我们要么把音箱连到路由器B的wifi上,要么就找根长的网线,将电脑接到B路由器的LAN口上。 Objects we will link into vmlinux / subdirs we need to visit 在Linux内核编译过程中,Objects we will link into vmlinux / subdirs we need to visit表示将链接到vmlinux中的对象以及需要访问的子目录。
echo hello 1>&2 啥意思? &是文件描述符,&2 表示标准错误流。
更多参考: https://www.cnblogs.com/cyyz-le/p/11305004.html
接下来看看默认目标
然后接下来就设置了大量的KBUILD_CFLAGS,可自行查阅。 然后就是模块压缩的部分
再后面就是clean/distclean部分内容
再后面就是各种生成规则,其中包括help
等等
补充: 里面也有对make defconfig的处理
还有对make menuconfig的处理
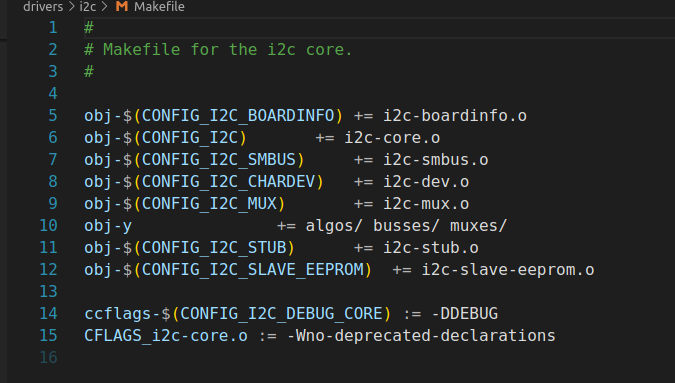
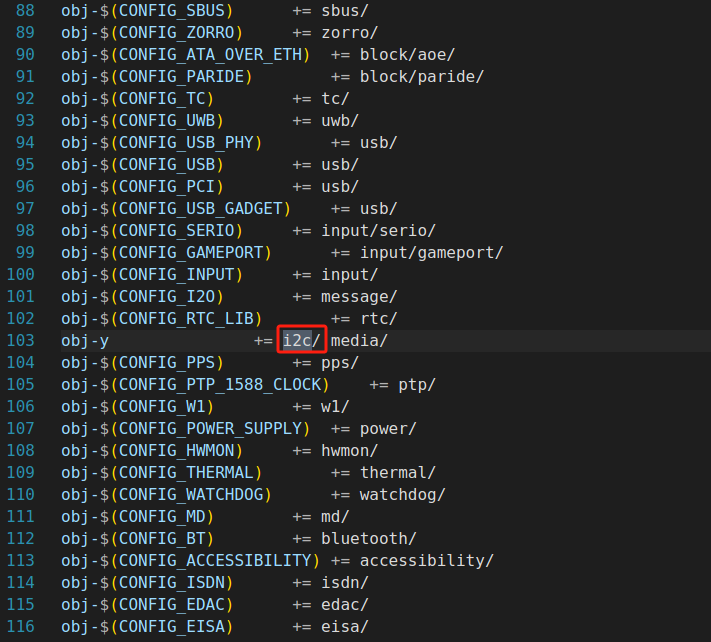
内核各子目录里的文件是如何被加入编译的? 一个关键的变量obj-y
obj-y是怎么起作用的 在Linux内核构建系统中,obj-y是一个至关重要的变量,它用于指定需要编译进内核映像文件的源文件或目标文件。以下是关于obj-y如何起作用的详细解释:
模块编译
obj-y所代表的目标文件会被编译为.o文件,这些.o文件是后续链接生成内核模块或内核映像的基础。
例如在某个内核模块的Makefile中,如果定义了obj-y := module1.o module2.o,那么在执行make命令时,构建系统会将module1.c和module2.c这两个源文件编译成module1.o和module2.o目标文件。
内核链接
Makefile的规则会根据所需的模块链接内核。如果模块的obj-y定义了目标文件,那么这些目标文件将被编译成.o文件,并链接到内核中。
对于一些通用的内核配置,可能会有类似obj-y += main.o sub.o的定义,这表示将当前目录下的main.c和sub.c编译成的目标文件main.o和sub.o要参与到内核的链接过程中。
目录管理
在内核Makefile中,obj-y还可以进行目录管理。如果一个目录包含多个目标文件,可以使用obj-y定义对应目录的路径,Makefile会将目录下所有的.o文件全部链接到内核中。
比如在顶层Makefile中可能会有obj-y += drivers/sound/这样的定义,这意味着会进入drivers/sound目录,根据该目录下的Makefile规则,将其中的目标文件编译并链接到内核。
总的来说,obj-y在Linux内核构建系统中扮演着关键角色,通过指定需要编译进内核映像的文件,控制着内核的构建过程。正确理解和使用obj-y,对于定制和优化Linux内核以满足特定需求至关重要。 这是上一层的
类似于Kconfig,上层通常是包含下一层的目录,然后在有具体文件的那一层指定对应的目标文件。 ccflags-y是Linux内核构建系统中用于定义C编译器的编译选项的一个变量,这些选项仅对当前Makefile文件有效。以下是关于ccflags-y的详细介绍:
基本概念
ccflags-y用于在Makefile中指定特定的编译选项,这些选项会影响C编译器对源文件的编译过程。它类似于常见的编译选项变量,但专门用于Linux内核构建系统,以更精细地控制内核代码的编译行为。
使用场景
添加宏定义:如果在编译某个特定的源文件或一组源文件时需要添加宏定义,可以使用ccflags-y。例如,在一个驱动模块的Makefile中,如果需要为该驱动添加一个特定的宏来启用或禁用某些功能,就可以通过ccflags-y来定义这个宏。这样,在编译该驱动的源文件时,编译器会将这个宏定义应用到编译过程中。
优化编译选项:可以根据不同的需求为特定的源文件或目录设置优化级别的编译选项。比如,对于一些对性能要求较高的内核代码部分,可以通过ccflags-y设置较高的优化级别,如-O2或-O3,以提高生成的二进制文件的执行效率。
调试信息编译选项:在开发和调试阶段,可能需要为内核代码添加调试信息。此时可以使用ccflags-y来添加调试相关的编译选项,如-g,以便在调试器中能够更好地查看代码的执行过程和变量的值。
作用范围
ccflags-y的作用范围仅限于当前Makefile文件所在的目录及其子目录(如果有子目录Makefile且未对其进行特殊处理)。这意味着在不同的目录中可以有不同的ccflags-y设置,以满足不同部分内核代码的编译需求。
与其他编译选项变量的关系
与KBUILD_CFLAGS:KBUILD_CFLAGS是定义在根目录Makefile中的变量,它包含了一些适用于整个内核树的基本编译选项。而ccflags-y则可以在局部(当前Makefile所在目录)覆盖或补充KBUILD_CFLAGS中的选项。如果在某个目录的Makefile中设置了ccflags-y,那么在该目录下的编译过程中,编译器会先使用KBUILD_CFLAGS中的选项,然后再应用ccflags-y中的选项。
与CFLAGS_@:CFLAGS_@是一个特定于目标的编译选项变量,它只在当前Makefile中有效,并且可以为单个文件或一组文件指定特殊的编译参数。相比之下,ccflags-y的优先级通常低于CFLAGS_@,当两者同时存在时,CFLAGS_@中的选项会优先生效。
总的来说,ccflags-y是Linux内核构建系统中一个重要的编译选项变量,它允许开发者在局部范围内灵活地设置C编译器的编译选项,以满足不同部分内核代码的特定编译需求。通过合理地使用ccflags-y,可以更好地控制内核的编译过程,提高内核的性能、可调试性等。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









