






linux启动流程中,最关键的就是找到start_kernel函数
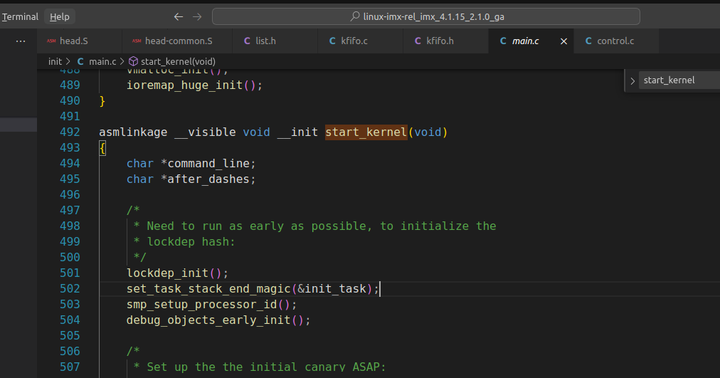
先看第一大块
lockdep_init函数 lockdep_init 函数是 Linux 内核中用于初始化锁依赖(lockdep)模块的函数。以下是对该函数的详细介绍:
作用
初始化哈希链表:在 lockdep_init 函数中,会初始化两个重要的哈希链表,分别是 classhash_table 和 chainhash_table。这两个哈希链表在后续的锁依赖分析中起着关键作用,用于记录和跟踪不同类型的锁及其依赖关系。通过对这些哈希链表的操作,可以有效地管理和分析内核中的锁使用情况,以便检测潜在的死锁等问题。
确保单次初始化:为了避免重复初始化,该函数内部有一个判断条件 if (lockdep_initialized) return;。这意味着如果 lockdep_initialized 已经被设置(表示之前已经完成了初始化),那么函数将直接返回,不再进行后续的初始化操作。这样可以保证在整个内核运行过程中,锁依赖模块的初始化只进行一次,提高了系统的效率和稳定性。
调用场景
架构特定代码调用:在某些架构下,可能有其特定的 start_kernel 函数实现,这个函数中可能会调用 lockdep_init 来初始化锁依赖模块,以确保在该架构下的内核启动过程中正确地设置好锁依赖的相关数据结构和状态。
通用 start_kernel 调用:通常情况下,在内核的主 start_kernel 函数中也会调用 lockdep_init。这是为了保证无论架构如何,都能对锁依赖模块进行统一的初始化,为后续的内核运行提供正确的锁依赖分析基础。
相关配置与文件
配置选项:要使 lockdep 功能在内核中生效,需要在内核配置时打开 CONFIG_DEBUG_LOCKDEP 选项。此外,通常还会打开 CONFIG_LOCK_STAT=y 和 CONFIG_PROVE_LOCKING=y 选项,这些选项与锁相关的统计和验证功能有关,共同协助 lockdep 模块更好地工作。
调试文件:当正确配置并启用了 lockdep 功能后,在 /proc 目录下会出现 lockdep、lockdep_chains 和 lockdep_stats 三个文件节点。这些文件包含了关于锁依赖的信息,可以通过查看这些文件来了解内核中锁的使用情况、锁之间的依赖关系以及可能的死锁风险等,对于内核开发人员进行死锁调试和性能分析非常有帮助。
总之,lockdep_init 函数在 Linux 内核启动过程中扮演着至关重要的角色,它通过初始化锁依赖模块,为内核的稳定运行提供了有力保障。同时,配合适当的配置选项和调试文件,开发人员可以更加方便地进行死锁检测和性能分析,进一步提升内核的可靠性和效率。
set_task_stack_end_magic函数 set_task_stack_end_magic 函数是 Linux 内核中用于设置任务(进程/线程)栈结束标志的函数。以下是对该函数的详细介绍:
函数定义与参数
定义:该函数在 Linux 内核源码中的定义为 void set_task_stack_end_magic(struct task_struct *tsk)。
参数:接收一个指向 task_struct 结构体的指针 tsk,task_struct 是 Linux 内核中用于表示任务的关键数据结构,包含了任务的各种信息,如进程 ID、内存管理信息、堆栈等。
功能作用
设置栈结束标志:函数的主要作用是在给定任务的栈底设置一个特定的魔数(STACK_END_MAGIC)。这个魔数通常是一个预先定义的特殊值,用于标记栈的边界。在 x86 架构中,常见的魔数定义可能为 0xdeadbeef 等,但具体值可能因内核版本和配置而异。通过在栈底设置这个魔数,可以方便后续的栈溢出检测。
检测栈溢出:当任务的栈发生溢出时,溢出的数据可能会覆盖栈底的魔数。内核中的其他部分可以通过检查这个魔数是否被改变来判断是否发生了栈溢出。如果检测到魔数被破坏,就意味着栈可能出现了异常情况,这有助于内核开发者及时发现和调试潜在的安全问题,如缓冲区溢出漏洞等。
实现原理
获取栈结束地址:函数内部首先通过调用 end_of_stack(tsk) 宏或函数来获取任务栈的结束地址,并将其赋值给一个 unsigned long 类型的指针变量 stackend。end_of_stack 的具体实现会根据内核的配置和架构来确定栈的生长方向以及如何计算栈的结束地址。例如,在栈向下生长的情况下,栈结束地址可能是任务的栈指针加上栈的大小;而在栈向上生长的情况下,则可能需要根据任务的 thread_info 结构体的位置等信息来计算。
设置魔数:将 STACK_END_MAGIC 的值写入到 stackend 所指向的内存地址中,这样就完成了栈结束标志的设置。
调用场景
系统初始化:在系统启动过程中,对于一些关键的内核任务,如 init_task(表示系统中的第一个进程),会调用 set_task_stack_end_magic 函数来设置其栈结束标志,以确保这些重要任务的栈在使用过程中能够被正确地监控和保护。
任务创建:当内核创建新的任务时,也可能会调用这个函数来为新任务的栈设置结束标志,以保证新任务的栈安全。
总之,set_task_stack_end_magic 函数在 Linux 内核中扮演着至关重要的角色,通过设置任务栈的结束标志并检测潜在的栈溢出问题,它为系统的稳定运行提供了有力保障。无论是在系统初始化还是任务创建阶段,合理运用此函数都能显著提升内核的安全性和可靠性,降低因栈溢出引发的风险。
smp_setup_processor_id函数 smp_setup_processor_id 函数是 Linux 内核中用于设置对称多处理器(SMP)系统中每个处理器 ID 的函数。以下是对该函数的详细介绍:
作用
获取并设置处理器硬件 ID:在 SMP 系统中,每个处理器都有一个唯一的硬件 ID。该函数从特定的寄存器或系统信息中读取当前正在执行初始化的处理器的硬件 ID,并将其存储到内核中的相关数据结构中,以便后续对不同处理器进行区分和管理。例如,在 ARM64 架构下,它会从 MPIDR(MultiProcessor ID Register)寄存器中读取处理器的硬件 ID。
初始化逻辑处理器映射:除了获取硬件 ID,该函数还会将读取到的硬件 ID 与逻辑处理器编号进行映射。逻辑处理器编号是操作系统内部用于标识和管理处理器的一种抽象编号,通过这种映射关系,操作系统可以更方便地对不同的处理器进行调度、资源分配等操作。
实现原理
读取硬件 ID:具体的实现方式因处理器架构而异。以常见的 x86 架构为例,可能会使用 CPUID 指令来获取处理器的相关信息,包括硬件 ID;而在 ARM 架构下,则是通过读取特定的系统寄存器来获取硬件 ID。
建立映射关系:将获取到的硬件 ID 与逻辑处理器编号进行关联。通常,在内核中会有一个数组或数据结构来存储这种映射关系,以便在需要时能够快速查询和访问。
调用场景
系统启动时:在操作系统启动过程中,当开始初始化 SMP 支持时,会调用 smp_setup_processor_id 函数为每个处理器设置 ID。这是确保系统能够正确识别和管理多个处理器的关键步骤之一。
处理器热插拔时:在一些支持处理器热插拔的系统中,当新的处理器被插入或旧的处理器被移除时,可能需要重新调用该函数来更新处理器的 ID 信息,以确保系统的处理器管理仍然保持正确和有效。
总之,smp_setup_processor_id 函数在 Linux 内核中扮演着至关重要的角色,特别是在对称多处理器(SMP)系统环境下。通过准确获取并设置每个处理器的硬件 ID,以及建立逻辑处理器编号与硬件 ID 之间的映射关系,该函数为操作系统提供了有效管理和调度多处理器资源的基础。
debug_objects_early_init函数 debug_objects_early_init 函数是 Linux 内核中的一个初始化函数,主要作用是在内核启动的早期阶段对用于调试的对象进行初始化。以下是对该函数的详细介绍:
定义位置
该函数的定义位于 lib/debugobject.c 文件中,其完整定义为
void __init debug_objects_early_init(void)。
功能作用
初始化哈希锁:函数中有一个循环,用于遍历 obj_hash 数组中的每个元素,并调用 raw_spin_lock_init 函数来初始化每个元素的 lock 字段。obj_hash 是一个全局变量,通常用于在调试过程中存储和快速查找与对象相关的信息。
初始化静态对象池链表头:另一个循环遍历 obj_static_pool 数组中的每个元素,使用 hlist_add_head 函数将每个元素的 node 字段添加到 obj_pool 链表的头部。obj_static_pool 也是一个全局变量,用于存储预先分配的静态调试对象。
调用场景
在内核启动过程中,当执行到 start_kernel 函数时,会依次调用一系列的初始化函数,debug_objects_early_init 就是其中之一。它在整个内核初始化流程的较早阶段被调用,确保在使用这些调试对象相关功能之前,它们已经被正确地初始化。
依赖关系
此函数的执行依赖于内核配置选项 CONFIG_DEBUG_OBJECTS。如果该配置选项被启用,那么在内核编译时会包含对调试对象的支持代码,并且会在运行时调用 debug_objects_early_init 函数来初始化这些调试对象。如果该配置选项未启用,那么与调试对象相关的代码将不会被编译进内核,自然也不会调用这个初始化函数。
总之,debug_objects_early_init 函数在 Linux 内核启动的早期阶段扮演着至关重要的角色,通过初始化哈希锁和静态对象池链表头,为后续的调试工作奠定了坚实的基础。
boot_init_stack_canary函数 canary金丝雀 boot_init_stack_canary 函数是 Linux 内核中用于初始化堆栈保护机制(也称为“金丝雀”机制)的函数。以下是对该函数的详细介绍:
定义位置
boot_init_stack_canary 函数的定义位于 arch/x86/include/asm/stackprotector.h 头文件中,但实际的实现代码可能分布在不同的架构特定的文件中,例如在 x86 架构下,其实现可能在相关的汇编或 C 文件中。
功能作用
初始化随机值:该函数的主要作用是为当前进程的堆栈保护机制生成一个初始的随机“金丝雀”值。它通过调用 get_random_bytes 函数获取一定长度的随机字节,并将其存储到 canary 变量中。这个随机值将作为后续检测堆栈溢出的重要依据。
混合时间戳:为了增加随机性和不可预测性,函数还会获取当前的时间戳计数器(TSC)的值,并将其与随机值进行混合。具体操作是将 TSC 值加上其自身左移 32 位的结果,然后与随机值相加,得到最终的“金丝雀”值。
设置堆栈保护值:将生成的“金丝雀”值存储到当前进程结构体(current)的 stack_canary 成员中,以便在后续的堆栈操作中进行检测和验证。同时,在一些架构下,还可能会将其写入到特定的寄存器或内存位置,以便硬件或低级软件能够更方便地访问和检查。
调用场景
系统启动阶段:在内核启动过程中,当执行到 start_kernel 函数时,会调用一系列的初始化函数来设置内核的各种状态和数据结构,boot_init_stack_canary 就是其中之一。它在早期就被调用,以确保在系统的其他部分开始运行之前,堆栈保护机制已经就绪。
特定配置启用时:此函数的调用通常由内核配置选项 CONFIG_CC_STACKPROTECTOR 控制。只有当该配置选项被启用时,内核才会在编译时包含堆栈保护的相关代码,并在运行时调用 boot_init_stack_canary 函数来初始化堆栈保护机制。
目的意义
防止堆栈溢出攻击:通过在堆栈上设置一个特殊的“金丝雀”值,并在关键的位置进行检查,如果发现该值被修改,就可以确定发生了堆栈溢出。这是因为大多数堆栈溢出攻击会从内存的低地址向高地址覆盖数据,很可能会覆盖掉“金丝雀”值所在的位置。一旦检测到堆栈溢出,内核可以采取相应的措施,如终止进程、记录日志等,从而提高系统的安全性和稳定性。
增强内核安全性:堆栈保护机制是内核安全防御体系的一部分,它可以有效地防止恶意程序利用堆栈溢出漏洞来攻击内核,获取非法的权限或执行任意代码。通过在内核启动时就初始化好堆栈保护机制,可以为整个系统的安全运行提供更可靠的保障。
总之,boot_init_stack_canary 函数在 Linux 内核中扮演着至关重要的角色,通过初始化堆栈保护机制并设置关键的“金丝雀”值,为系统提供了强大的安全防护能力。这一机制不仅有效防止了堆栈溢出攻击,还增强了内核的整体安全性,确保了系统的稳定可靠运行。
cgroup_init_early函数 cgroup_init_early 函数是 Linux 内核中用于在系统启动早期初始化控制组(cgroup)子系统的函数。 更多略。
local_irq_disable 函数用于屏蔽当前 CPU 上的所有中断,这是为了初期能让linux顺利完成初始化,而不会被其他中断打断,初始化完成后会再次打开。
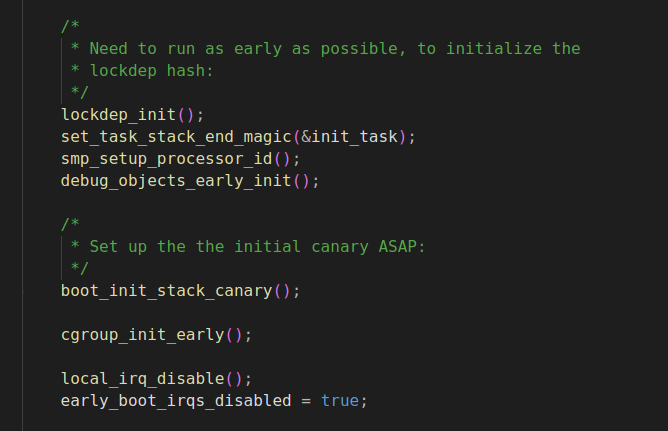
再来看第二大块
这一段是在中断关闭的情况下做一些必要的设置,之后再开启中断。 在Linux内核启动过程中,中断的启用是一个关键步骤。以下是关于在中断仍然禁用的情况下进行必要设置,然后启用它们的详细解释:
一、必要设置
内存管理单元(MMU)初始化
操作:在启用中断之前,必须确保内存管理单元(MMU)已经正确初始化。MMU负责将虚拟地址转换为物理地址,并管理页表项。
原因:如果在MMU未正确设置的情况下启用中断,可能会导致系统无法正确处理内存访问,进而引发错误或崩溃。因此,需要先完成MMU的初始化,以确保内存访问的正确性和稳定性。
设置堆栈指针和初始化页表
操作:
设置堆栈指针:将堆栈指针初始化到合适的位置,通常指向一个预先分配好的内存区域。这是为了确保在中断处理和其他内核操作中,能够正确地使用堆栈来存储临时数据和函数调用记录。
初始化页表:页表是MMU用于地址转换的重要数据结构。在启用中断之前,需要初始化页表,以确保虚拟地址能够正确地映射到物理地址。
原因:堆栈指针的正确设置和页表的初始化是内核正常运行的基础。如果这些设置不正确,中断处理程序可能无法正常执行,或者在访问内存时出现错误。
设备树或其他硬件资源的初始化
操作:
设备树初始化:如果内核支持设备树,需要先解析和初始化设备树。设备树描述了硬件平台的各种设备和资源,内核可以根据设备树的信息来初始化相应的设备驱动程序。
其他硬件资源初始化:除了设备树,还可能需要对其他硬件资源进行初始化,如PCI设备、存储控制器等。这些资源的初始化通常需要在中断启用之前完成,以确保它们在中断处理中能够正常工作。
原因:设备的初始化是确保系统能够正确识别和使用各种硬件资源的关键。如果硬件资源未正确初始化,中断处理程序可能无法与这些设备进行正确的交互,导致系统功能异常。
内核数据结构的初始化
操作:
初始化内核数据结构:包括初始化各种内核链表、哈希表、缓存等数据结构。这些数据结构用于管理内核的各种资源,如进程、内存页面、设备等。
设置内核参数:根据系统配置和启动参数,设置内核的各种参数,如内存大小、CPU频率、设备树地址等。
原因:内核数据结构的正确初始化是内核正常运行的基础。这些数据结构用于支持内核的各种功能,如进程调度、内存管理、设备驱动等。如果数据结构未正确初始化,内核可能无法正常工作,或者在运行过程中出现错误。
二、启用中断
启用中断指令
操作:在完成上述必要设置后,通过执行特定的指令来启用中断。例如,在ARM架构中,可以使用cpsie i指令来使能IRQ中断和FIQ中断。
说明:这条指令会将处理器的中断使能寄存器设置为允许中断的状态,从而使内核能够响应外部设备的中断请求。
确认中断已启用
操作:检查中断使能寄存器的状态,或者通过其他方式确认中断已经成功启用。可以通过读取处理器的相关寄存器或使用调试工具来进行验证。
说明:确保中断已正确启用是非常重要的,否则内核将无法正常处理外部设备的中断请求,影响系统的功能和性能。
总的来说,在Linux内核启动过程中,中断的正确启用是确保系统正常运行的关键环节之一。通过按照上述步骤进行必要设置并启用中断,可以确保内核能够正确地响应外部设备的中断请求,并提供稳定的系统服务。
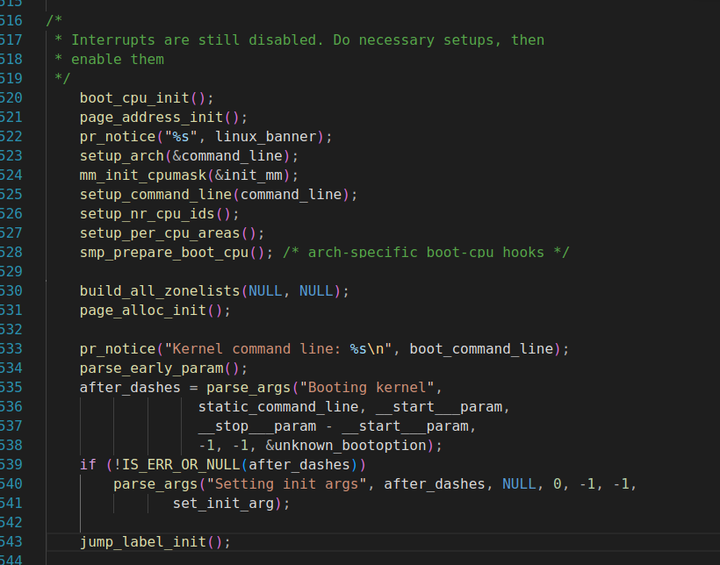
boot_cpu_init函数 boot_cpu_init函数是Linux内核初始化过程中用于启动第一个处理器(通常是引导CPU)的函数。该函数在内核启动的早期阶段被调用,其主要目的是将引导CPU标记为“存在”、“在线”等状态,以便后续的内核初始化和调度工作能够正确进行。 以下是关于boot_cpu_init函数的详细解释: 函数定义与位置
定义:boot_cpu_init函数通常在内核源码的init/main.c文件中定义。
位置:该函数在内核启动过程中被调用,具体位置在start_kernel函数中,负责初始化内核的早期阶段。
主要功能
获取当前CPU ID:通过调用smp_processor_id()函数获取当前执行的CPU ID。这个ID用于标识当前的CPU,以便后续的操作能够针对特定的CPU进行。
设置CPU状态:使用一系列的set_cpu_*函数(如set_cpu_online、set_cpu_active、set_cpu_present、set_cpu_possible)来设置当前CPU的状态。这些函数将当前CPU标记为“存在”、“在线”、“活动”和“可能”,以确保内核能够正确地管理和调度该CPU。
特定于SMP的配置:如果内核配置为对称多处理(SMP)模式,则还会设置一个特殊的全局变量__boot_cpu_id来保存引导CPU的ID。这对于后续在多核环境下的CPU管理和调度非常重要。
注意事项
调试与配置:在某些情况下,为了支持调试或特定的内核配置(如抢占式内核),可能需要对boot_cpu_init函数及其相关调用进行调整或增强。
架构差异:不同架构下的boot_cpu_init函数实现可能有所不同,因为获取CPU ID和设置CPU状态的具体方法可能因架构而异。
page_address_init函数 page_address_init函数是Linux内核在初始化过程中用于设置与页地址相关数据结构的一个重要函数。以下是对该函数的详细解释: 主要功能
初始化高端内存页表池:该函数会初始化一个全局的页表池,这个页表池用于存储和管理高端内存(即不能直接映射到内核地址空间的内存)的页表项。
关联页地址映射结构:函数将内存页地址映射表page_address_maps中的每一个页地址映射结构通过其list成员加入到页表池page_address_pool中,以便后续对这些映射结构进行管理和查找。
设置自旋锁:为确保对页表池和哈希桶的操作是线程安全的,函数会初始化相关的自旋锁,包括每个哈希桶的自旋锁以及保护整个页表池的全局自旋锁。
定义位置
page_address_init函数通常定义在内核源码的mm/highmem.c文件中。
代码逻辑
初始化页表池链表头:使用INIT_LIST_HEAD(&page_address_pool)宏来初始化页表池的链表头,使其前向指针和后继指针都指向自己,防止出现空指针引用。
添加页地址映射结构到页表池:通过循环遍历page_address_maps数组,使用list_add函数将每个页地址映射结构的list成员添加到页表池的链表中。
初始化哈希桶:对于page_address_htable数组中的每个元素,分别初始化其链表头和自旋锁。这确保了每个哈希桶都是空的,并且对其操作是线程安全的。
初始化全局自旋锁:最后,初始化用于保护整个页表池的全局自旋锁pool_lock,以确保对页表池的操作是原子性的。
总的来说,page_address_init函数在Linux内核初始化过程中扮演着至关重要的角色,它负责初始化与页地址相关的数据结构和锁机制,为后续的内存管理和调度提供了基础支持。
setup_arch函数等等后续函数 setup_arch函数是Linux内核初始化过程中的一个关键步骤,它负责根据特定的体系结构进行相关的设置和初始化工作。以下是对该函数的详细解释: 函数定义与位置
定义:setup_arch是一个特定于体系结构的函数,其具体实现取决于内核编译时指定的架构(如ARM、x86等)。因此,不同的架构可能有不同版本的setup_arch函数。
位置:该函数通常位于内核源码的arch/<architecture>/setup.c文件中,其中<architecture>代表具体的架构名称。
主要功能
处理器配置:
通过调用setup_processor()函数,根据检测到的处理器类型进行处理器内核的初始化。
机器描述结构体设置:
获取并设置机器描述结构体(machine_desc),该结构体包含了当前机器的硬件信息和配置选项。这通常通过调用setup_machine(machine_arch_type)或类似函数来完成。
根据machine_desc中的信息,进一步设置内存管理单元(MMU)、页表项等。
内存初始化:
初始化内存管理单元(MMU)和页表项,为后续的内存访问和管理做好准备。
根据系统定义的meminfo结构进行内存结构的初始化。
命令行参数解析:
解析由引导加载程序传递的命令行参数,这些参数可能包含关于内存配置、启动选项等重要信息。
将解析后的参数保存到相应的全局变量中,以便后续使用。
其他初始化任务:
根据需要执行其他与体系结构相关的初始化任务,如设置中断向量、初始化设备树节点等。
调用时机与重要性
setup_arch函数在Linux内核启动过程中被调用,通常在start_kernel函数之前或之中。它是内核初始化过程中不可或缺的一部分,对于确保内核能够正确地在特定硬件上运行至关重要。
注意事项
由于setup_arch函数是特定于体系结构的,因此在不同的架构下可能有不同的实现细节和依赖关系。在理解和修改该函数时,需要特别注意这一点。
在对setup_arch函数进行修改或扩展时,应确保不会破坏内核的稳定性和兼容性。建议在进行任何更改之前充分了解相关架构和内核版本的特点。
这部分接下来的几个函数就是依次进行进一步的内存管理初始化、boot传递的命令行参数解析、页地址处理等等。 具体实现自行查阅源码。
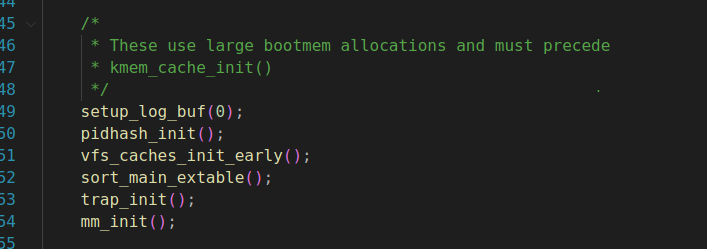
继续往后看
precede 处在…之前,先于
在Linux内核启动过程中,存在一些使用大块内存分配的操作,这些操作必须在kmem_cache_init()函数之前完成。以下是对这些操作及其原因的详细解释:
一、涉及的操作
日志缓冲区初始化
函数:setup_log_buf(0)
说明:该函数用于初始化日志缓冲区,它需要分配较大的内存块来存储日志信息,因此在kmem_cache_init()之前调用。
虚拟文件系统(VFS)缓存初始化
函数:vfs_caches_init_early()
说明:此函数负责初始化VFS相关的缓存结构,这通常需要分配一定量的内存来创建和管理缓存对象,所以也需要提前调用。
主引导表排序
函数:sort_main_extable()
说明:该函数用于对主引导表进行排序和整理,可能需要分配内存来处理表项数据,因此需要在kmem_cache_init()之前执行。
陷阱向量表初始化
函数:trap_init()
说明:陷阱向量表的初始化可能涉及到内存的分配和设置,以确保在中断处理和系统调用时能够正确地定位和处理相应的向量,所以也需要提前进行。
内存管理单元(MMU)初始化
函数:mm_init()
说明:虽然严格来说mm_init()并不直接等同于上述提到的特定操作,但它是内存管理单元的初始化过程,通常会涉及到大量内存的分配和管理结构的设置,为后续的内存管理操作(包括kmem_cache_init())奠定基础,因此也需要在早期进行。
二、原因分析
内存分配需求
这些操作在执行过程中需要分配较大的内存块,而kmem_cache_init()是用于初始化内核中的小内存块分配器。如果先执行kmem_cache_init(),可能会导致这些需要大块内存的操作无法正常获得足够的内存,从而引发错误或系统不稳定。
系统初始化顺序
在内核启动的早期阶段,系统需要尽快建立一些基本的数据结构和资源,以支持后续的初始化过程。这些使用大块内存的操作往往是构建这些基础设施的关键步骤,必须按照正确的顺序执行,确保系统能够正确启动和运行。
依赖关系
部分操作之间存在依赖关系,例如内存管理单元的初始化(mm_init())为其他操作提供了内存管理的基础,只有先完成内存管理的初始化,其他操作才能正确地进行内存分配和使用。
总的来说,这些在kmem_cache_init()之前进行的大块内存分配操作对于Linux内核的正确启动和稳定运行至关重要。它们遵循特定的顺序执行,以满足系统初始化的需求,并避免潜在的问题。
继续
sched_init函数 sched_init 函数是 Linux 内核启动过程中用于初始化调度器的关键函数。
以下是对该函数的详细解释:
定义与位置
定义:__init sched_init(void),其中 __init 表示该函数是一个初始化函数,只在内核启动时执行一次,在内核正常运行时不会被调用。
位置:该函数通常位于内核源码的 kernel/sched/core.c 文件中。
主要功能
运行队列初始化:
为每个 CPU 创建并初始化其对应的运行队列(runqueue)。运行队列是内核中组织和管理就绪进程(处于 Running 状态、准备在 CPU 上执行的进程)的数据结构。
例如,通过 cpu_rq(i) 获取系统第 i 号处理器的运行队列结构指针,然后对其进行一系列的初始化操作,包括初始化运行队列锁(spin_lock_init(&rq->lock))、设置活动优先级阵列结构指针和到期优先级阵列结构指针等。
调度类相关初始化:
初始化各种调度类的全局数据结构和参数。调度类是内核对不同类型任务调度策略的一种抽象,常见的调度类有 CFS(完全公平调度类)、RT(实时调度类)等。
比如,对于 RT 和 DL(Deadline,截止时间调度类)调度类,会初始化其全局默认的 CPU 带宽控制数据结构,以控制实时进程对 CPU 资源的使用,防止实时进程过度占用 CPU 导致普通 CFS 进程饥饿。
CFS 软中断注册:
注册 CFS 相关的软中断处理函数。CFS 调度算法需要通过软中断来实现一些定时任务,如负载均衡、时钟更新等。
调用时机与重要性
调用时机:sched_init 函数在内核启动的相对靠后阶段被调用,此时内存初始化已经完成,所以可以在该函数中安全地调用内存申请函数(如 kzmalloc 等)来分配所需的内存资源。
重要性:它是内核调度子系统初始化的核心部分,为后续的任务调度奠定了基础。如果该函数执行失败或初始化不正确,内核将无法正常进行任务调度,进而影响整个系统的运行性能和稳定性。
总的来说,sched_init 函数在 Linux 内核启动过程中扮演着至关重要的角色,它完成了调度器的各项关键初始化工作,确保内核能够有效地管理和分配 CPU 资源,实现多任务的并发执行和系统的稳定运行。
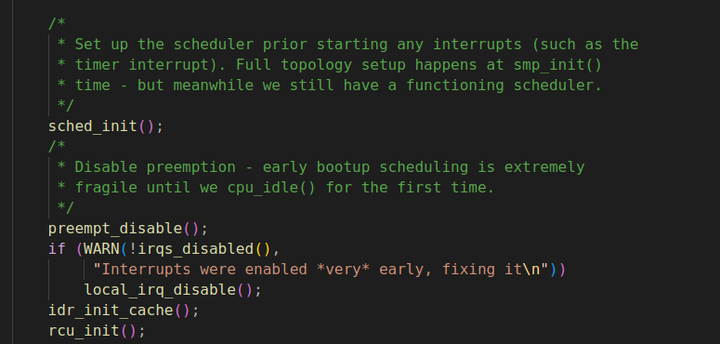
“Disable preemption - early bootup scheduling is extremely fragile until we cpu idle() for the first time.” 这句话的意思是“在早期启动阶段禁用抢占,调度非常脆弱,直到我们首次调用cpu_idle()函数。”以下是对这一表述的具体解释:
早期启动阶段的复杂性
硬件初始化未完成:在系统启动的最初阶段,硬件设备的初始化尚未完全完成。此时,系统的各个组件和设备可能还处于不稳定的状态,驱动程序可能还在加载和配置过程中。如果此时允许任务抢占,可能会因为硬件的不确定性导致任务执行出现异常,比如访问到未正确初始化的硬件资源,引发系统崩溃或数据错误。
数据结构不一致:内核在启动过程中会构建和初始化各种数据结构,如进程表、内存管理结构等。在这些数据结构完全建立和稳定之前,如果发生任务抢占,可能会导致正在被初始化的数据结构被破坏或处于不一致的状态。例如,一个任务正在修改进程表的某个字段,另一个任务在此时被调度运行并访问该字段,就可能得到错误的信息,进而影响系统的正常运行。
抢占机制的影响
任务切换的风险:抢占机制允许高优先级的任务中断低优先级任务的执行,以便及时响应重要的操作。但在早期启动阶段,任务之间的依赖关系较为复杂,随意的任务切换可能导致关键操作被中断,影响系统的启动流程。例如,一个低优先级的初始化任务可能正在为高优先级任务准备必要的资源,如果此时高优先级任务抢占执行,可能会因为资源未准备好而无法正常运行。
同步和互斥问题:在多任务环境下,任务之间需要通过同步和互斥机制来协调对共享资源的访问。在早期启动阶段,由于任务的启动顺序和执行时间的不确定性,同步和互斥机制可能难以正确建立和维护。如果允许抢占,可能会增加同步和互斥的错误概率,导致数据竞争、死锁等问题的出现。
cpu_idle()的作用
系统进入稳定状态的标志:cpu_idle()函数通常在系统的 CPU 初始化和基本硬件设备初始化完成后被调用,它表示 CPU 已经处于相对空闲的状态,不再有关键的硬件初始化操作需要立即执行。这意味着系统的硬件和软件环境已经相对稳定,可以安全地启用任务抢占机制。
调度器的准备工作完成:在调用cpu_idle()之前,内核的调度器已经完成了基本的设置和初始化工作,包括建立运行队列、设置调度参数等。此时,调度器已经具备了根据任务优先级和资源需求进行合理调度的能力,能够保证在启用抢占后,系统的任务调度能够有序进行,避免出现混乱的情况。
综上所述,在Linux内核的早期启动阶段禁用抢占是至关重要的,它确保了系统在硬件初始化、数据结构构建以及关键任务执行过程中的稳定性和一致性。只有当CPU首次调用cpu_idle()函数,表明系统已进入稳定状态时,才适合启用抢占机制,以确保系统能够高效、安全地运行。 在Linux内核中,
“Do the rest non-init'ed, we're now alive”这句话出现在start_kernel函数的末尾部分,用于调用rest_init函数。以下是关于它的详细解释:
位置与作用
位置:它位于start_kernel函数即将结束的位置,是内核初始化过程中的一个重要环节。
作用:标志着内核初始化阶段的基本完成,即将进入下一个阶段。在此之后,内核将启动第一个用户空间进程init(PID 1),以及内核线程kthreadd等,使系统进一步脱离内核初始化阶段,进入可正常运行的状态。
相关函数
start_kernel:这是内核启动过程中的一个关键函数,负责进行大量的内核子系统和基础设施的初始化工作,包括硬件初始化、内存管理初始化、调度器初始化、中断处理初始化等。当执行到“Do the rest non-init'ed, we're now alive”这行代码时,内核的核心初始化任务已接近尾声。
rest_init:该函数在“Do the rest non-init'ed, we're now alive”处被调用,其主要任务是启动第一个用户空间进程init和内核线程kthreadd,并进行一些其他的收尾工作,为系统的正常运行做好准备。例如,kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND)用于创建内核线程kernel_init,它是后续启动用户空间init进程的关键;而pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)则负责创建内核线程kthreadd,用于处理内核中的一些后台任务和管理空闲处理器等。
意义
系统状态转变:从内核初始化阶段向系统正常运行阶段的过渡。在此之前,内核主要在进行自身的设置和准备工作,而在这之后,系统将开始运行用户空间的应用程序和服务,真正为用户提供服务。例如,init进程会按照一定的顺序启动其他系统服务和程序,使系统逐渐进入到一个可用的状态。
多线程协作:体现了内核在启动过程中的多线程协作机制。rest_init函数中启动的kernel_init和kthreadd线程将与其他内核线程以及即将启动的用户空间进程一起协作,共同构建一个完整的操作系统运行环境。这种多线程协作的方式可以提高系统的并发性和效率,使得不同的任务能够同时进行,从而加快系统的启动速度和整体性能。
总之,“Do the rest non-init'ed, we're now alive”这句话在Linux内核启动过程中具有重要的标志意义,它表示内核已经基本完成了初始化工作,即将启动用户空间的第一个进程和相关内核线程,使系统进入一个更加活跃和可用的状态。 rest_init函数里面做了哪些事情? rest_init函数在Linux内核启动过程中扮演着至关重要的角色,它主要完成了以下几项关键任务:
启动核心进程
创建kernel_init进程(PID为1):通过调用kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);来实现。该进程是系统的第一个用户空间进程,后续会执行许多系统初始化和启动相关的工作,比如挂载根文件系统、启动其他必要的服务等,并且它会从内核态切换到用户态去执行相应的程序。
创建kthreadd进程(PID为2):使用pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);创建。kthreadd进程负责所有内核进程的调度和管理,确保内核进程能够正常运行和被合理分配CPU时间片等资源。
开启调度系统:在启动了上述两个重要进程后,通过schedule_preempt_disabled();打开抢占并调度,当调度回来再次执行的时候,关闭抢占,接着往下执行。这标志着Linux系统的调度系统开始正式运作,系统会根据各个进程的优先级和需求来分配CPU时间片,使多个进程可以并发执行,提高系统的运行效率和响应能力。
进入空闲进程状态:最后调用cpu_startup_entry(CPUHP_ONLINE);进入idle进程,其核心函数为cpu_idle_loop。当CPU没有其他任务需要处理时,就会执行idle进程,在该进程中会不断循环检查是否有新的任务需要调度,或者进行一些节能操作等。
总之,rest_init函数在Linux内核启动过程中起到了承上启下的关键作用,它完成了核心进程的创建、调度系统的开启以及进入空闲进程状态等重要操作,为Linux系统的正常运行奠定了坚实的基础。
Linux是什么时候创建idle进程的?
Linux在系统启动过程中创建idle进程,其时间点大致如下:
内核初始化阶段
在Linux内核的初始化过程中,当执行到start_kernel()函数时,会进行一系列的核心初始化工作,包括初始化页表、中断向量表、系统时间等。在这个过程中,会调用fork()函数创建第一个用户进程,也就是pid为1的init进程。而idle进程的创建与这个init进程的创建紧密相关。
具体来说,在创建了init进程之后,pid为0的原始进程(此时它已经接近完成内核态的任务)会调用cpu_idle()函数,从而演变成idle进程。所以,从时间顺序上讲,idle进程是在内核初始化阶段后期,随着init进程的创建而被创建出来的。
多处理器系统中的特殊情况
在对称多处理(SMP)系统中,除了主处理器上的idle进程由原始进程(pid=0)演变而来外,其他从处理器上的idle进程则是由init进程通过复制自身的方式创建。
当init进程在进行一些初始化工作时,比如执行smp_prepare_cpus()函数来初始化SMP处理器时,会在处理每个从处理器时调用特定的函数来复制一个进程,并将其初始化为idle进程(pid仍然为0)。
总的来说,Linux中idle进程的创建是系统启动过程中的一个重要环节,其创建时机和方式与内核初始化以及系统的处理器架构密切相关。 为什么idle进程比init进程后创建,反而进程号是0 在Linux系统中,idle进程的创建及其进程号(PID)为0的情况,涉及到系统初始化和进程管理的深层次机制。以下是对这一现象的解释:
idle进程的创建
内核初始化阶段生成:在内核初始化过程中,会进行一系列复杂的操作,包括硬件初始化、内存管理初始化、数据结构设置等。在这个过程中,系统会创建一个名为“init_task”的特殊任务结构体,它对应的就是0号进程,也就是最初的idle进程。
与处理器相关的创建:在多处理器系统(SMP)中,每个处理器单元都有独立的运行队列,而每个运行队列上都有一个idle进程。主处理器上的idle进程由原始进程(pid=0)演变而来,从处理器上的idle进程则是由init进程通过fork系统调用创建出来的,不过它们的pid都被设置为0。
idle进程的PID为0的原因
历史原因与约定俗成:在早期Unix系统的开发过程中,就已经有了0号进程的概念。当时的0号进程主要负责一些系统初始化和资源分配的工作。这种设计被保留了下来,并且在后续的发展中,Linux等类Unix操作系统继承了这一传统,将idle进程的PID设为0,以遵循这种历史约定和设计习惯。
特殊地位与系统需求:0号进程作为一个特殊的系统进程,具有独特的地位和作用。它是系统启动过程中最早创建的进程之一,承担着引导系统进入正常运行状态的重要任务。将其PID设为0,可以方便系统在后续的进程管理和调度中,快速识别和区分这个特殊的进程,便于进行资源的分配和管理。
总之,Linux中idle进程在系统启动时由内核创建,其PID为0是历史传承与系统设计需求共同作用的结果,体现了Linux系统对进程管理的独特方式和对系统资源的有效利用。
在Linux系统中,用户态的init进程是由内核启动的,它执行用户空间的程序来完成系统初始化和后续的一系列工作。
以下是关于init进程的用户态相关信息:
提供者
根文件系统:
init进程在内核态时会寻找并执行用户态下的init程序,这个用户态的init程序通常是由根文件系统提供的。
具体位置:
不同的Linux发行版可能会使用不同的init程序,常见的有/sbin/init、/etc/init、/bin/init等。如果这些路径下的init程序都不存在或执行失败,init进程还可能会尝试执行/bin/sh作为备用方案。
主要作用
启动其他服务:
init进程会根据配置文件(如/etc/inittab或/lib/systemd/system/default.target等)中的设置,启动各种系统服务和守护进程。这些服务包括网络服务、文件系统服务、设备管理服务等,它们都是系统正常运行所必需的。
管理系统运行级别:
传统的SysVinit通过读取/etc/inittab文件中的运行级别设置,来控制不同服务的启动和停止,以实现系统在不同运行级别下的切换。而Systemd则使用基于单元(unit)的依赖关系来管理系统的启动和运行状态,通过目标(target)来定义不同的运行级别。
处理信号与进程管理:
init进程负责接收和处理各种系统信号,如SIGTERM+4(Real-Time Signal)用于关闭系统,SIGINT用于进入紧急模式,SIGUSR1用于重新加载配置等。
同时,它还承担着孤儿进程的回收工作。在Linux系统中,当一个进程的父进程退出后,该进程会成为孤儿进程,此时init进程会收养这些孤儿进程。
构建用户交互界面:
init进程启动了login进程(用户登录进程)、命令行进程(提供命令行环境)、shell进程(提供命令解释和执行)等,这些进程共同构成了用户与系统的交互界面。用户可以通过命令行输入命令来执行各种应用程序,每个应用程序的运行都会创建一个对应的进程。
综上所述,用户态的init进程由根文件系统提供,它在Linux系统中扮演着至关重要的角色,负责启动和管理各种系统服务、处理信号和进程管理,以及构建用户交互界面,是系统启动和运行过程中不可或缺的核心进程。
在Linux系统中,启动脚本的位置取决于其类型和用途。以下是一些常见的启动脚本位置:
一、系统级别启动脚本
/etc/init.d/:传统的Linux发行版中,系统启动脚本通常存储在此目录中。这些脚本文件通常以init结尾,并且具有执行权限。
/etc/rc.d/init.d/:某些Linux发行版中,系统启动脚本可能存储在此目录中。这个目录包含了与系统启动、运行级别以及各种系统服务相关的脚本。
/etc/rc.local:这是一个特殊的脚本文件,它在系统引导过程中最后执行。用户可以在这个文件中添加需要在系统启动完成后立即执行的命令或脚本。
/etc/systemd/system/:在使用systemd作为init系统的Linux发行版中,启动脚本通常存储在此目录中。这些脚本定义了系统启动时要运行的服务和应用程序。
/usr/lib/systemd/system/:类似于/etc/systemd/system/目录,在某些Linux发行版中,也可以找到启动脚本文件。
二、用户级别启动脚本
~/.bashrc:每个用户的个人bash配置文件。当用户登录时,这个文件会被执行。用户可以将要在每次用户登录时执行的命令添加到这个文件中。
~/.bash_profile:类似于~/.bashrc,也是用户登录时执行的脚本文件之一。在某些情况下,它可能用于设置用户的环境变量或执行其他初始化任务。
~/.profile:另一个用户登录时执行的脚本文件。它通常用于设置用户的默认环境变量和路径等。
综上所述,了解Linux中启动脚本的位置对于管理和定制系统启动过程至关重要。无论是系统级别的服务启动还是用户级别的个性化配置,都可以通过编辑相应的启动脚本来实现。

















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









