







 GoogLeNet通过引入Inception模块和1x1卷积,以更少的参数和计算量实现了比AlexNet更深的网络,解决了深度网络的过拟合和计算效率问题。在2014年的ILSVRC比赛中取得冠军,其设计思路对后续深度学习网络产生了深远影响。
GoogLeNet通过引入Inception模块和1x1卷积,以更少的参数和计算量实现了比AlexNet更深的网络,解决了深度网络的过拟合和计算效率问题。在2014年的ILSVRC比赛中取得冠军,其设计思路对后续深度学习网络产生了深远影响。
GoogLeNet
1. Introduction
得益于深度学习的优势和更强大的卷积神经网络的出现,图像分类和目标检测的准确率发生了令人意想不到的进步。在2014年的ILSVRC比赛中,GoogLeNet取得了第一名的成绩,所用模型参数不足AlexNet(2012年冠军)的1/12。论文题目《Going deeper with convolutions》中的deeper有两层含义,一是指本文引入了一种新的结构“Inception module”,二就是其直接含义——网络深度(depth)的增加。
2. Relative work
相比传统的网络架构设计——由多个卷积层堆积,选择性的使用Normalization和maxpool,然后经过一层或多层的全连接层输出,由于模型参数主要集中在全连接层,可选择在全连接层使用dropout来降低过拟合的风险。
但是Maxpool可能会导致空间信息的损失,降低神经网络的表现力。为了解决这个问题,Lin等人在2013年提出了inception——“Network in Network”的想法。在卷积网络中的实现方法就是添加一个额外的1X1卷积层,使用Relu作为激活函数。其主要作用是降维(dimension reduction),在不牺牲模型表现的前提下,可以大量减少计算量,有利用训练更深更广的网络。
前沿的目标检测方法是R-CNN,主要思想是将目标检测问题划分为两个子问题:首先利用低级的特征比如颜色和超像素的一致性来得到潜在的object proposals。然后利用CNN分类器对这些位置上的proposals进行分类识别。GoogLeNet对这两步分别进行了优化,取得了令人惊喜的结果。
3. Motivation
通常来说要想提高网络性能,常用的方法就是提高神经网络层数和宽度,但是会带来两个严重的缺陷:一是更深的网络意味着会有更多的参数,这样很容易导致过拟合;二是更深的网络会带来更多计算上的开支,减缓训练周期。而参数又主要集中在全连接层,于是就想到了用稀疏连接来取代全连接层的方法,是解决这两个问题的关键。
在《Provable bounds for learning some deep representations》中提到**“如果用大而稀疏的CNN来表示数据集的概率分布,那么可以通过逐层分析最后一层的Activation和具有高度相关的输出的聚类神经的相关统计数据来构建最优的网络拓补结构。”**,尽管没有严格的数学证明,但是这很符合Hebbian principle的说法,这为网络架构的设计提供了有力的理论保障!
4. Inception Module
Inception的主要观点是弄明白卷积视觉网络中的一个局部最优稀疏结构是如何被一个可轻易获取的密集结构去逼近和覆盖的。
Inception model 的结构如下;左边是初期版本,这里使用三个不同的patch size,1X1 3X3 5X5,主要是为了避免patch alignment问题和减少计算量。比如对三个patch分别使用padding=0,1,2进行卷积就可以让卷积后的输出具有相同的尺寸,而patch size较小的时候对应的参数相应也小一些,比如1x1=1,3x3=9,5x5=25,再往后参数数量的增长速度就更快了。由于池化层在卷积神经网络中的作用往往都是起关键作用的,所以Inception model里也加入了一个池化层。但这种设计不是必须的,只是为了更方便。
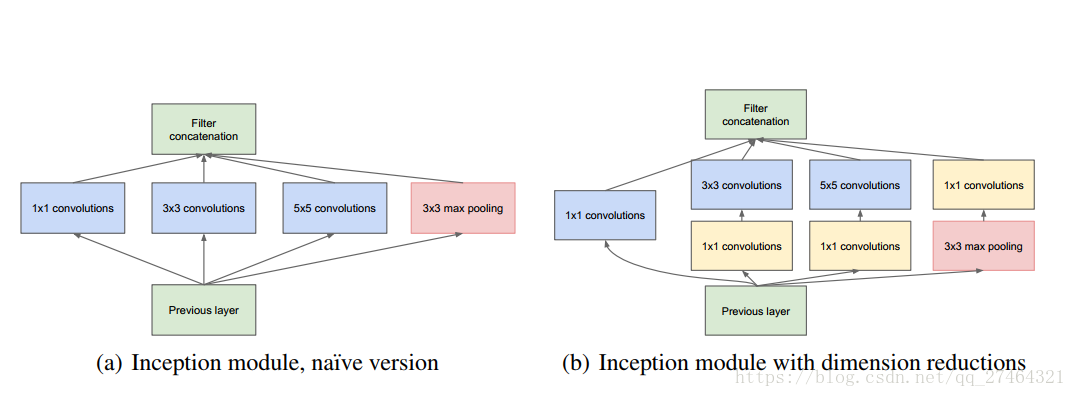
但是初级的版本有个很大的缺点就是参数量和计算量会很大,而且将三个卷积层和一个池化层的输出拼接后的feature map数量会变得很大,随着网络层数的增加,模型会变得很复杂,变得难以训练。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×321×1×192×64+3×3×192×128+5×5×192×321×1×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









