







 特征工程是机器学习的关键步骤,包括特征归一化、类别型特征处理和特征选择。特征归一化如Min-Max Scaling和Z-Score Normalization有助于优化模型训练。类别型特征可通过序号编码、one-hot编码或二进制编码处理。特征选择涉及过滤型、包裹型和嵌入型方法,用于减少冗余并提高模型性能。
特征工程是机器学习的关键步骤,包括特征归一化、类别型特征处理和特征选择。特征归一化如Min-Max Scaling和Z-Score Normalization有助于优化模型训练。类别型特征可通过序号编码、one-hot编码或二进制编码处理。特征选择涉及过滤型、包裹型和嵌入型方法,用于减少冗余并提高模型性能。
特征工程
特征工程就是将原始数据进行一系列工程处理,去掉原始数据的冗余和错误,为模型提供对求解问题更高效的特征输入。输入数据分为
1.结构化数据:结构化数据可以看作关系型数据库的一张表,每列都有清晰的定义,包含了数值型和类别型两类。每一行(或每一列)代表一个样本的各个特征的信息。
2.非结构化数据:非结构数据主要包括本文、音频、视频、图像等。它们的特点是其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
特征归一化
首先为什么我们要进行特征归一化呢?
θ1的取值范围是[0,3],θ2的取值范围是[0,10],如下图左边。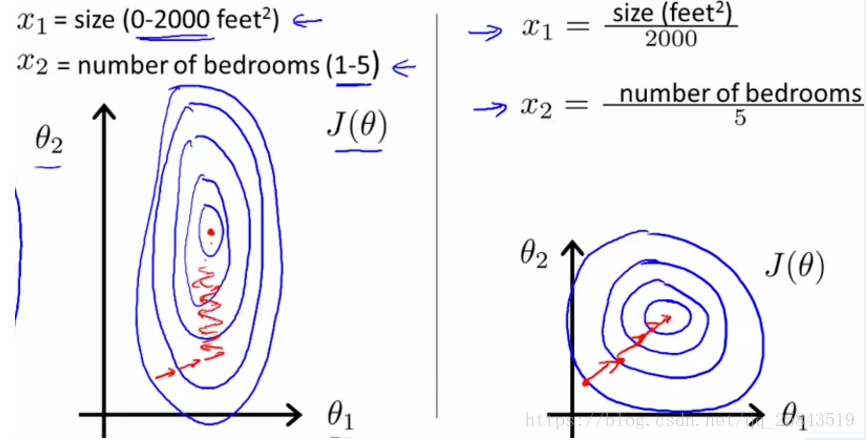
在学习速率相同的情况下,在学习速率相同的情况下,θ1的更新速度要比θ2慢,需要更多的迭代才能找到最优解。如果将θ1和θ2归一化到相同的数值区间,优化目标的等值图就会变成圆形,x1和x2的更新速度变得更为一致,容易更快地通过梯度下降找到最优值。
在实际应用中,哪些情况需要数据归一化?
通过梯度下降求解的模型通常焊死需要归一化的,例如线性回归、逻辑回归、支持向量机、神经网络模型等。例如决策树是不需要归一化的。
最常用的归一化方法
1.线性函数归一化(Min-Max Scaling)
x n o r m = X − X m i n X m a x − X m i n x_{norm} = {X-X_{min}\over X_{max}-X_{min}} xnorm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









