




 探讨深度神经网络中抽象能力的重要性,分析传统CNN的局限性,并介绍如何通过使用更复杂的MLP模块和NIN结构增强模型的辨别力,提高抽象能力,减少过拟合风险。
探讨深度神经网络中抽象能力的重要性,分析传统CNN的局限性,并介绍如何通过使用更复杂的MLP模块和NIN结构增强模型的辨别力,提高抽象能力,减少过拟合风险。
在神经网络中,虽然面临着训练时间、训练难易程度的问题,但是既然更深的网络总能获得更好的效果,就不可避免深度这个问题。
无论各种架构的 CNN 中创造性的提出了什么结构模块,深度都是必要条件。那么越深也就意味着能学到更多或者更好的学习到潜在特征。
motivation
在局部感受野中,用更复杂的 mlp增强模型的辨别力,提高抽象能力。mlp 由多层感知器组成,本身具有更强的函数逼近器的效果。因为在每一层都通过 mlp增强了局部的建模能力,在分类器前一层就可以用 global average pooling 而不需要使用 fully connected 层,这样更不容易过拟合。

抽象能力:文中认为,传统 CNN 对于输入的抽象能力是比较低的,即使对于相同概念的变体,它所对应的特征也应该是不变的。
The convolution filter in CNN is a generalized linear model (GLM) for the underlying data patch, and we argue that the level of abstraction is low with GLM. By abstraction we mean that the feature is invariant to the variants of the same concept [2].
传统的 CNN 是将data patch与卷积核 filter 做内积,再送入激活函数中进行非线性转换。但作者认为这样对data patch的抽象程度是比较低的。而且表示相同的概念(比如鼻子)的data patch不相同的时候,其与卷积核 filter 做内积也会不同,但应该保持不变。此时传统CNN 的 GLM 可能就把同一个概念的不同变体都学到了,这对后面的层是有压力的。
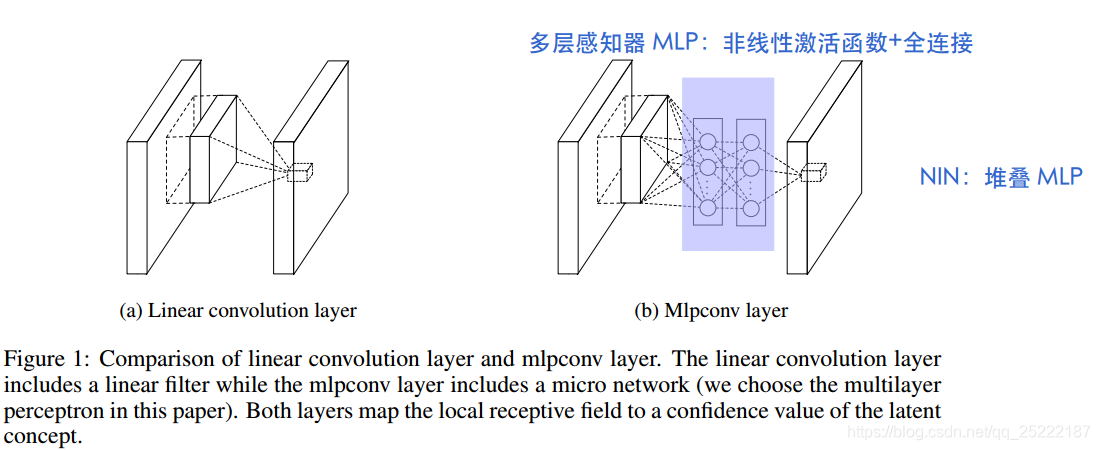
全连接层很容易过拟合,非常依赖 dropout。
本文最后一层使用 global average pooling,这样迫使网络学习 feature map 和类别之间的关系,在直觉上建立 feature map 和类别之间更强的关系。
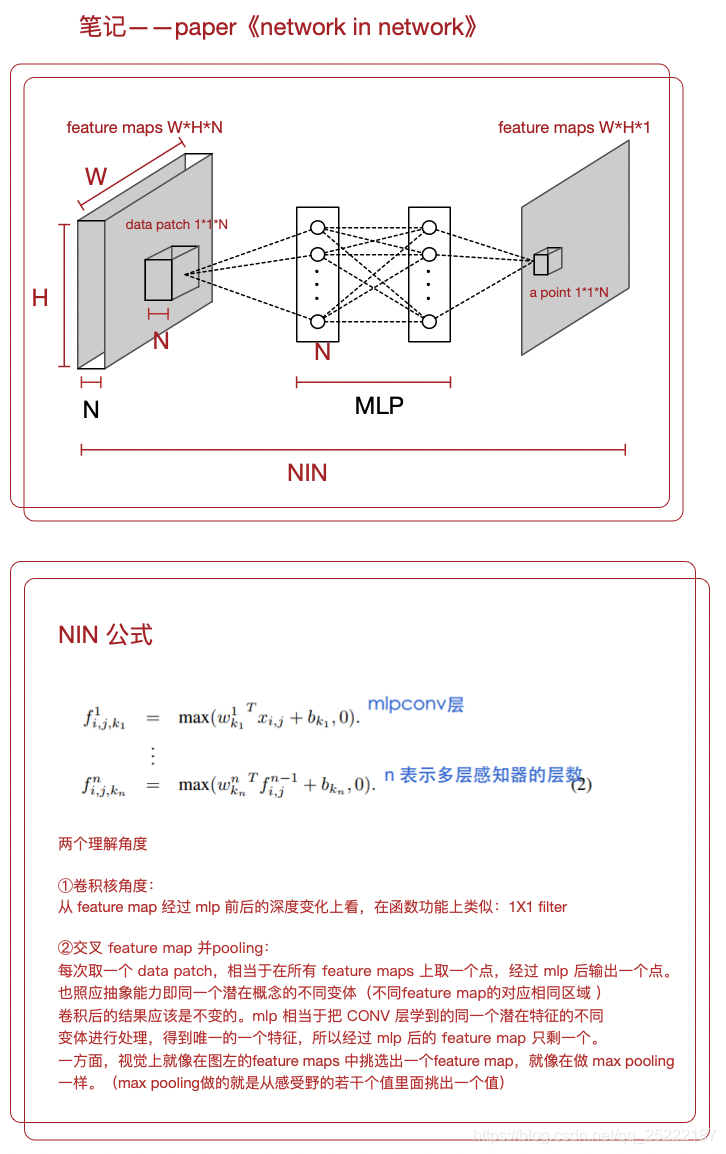
mlpconv 层的计算如下

针对核心公式(2),作者提出了理解NIN的两个角度:
1.交叉feature map 进行 pooling 的角度理解

个人理解:这个 cascaded cross channel parameteric pooling structure 相当于对卷积后得到的通道做交叉并进行 max pooling。因为卷积核本身和 input 的深度是相同的,卷积后的值就是 input 的局部data patch的线性组合(卷积的作用),所以卷积后的值包含 input 各通道(feature map )信息,mlp 此时将卷积后的结果进行 max pooling。
mlp 的输入的个数就是 feature maps 的深度,这样每次输入mlp 的size 为feature maps的一个1x1x(feature map depth),这相当于对 feature map 进行在深度维度进行交叉并进行 max pooling,这样对于 input 的潜在概念,一个NIN已经对feature map进行了充分的非线性化,因此抽象能力更好。
2. This cascaded cross channel parameteric pooling structure也相当于一个1x1的卷积层。
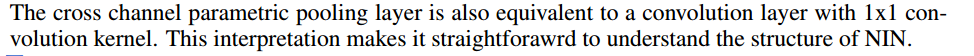
根据个人理解,画了一个图,刚开始用 omnigraffle,画图虐死我了!
与 maxout layer进行对比
maxout layer有先验知识:潜在概念都是凸的,能拟合任意凸函数。但 NIN 没有先验,能拟合任意函数。

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









