







 介绍R-FCN(区域全卷积网络),一种改进的目标检测网络,通过位置敏感的scoremaps提高检测精度。R-FCN将目标分为k×k网格,每个网格对应featuremap上的特定channel,实现位置敏感的特征提取,适用于目标分类和定位。
介绍R-FCN(区域全卷积网络),一种改进的目标检测网络,通过位置敏感的scoremaps提高检测精度。R-FCN将目标分为k×k网格,每个网格对应featuremap上的特定channel,实现位置敏感的特征提取,适用于目标分类和定位。
Introduction
目标检测网络的backbone一般是分类网络,用网络的最后一层feature map的特征进行对目标的分类和定位。分类网络的高层feature map包含的是高层语义信息,具有平移不变性。平移不变性有助于分类任务,但是会影响目标定位,目标定位需要位置敏感的特征信息。平移不变性和平移变性这个两个矛盾的需求限制了目标检测网络的精度。作者实现了一个基于区域的全卷积网络R-FCN,提出了位置敏感的scroe map。作者的做法就是把目标各个部分的位置信息映射到feature map的不同channels上,每个channel只包含一个部分的位置信息。相当于把每个region区域分成几个区域,每个区域的信息由一个channel表示。
R-FCN
Position-sensitive score maps
R-FCN结构如下
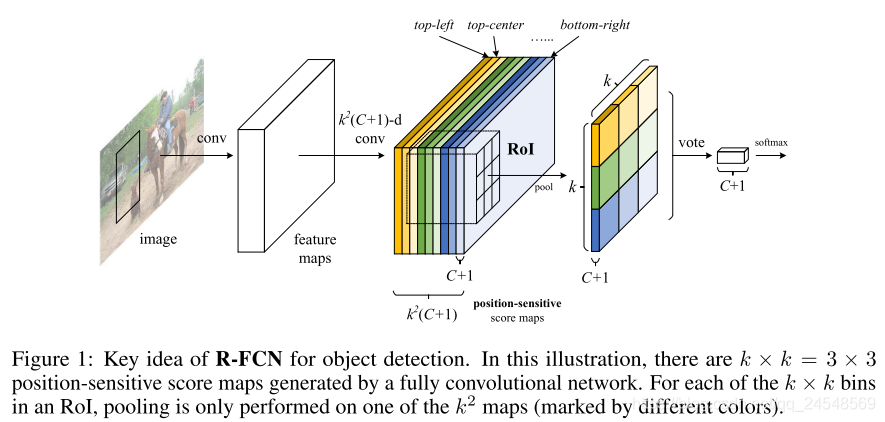
最后一层feature map之前的网络结构和R-CNN一样。最后一层的feature map的通道数大小是k2(C+1)k^2(C+1)k2(C+1)。RoI pooling会把region proposal分成k×kk\times kk×k的网格。在R-FCN中,每个网格上的信息对应feature map上的特定channel。如图,左上角的网格(黄色区域)只包含feature map上黄色channel的信息。C+1C+1C+1表示C个类别和1个背景类。这样,一个region上k×kk \times kk×k个网格位置对应不同的channels,每个channel是位置敏感的scroe map。
Position-sensitive RoI pooling
这里的RoI pooling变成了Position-sensitive RoI pooling。每个k×kk \times kk×k网格的信息会从对应的channel上的对应的位置提取(average pooling),得到k×k×(C+1)k \times k \times (C+1)k×k×(C+1)的scores。对于每个类别的scores,进行vote(average),得到最终的类别分数,最后得到C+1C+1C+1个分数,通过softmax层进行分类。所以说,R-FCN没有全连接层,是全卷积网络。
bbox回归的分支和分类分支一样,只是Position-sensitive score maps的通道数变成了4k24k^24k2,4表示bbox的4个数字,这里是类别无关,也可以设计成类别相关(4k2C4k^2C4k2C个channels)。
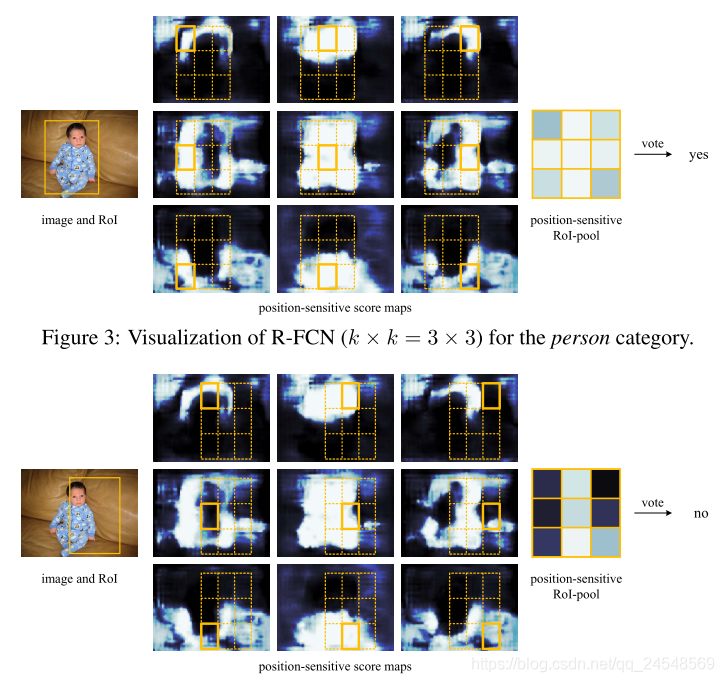
Position-sensitive RoI pooling和vote的过程如下图所示
Conclusion
该论文把目标分成k×kk \times kk×k个网格的组成部分,然后分别检测每个部分,当所有组成部分的响应都很高时,说明就是该目标。对于bbox的回归预测,我猜想是这样的,每个组成部分的信息都预测一个整体的bbox,然后综合所有的预测出来的bbox(最后的4k24k^24k2向量通过average vote变成444向量)。如果每个部分只预测该部分的bbox,最后把各个部分的bbox组合起来,推出整个目标的bbox,这样会不会效果更好。
作者把目标的整体分成部分,通过部分来预测整体。同时实现了目标检测网络的全卷积化。让我认为这是这篇论文的主要贡献。
作者的设计,其实就是把原来R-CNN的最后一层feature map的作用移到前一层,把分类和回归的head变成score maps。对目标检测网络的改进操作就是通过部分来预测整体,通过整体的各个部分的信息推理出整体。
作者把目标分成k×kk \times kk×k个网格部分,这样划分会不会太“死板”,目标可能会各种姿态形状,固定好的划分不能很好地匹配视觉上的目标的各个部分。

















 5147
5147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









