









 本文详细介绍了Java中的ThreadLocal机制,包括其作用、基本用法和应用场景。接着讨论了多线程共享数据的两种方式,并深入讲解了Java并发库中的ExecutorService、ThreadPoolExecutor、ScheduledThreadPoolExecutor等线程池的使用,以及阻塞队列BlockingQueue的各种实现。文章旨在帮助读者理解并掌握Java并发编程的核心概念和工具。
本文详细介绍了Java中的ThreadLocal机制,包括其作用、基本用法和应用场景。接着讨论了多线程共享数据的两种方式,并深入讲解了Java并发库中的ExecutorService、ThreadPoolExecutor、ScheduledThreadPoolExecutor等线程池的使用,以及阻塞队列BlockingQueue的各种实现。文章旨在帮助读者理解并掌握Java并发编程的核心概念和工具。
目录
- 0. ThreadLocal介绍(可实现线程间数据共享,但是数据独立分开消耗共享)
- 1. ThreadLocal的基本用法
- 2. ThreadLocal 的应用场景
- 3 多线程共享数据
- 4. Java 的线程并发库介绍
- 5. 必须要看
0. ThreadLocal介绍(可实现线程间数据共享,但是数据独立分开消耗共享)
- ThreadLocal 的作用和目的:用于实现线程内的数据共享,即对于相同的程序代码,多个模块在同一个线程中运行时要共享一份数据,而在另外线程中运行时又共享另外一份数据。
- 每个线程调用全局 ThreadLocal 对象的 set 方法,在 set 方法中,首先根据当前线程获取当前线程的
ThreadLocalMap 对象,然后往这个 map 中插入一条记录,key 其实是 ThreadLocal 对象,value 是各自的 set
方法传进去的值。也就是每个线程其实都有一份自己独享的 ThreadLocalMap对象,该对象的 Key 是 ThreadLocal
对象,值是用户设置的具体值。在线程结束时可以调用 ThreadLocal.remove()方法,这样会更快释放内存,不调
用也可以,因为线程结束后也可以自动释放相关的 ThreadLocal 变量。
1. ThreadLocal的基本用法
https://blog.youkuaiyun.com/qq_36259539/article/details/117582433
1.1 补充使用说明
1.1.1 方式一
在关联数据类中创建 private static ThreadLocal
在下面的类中,私有静态 ThreadLocal 实例(serialNum)为调用该类的静态 SerialNum.get() 方法的每个线程维护了一个“序列号”,该方法将返回当前线程的序列号。(线程的序列号是在第一次调用SerialNum.get() 时分配的,并在后续调用中不会更改。)
public class SerialNum {
// The next serial number to be assigned
private static int nextSerialNum = 0;
private static ThreadLocal serialNum = new ThreadLocal() {
protected synchronized Object initialValue() {
return new Integer(nextSerialNum++);
}
};
public static int get() {
return ((Integer) (serialNum.get())).intValue();
}
}
1.1.2 方式二
public class ThreadContext {
private String userId;
private Long transactionId;
private static ThreadLocal threadLocal = new ThreadLocal(){
@Override
protected ThreadContext initialValue() {
return new ThreadContext();
}
};
public static ThreadContext get() {
return threadLocal.get();
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public Long getTransactionId() {
return transactionId;
}
public void setTransactionId(Long transactionId) {
this.transactionId = transactionId;
}
}
1.1.3 方式三: Utils工具类
public class ThreadLocalUtil {
private static Log log = LogFactory.getLog(ThreadLocalUtil .class);
private static final SessionFactory sessionFactory; //定义 SessionFactory
static {
try {
// 通过默认配置文件 hibernate.cfg.xml 创建 SessionFactory
sessionFactory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
log.error("初始化 SessionFactory 失败!", ex);
throw new ExceptionInInitializerError(ex);
}
}
//创建线程局部变量 session,用来保存 Hibernate 的 Session
public static final ThreadLocal session = new ThreadLocal();
/**
* 获取当前线程中的 Session
* @return Session
* @throws HibernateException
*/
public static Session currentSession() throws HibernateException {
Session s = (Session) session.get();
// 如果 Session 还没有打开,则新开一个 Session
if (s == null) {
s = sessionFactory.openSession();
session.set(s); //将新开的 Session 保存到线程局部变量中
}
return s;
}
public static void closeSession() throws HibernateException {
//获取线程局部变量,并强制转换为 Session 类型
Session s = (Session) session.get();
session.set(null);
if (s != null)
s.close();
}
}
}
1.1.4 方式四 在Runnable 中创建 ThreadLocal
在线程类内部创建 ThreadLocal,基本步骤如下:
①、在多线程的类(如 ThreadLocalTest 类)中,创建一个 ThreadLocal 对象 studenThreadLocal,用来保存线程间需要隔离处理的对象 Studen。
②、在 ThreadLocalTest 类中,创建一个获取要隔离访问的数据的方法 getStudent(),在方法中判断,若ThreadLocal 对象为 null 时候,应该 new()一个隔离访问类型的对象,并强制转换为要应用的类型
③、在 ThreadLocalTest 类的 run()方法中,通过调用 getStudent()方法获取要操作的数据,这样可以保证每个线程对应一个数据对象,在任何时刻都操作的是这个对象。
public class ThreadLocalTest implements Runnable {
ThreadLocal<Studen> studenThreadLocal = new ThreadLocal<Studen>();
@Override
public void run() {
String currentThreadName = Thread.currentThread().getName();
System.out.println(currentThreadName + " is running...");
Random random = new Random();
int age = random.nextInt(100);
System.out.println(currentThreadName + " is set age: " + age);
Studen studen = getStudent(); //通过这个方法,为每个线程都独立的 new 一个 student 对象,每个线程的的
// student 对象都可以设置不同的值
studen.setAge(age);
System.out.println(currentThreadName + " is first get age: " + studen.getAge());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(currentThreadName + " is second get age: " + studen.getAge());
}
private Studen getStudent() {
Studen studen = studenThreadLocal.get();
if (null == studen) {
studen = new Studen();
studenThreadLocal.set(studen);
}
return studen;
}
public static void main(String[] args) {
ThreadLocalTest t = new ThreadLocalTest();
Thread t1 = new Thread(t, "Thread A");
Thread t2 = new Thread(t, "Thread B");
t1.start();
t2.start();
}
}
class Studen {
int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
2. ThreadLocal 的应用场景
- 订单处理包含一系列操作:减少库存量、增加一条流水台账、修改总账,这几个操作要在同一个
事务中完成,通常也即同一个线程中进行处理,如果累加公司应收款的操作失败了,则应该把前面
的操作回滚,否则,提交所有操作,这要求这些操作使用相同的数据库连接对象,而这些操作的代码
分别位于不同的模块类中。 - 银行转账包含一系列操作: 把转出帐户的余额减少,把转入帐户的余额增加,这两个操作要在
同一个事务中完成,它们必须使用相同的数据库连接对象,转入和转出操作的代码分别是两个不同
的帐户对象的方法。 - 例如 Strut2 的 ActionContext,同一段代码被不同的线程调用运行时,该代码操作的数据是每
个线程各自的状态和数据,对于不同的线程来说,getContext 方法拿到的对象都不相同,对同一个
线程来说,不管调用 getContext 方法多少次和在哪个模块中 getContext 方法,拿到的都是同一
个。
3 多线程共享数据
在 Java 传统线程机制中的共享数据方式,大致可以简单分两种情况:
➢ 多个线程行为一致,共同操作一个数据源。也就是每个线程执行的代码相同,可以使用同一个 Runnable 对
象,这个 Runnable 对象中有那个共享数据,例如,卖票系统就可以这么做。
➢ 多个线程行为不一致,共同操作一个数据源。也就是每个线程执行的代码不同,这时候需要用不同的
Runnable 对象。例如,银行存取款。
下面我们通过两个示例代码来分别说明这两种方式。
3.1 多个线程行为一致共同操作一个数据
如果每个线程执行的代码相同,可以使用同一个 Runnable 对象,这个 Runnable 对象中有那个共享数据,例如,买票系统就可以这么做。
public class ThreadShareOneDataTest {
/**
*测试方法
**/
public static void main(String[] args) {
ShareData shareData = new ShareData();
for (int i = 0; i < 4; i++) {
new Thread(new RunnableCusToInc(shareData),"Thread "+ i).start();
}
}
}
//共享数据类
class ShareData{
private int num = 10 ;
public synchronized void inc() {
num++;
System.out.println(Thread.currentThread().getName()+": invoke inc method num =" + num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
*多线程类
**/
class RunnableCusToInc implements Runnable{
private ShareData shareData;
public RunnableCusToInc(ShareData data) {
this.shareData = data;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
shareData.inc();
}
}
}
3.2 多个线程行为不一致共同操作一个数据
如果每个线程执行的代码不同,这时候需要用不同的 Runnable 对象,有如下两种方式来实现这些 Runnable 对象之间的数据共享:
-
- 将共享数据封装在另外一个对象中,然后将这个对象逐一传递给各个 Runnable 对象。每个线程对共享数据的操作方法也分配到那个对象身上去完成,这样容易实现针对该数据进行的各个操作的互斥和通信。
代码如下:
- 将共享数据封装在另外一个对象中,然后将这个对象逐一传递给各个 Runnable 对象。每个线程对共享数据的操作方法也分配到那个对象身上去完成,这样容易实现针对该数据进行的各个操作的互斥和通信。
public class ThreadDiffShareOneDataTest {
public static void main(String[] args) {
ShareData2 shareData = new ShareData2();
//线程执行多少次, 每个线程执行2次, 每个线程方法 循环对共享变量操作5次,增加或者减少
for (int i = 0; i < 4; i++) {
if (i % 2 == 0) {
new Thread(new RunnableCusToInc2(shareData), "Thread " + i).start();
} else {
new Thread(new RunnableCusToDec(shareData), "Thread " + i).start();
}
}
}
}
//封装共享数据类
class RunnableCusToInc2 implements Runnable {
//封装共享数据
private final ShareData2 shareData;
public RunnableCusToInc2(ShareData2 data) {
this.shareData = data;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
shareData.inc();
}
}
}
//封装共享数据类
class RunnableCusToDec implements Runnable {
//封装共享数据 共同用的 ShareData2 共享数据对象设置为不可变, 共享了同一个数据
private final ShareData2 shareData2;
public RunnableCusToDec(ShareData2 data) {
this.shareData2 = data;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
shareData2.dec();
}
}
}
/**
* 共享数据类
**/
class ShareData2 {
private int num = 10;
public synchronized void inc() {
num++;
System.out.println(Thread.currentThread().getName() + ": invoke inc method num =" + num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void dec() {
num--;
System.out.println(Thread.currentThread().getName() + ": invoke inc method num =" + num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 将这些 Runnable 对象作为某一个类中的内部类,共享数据作为这个外部类中的成员变量,每个线程对共享数据的操作方法也分配给外部类,以便实现对共享数据进行的各个操作的互斥和通信,作为内部类的各个Runnable 对象调用外部类的这些方法。
代码如下:
public class ThreadDiffShareOneDataTest2 {
public static void main(String[] args) {
//公共数据
final ShareData3 shareData = new ShareData3();
for(int j = 0;j < 4;j++){
if (j % 2 == 0) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
shareData.inc();
}
}
}, "Thread " + j).start();
} else {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
shareData.dec();
}
}
}, "Thread " + j).start();
}
}
}
}
/**
* 共享数据类
**/
class ShareData3{
private int num = 10;
public synchronized void inc() {
num++;
System.out.println(Thread.currentThread().getName() + ": invoke inc method num =" + num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void dec() {
num--;
System.out.println(Thread.currentThread().getName() + ": invoke inc method num =" + num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
3.3 线程间异步共享消耗使用同一资源的总结
补充:上面两种方式的组合:将共享数据封装在另外一个对象中,每个线程对共享数据的操作方法也分配到那个对象身上去完成,对象作为这个外部类中的成员变量或方法中的局部变量,每个线程的 Runnable 对象作为外部类中的成员内部类或局部内部类。
总之,要同步互斥的几段代码最好是分别放在几个独立的方法中,这些方法再放在同一个类中,这样比较容易实现它们之间的同步互斥和通信。
4. Java 的线程并发库介绍
4.1 java.util.concurrent 包
A 执行程序
4.1.1 Executors线程池工厂
(多线程并发库)
-
java.util.concurrent 包含许多线程安全、测试良好、高性能的并发构建块。不客气地说,创建java.util.concurrent 的目的就是要实现 Collection 框架对数据结构所执行的并发操作。通过提供一组可靠的、高性能并发构建块,开发人员可以提高并发类的线程安全、可伸缩性、性能、可读性和可靠性,后面、我们会做介绍。
-
如果一些类名看起来相似,可能是因为 java.util.concurrent 中的许多概念源自 Doug Lea 的util.concurrent 库。
-
在并发编程中很常用的实用工具类。此包包括了几个小的、已标准化的可扩展框架,以及一些提供有用功能的类。此包下有一些组件,其中包括:
- 执行程序(线程池)
- 并发队列
- 同步器
- 并发 Collocation
A: 执行程序Executors 线程池工厂类
- Executors 线程池工厂类
作用:线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程 排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程 池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
为什么要用线程池:
- 减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务
- 可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为因为消耗过多的内存,而把服务器累趴下(每个线程需要大约 1MB 内存,线程开的越多,消耗的内存也就越大,最后死机)
Executors 详解: Java 里面线程池的顶级接口是 Executor,但是严格意义上讲 Executor并不是一个线程池,而只是一个 执行线程的工具。真正的线程池接口是 ExecutorService。ThreadPoolExecutor 是 Executors 类的底层实 现。我们先介绍下 Executors。线程池的基本思想还是一种对象池的思想,开辟一块内存空间,里面存放了众多(未死亡)的线程,池中线程执行调度由池管理器来处理。当有线程任务时,从池中取一个,执行完成后线程对象归池,这样可以避免反复创建线程对象所带来的性能开销,节省了系统的资源。
三种创建方式:
//创建固定大小的线程池
ExecutorService fPool = Executors.newFixedThreadPool(3);
//创建缓存大小的线程池
ExecutorService cPool = Executors.newCachedThreadPool();
//创建单一的线程池
ExecutorService sPool = Executors.newSingleThreadExecutor();
下面我们通过简单示例来分别说明:
4.1.1.1 固定大小连接池
/**
* 从下面的运行来看,我们 Thread 类都是在线程池中运行的,线程池在执行 execute 方法来执行 Thread 类中的 run 方法。不管 execute 执行几次,线程池始终都会使用 2 个线程来处理。不会再去创建出其他线程来处理
* run 方法执行。这就是固定大小线程池。
*/
public class PoolTest {
public static void main(String[] args) {
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);
//创建实现了 Runnable 接口对象,Thread 对象当然也实现了 Runnable 接口
Thread t1 = new MyThread();
Thread t2 = new MyThread();
Thread t3 = new MyThread();
Thread t4 = new MyThread();
Thread t5 = new MyThread();
//将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
//关闭线程池
pool.shutdown();
}
}
class MyThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"正在执行。。。");
}
}
运行结果:
pool-1-thread-2正在执行。。。
pool-1-thread-2正在执行。。。
pool-1-thread-2正在执行。。。
pool-1-thread-2正在执行。。。
pool-1-thread-1正在执行。。。
4.1.1.2 单任务连接池
单任务线程池在执行 execute 方法来执行 Thread 类中的 run 方法。不管 execute 执行几次,线程池始终都会使用单个线程来处理
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);
改为: //创建一个使用单个 worker 线程的
Executor,以无界队列方式来运行该线程。 ExecutorService pool =
Executors.newSingleThreadExecutor();
运行结果:
pool-1-thread-1正在执行。。。
pool-1-thread-1正在执行。。。
pool-1-thread-1正在执行。。。
pool-1-thread-1正在执行。。。
pool-1-thread-1正在执行。。。
补充:
在 java 的多线程中,一但线程关闭,就会成为死线程。关闭后死线程就没有办法在启动了。再次启动就会出现异常信息:Exception in thread “main” java.lang.IllegalThreadStateException。那么如何解决这个问题呢?
我们这里就可以使用 Executors.newSingleThreadExecutor()来再次启动一个线程。
4.1.1.3 可变连接池
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);
改为:
//创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该线程。
ExecutorService pool = Executors.newCachedThreadPool();
运行结果:
pool-1-thread-1正在执行。。。
pool-1-thread-4正在执行。。。
pool-1-thread-5正在执行。。。
pool-1-thread-2正在执行。。。
pool-1-thread-3正在执行。。。
运行结果看出,可变任务线程池在执行 execute 方法来执行 Thread 类中的 run 方法。这里 execute 执行多次,线程池就会创建出多个线程来处理 Thread 类中 run 方法。所有我们看到连接池会根据执行的情况,在程序运行时创建多个线程来处理,这里就是可变连接池的特点。
4.1.1.4. 延迟连接池(定时延后执行线程)
代码如下:
public class DelayPoolTest {
public static void main(String[] args) {
//创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
//创建实现了 Runnable 接口对象,Thread 对象当然也实现了 Runnable 接口
Thread t1 = new MyThread2();
Thread t2 = new MyThread2();
Thread t3 = new MyThread2();
Thread t4 = new MyThread2();
Thread t5 = new MyThread2();
//将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
//使用定时执行风格的方法
pool.schedule(t4, 1000, TimeUnit.MILLISECONDS); //t4 和 t5 在 10 秒后执行
pool.schedule(t5, 1000, TimeUnit.MILLISECONDS);
//关闭线程池
pool.shutdown();
}
}
class MyThread2 extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "正在执行。。。");
}
}
运行结果:
运行结果:
pool-1-thread-1 正在执行。。。
pool-1-thread-2 正在执行。。。
pool-1-thread-1 正在执行。。。
pool-1-thread-1 正在执行。。。
pool-1-thread-2 正在执行。。。
4.1.2 ExecutorService 执行器服务
ExecutorService 接口表示一个异步执行机制,使我们能够在后台执行任务。因此一个 ExecutorService 很类似于一个线程池。实际上,存在于 java.util.concurrent 包里的 ExecutorService 实现就是一个线程池实现。可直接执行new Runnable接口的异步方法。
//线程工厂类创建出线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
//执行一个线程任务
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
//线程池关闭
executorService.shutdown();
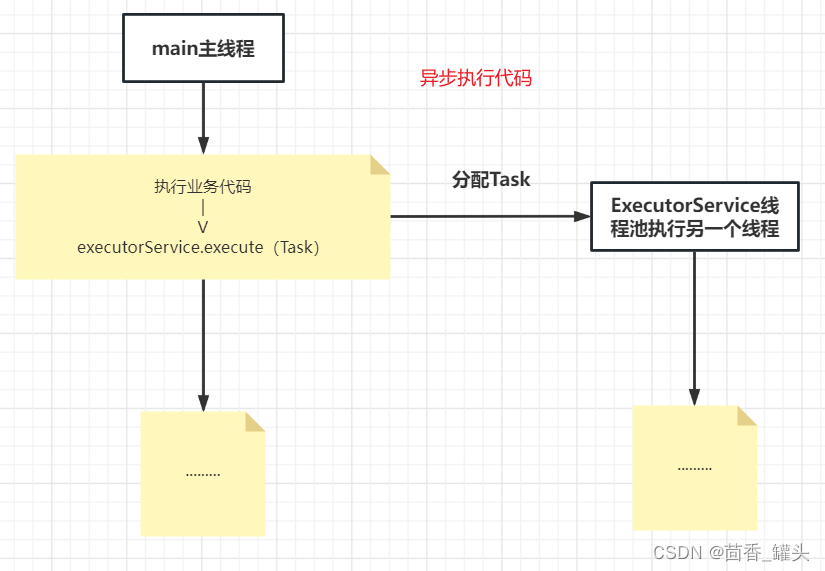
上面代码首先使用 newFixedThreadPool() 工厂方法创建一个 ExecutorService。这里创建了一个十个线程执行任务的线程池。然后,将一个 Runnable 接口的匿名实现类传递给 execute() 方法。这将导致 ExecutorService 中的某个线程执行该 Runnable。这里可以看成一个任务分派,示例代码中的任务分派我们可以理解为:
一个线程将一个任务委派给一个 ExecutorService 去异步执行。
一旦该线程将任务委派给ExecutorService,该线程将继续它自己的执行,独立于该任务的执行。
如图示:
4.1.2.1 ExecutorService 实现
既然 ExecutorService 是个接口,如果你想用它的话就得去使用它的实现类之一。
java.util.concurrent 包提供了 ExecutorService 接口的以下实现类:
- ThreadPoolExecutor
- ScheduledThreadPoolExecutor
4.1.2.2 ExecutorService 创建
ExecutorService 的创建依赖于你使用的具体实现。但是你也可以使用 Executors 工厂类来创建ExecutorService 实例。代码示例:
//不管 execute 执行几次,线程池始终都会使用单个线程来处理
ExecutorService executorService1 = Executors.newSingleThreadExecutor();
//创建固定大小的线程
ExecutorService executorService2 = Executors.newFixedThreadPool(10);
//以无界队列方式来运行该线程
ExecutorService executorService3 = Executors.newCachedThreadPool();
//创建可具有延迟功能的线程
ExecutorService executorService4 = Executors.newScheduledThreadPool(10);
4.1.2.3 ExecutorService 执行的几种方式
execute(Runnable)
submit(Runnable)
submit(Callable)
invokeAny(…)
invokeAll(…)
1. 案例一:
//从 Executors 中获得 ExecutorService
//缺点:没有办法得知被执行的 Runnable 的执行结果
ExecutorService executorService = Executors.newSingleThreadExecutor();
//执行 ExecutorService 中的方法
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
//线程池关闭
executorService.shutdown();
案例二:
submit(Runnable) 方法也要求一个 Runnable 实现类,但它返回一个 Future 对象。这个 Future 对象可
以用来检查 Runnable 是否已经执行完毕。以下是 ExecutorService submit()
//从 Executors 中获得 ExecutorService
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future future = executorService.submit(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
future.get(); //获得执行完 run 方法后的返回值,这里使用的 Runnable,所以这里没有返回值,返回的是 null。
executorService.shutdown();
案例三:
submit(Callable) 方法类似于 submit(Runnable) 方法,除了它所要求的参数类型之外。Callable 实例 除了它的 call() 方法能够返回一个结果之外和一个 Runnable 很相像。Runnable.run() 不能够返回一个结果。Callable 的结果可以通过 submit(Callable) 方法返回的 Future 对象进行获取。
//从 Executors 中获得 ExecutorService
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future future = executorService.submit(new Callable(){
public Object call() throws Exception {
System.out.println("Asynchronous Callable");
return "Callable Result";
}
});
System.out.println("future.get() = " + future.get());
executorService.shutdown();
输出:
Asynchronous Callable
future.get() = Callable Result
案例四:
invokeAny() 方法要求一系列的 Callable 或者其子接口的实例对象。调用这个方法并不会返回一个 Future, 但它返回其中一个 Callable 对象的结果。无法保证返回的是哪个 Callable 的结果 – 只能表明其中一个已执行结束。
如果其中一个任务执行结束(或者抛了一个异常),其他 Callable 将被取消。
ExecutorService executorService = Executors.newSingleThreadExecutor();
Set<Callable<String>> callables = new HashSet<Callable<String>>();
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 1";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 2";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 3";
}
});
String result = executorService.invokeAny(callables);
System.out.println("result = " + result);
executorService.shutdown();
案例五:
invokeAll() 方法将调用你在集合中传给 ExecutorService 的所有 Callable 对象。invokeAll() 返回一系列的 Future 对象,通过它们你可以获取每个 Callable 的执行结果。
记住,一个任务可能会由于一个异常而结束,因此它可能没有 “成功”。无法通过一个 Future 对象来告知我们是两种结束中的哪一种。
ExecutorService executorService = Executors.newSingleThreadExecutor();
Set<Callable<String>> callables = new HashSet<Callable<String>>();
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 1";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 2";
}
});
callables.add(new Callable<String>() {
public String call() throws Exception {
return "Task 3";
}
});
List<Future<String>> futures = executorService.invokeAll(callables);
for(Future<String> future : futures){
System.out.println("future.get = " + future.get());
}
executorService.shutdown();
输出结果:
future.get = Task 3
future.get = Task 1
future.get = Task 2
Executors 关闭:
使用 shutdown 和 shutdownNow 可以关闭线程池
两者的区别:
shutdown 只是将空闲的线程 interrupt() 了,shutdown()之前提交的任务可以继续执行直到结束。
shutdownNow 是 interrupt 所有线程, 因此大部分线程将立刻被中断。之所以是大部分,而不是全部 ,
是因为 interrupt()方法能力有限。
4.1.3 ThreadPoolExecutor 线程池执行者
java.util.concurrent.ThreadPoolExecutor 是 ExecutorService 接口的一个实现。ThreadPoolExecutor 使用
其内部池中的线程执行给定任务(Callable 或者 Runnable)。
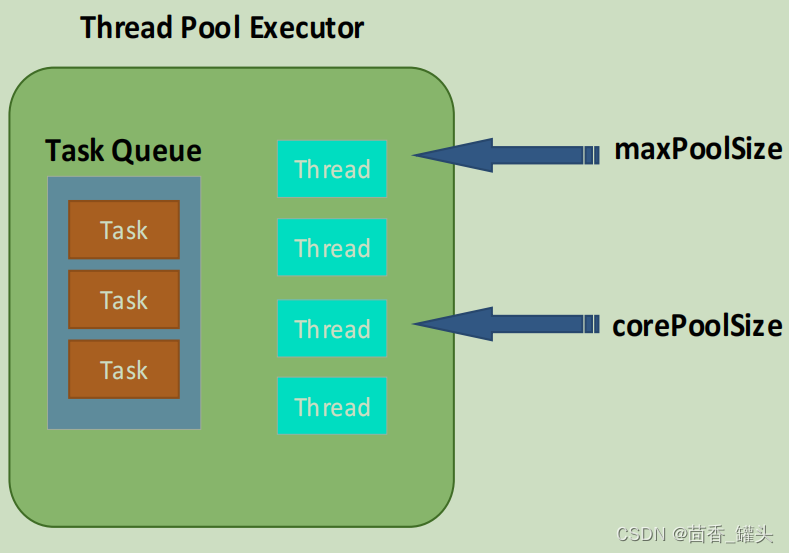
ThreadPoolExecutor 包含的线程池能够包含不同数量的线程。池中线程的数量由以下变量决定:
corePoolSize
maximumPoolSize
当一个任务委托给线程池时,如果池中线程数量低于 corePoolSize,一个新的线程将被创建,即使池中可能尚有空 闲 线 程 。 如 果 内 部 任 务 队 列 已 满 , 而 且 有 至 少 corePoolSize 正 在 运 行 , 但 是 运 行 线 程 的 数 量 低 于
maximumPoolSize,一个新的线程将被创建去执行该任务。
ThreadPoolExecutor 图解:
创建 ThreadPoolExecutor:
int corePoolSize = 5;
int maxPoolSize = 10;
long keepAliveTime = 5000;
ExecutorService threadPoolExecutor =
new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
keepAliveTime,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()
);
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize - 池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute 方法提交的 Runnable 任务。
4.1.4 ScheduledPoolExecutor 定时线程池执行者
java.util.concurrent.ScheduledExecutorService 是一个 ExecutorService, 它能够将任务延后执行,或者间隔固定时间多次执行。 任务由一个工作者线程异步执行,而不是由提交任务给 ScheduledExecutorService 的那个线程执行。
//首先一个内置 5 个线程的 ScheduledExecutorService 被创建。
//之后一个 Callable 接口的匿名类示例被创建,然后传递给 schedule() 方法。
//后边的俩参数定义了 Callable 将在 5 秒钟之后被执行。
//然后传递给 schedule() 方法。后边的俩参数定义了 Callable 将在 5 秒钟之后被执行。
ScheduledExecutorService scheduledExecutorService =
Executors.newScheduledThreadPool(5);
ScheduledFuture scheduledFuture = scheduledExecutorService.schedule(new Callable() {
public Object call() throws Exception {
System.out.println("Executed!");
return "Called!";
}
},
5,
TimeUnit.SECONDS);//5 秒后执行
4.1.4.1 ScheduledExecutorService 的实现:
ScheduledExecutorService 是一个接口,你要用它的话就得使用 java.util.concurrent 包里对它的某个实现类。ScheduledExecutorService 具有以下实现类:
ScheduledThreadPoolExecutor
创建一个 ScheduledExecutorService:
如何创建一个 ScheduledExecutorService 取决于你采用的它的实现类。但是你也可以使用 Executors 工厂类来创建一个 ScheduledExecutorService 实例。
比如:
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
ScheduledExecutorService 的使用:
一旦你创建了一个 ScheduledExecutorService,你可以通过调用它的以下方法:
schedule (Callable task, long delay, TimeUnit timeunit)
schedule(Runnable task, long delay, TimeUnit timeunit)
scheduleAtFixedRate(Runnable, long initialDelay, long period, TimeUnit timeunit)
scheduleWithFixedDelay (Runnable, long initialDelay, long period,TimeUnit timeunit)
方式一:
schedule (Callable task, long delay, TimeUnit timeunit)
ScheduledExecutorService scheduledExecutorService =
Executors.newScheduledThreadPool(5);
ScheduledFuture scheduledFuture =scheduledExecutorService.schedule(new Callable() {
public Object call() throws Exception {
System.out.println("Executed!");
return "Called!";
}
},
5,
TimeUnit.SECONDS);
System.out.println("result = " + scheduledFuture.get());
scheduledExecutorService.shutdown();
输出结果:
Executed!
result = Called!
方式二:
schedule (Runnable task, long delay, TimeUnit timeunit)
这一方法规划一个任务将被定期执行。该任务将会在首个 initialDelay 之后得到执行,然后每个 period 时间之后重复执行。
如果给定任务的执行抛出了异常,该任务将不再执行。如果没有任何异常的话,这个任务将会持续循环执行到ScheduledExecutorService 被关闭。
如果一个任务占用了比计划的时间间隔更长的时候,下一次执行将在当前执行结束执行才开始。计划任务在同一时间不会有多个线程同时执行。
方式三:
scheduleAtFixedRate (Runnable, long initialDelay, long period, TimeUnit timeunit)
这一方法规划一个任务将被定期执行。该任务将会在首个 initialDelay 之后得到执行,然后每个 period 时间之后重复执行。
如果给定任务的执行抛出了异常,该任务将不再执行。如果没有任何异常的话,这个任务将会持续循环执行到ScheduledExecutorService 被关闭。
如果一个任务占用了比计划的时间间隔更长的时候,下一次执行将在当前执行结束执行才开始。计划任务在同一时间不会有多个线程同时执行。
方式四:
scheduleWithFixedDelay (Runnable, long initialDelay, long period, TimeUnit timeunit)
除了 period 有不同的解释之外这个方法和 scheduleAtFixedRate() 非常像。scheduleAtFixedRate() 方法中,period 被解释为前一个执行的开始和下一个执行的开始之间的间隔时间。而在本方中,period 则被解释为前一个执行的结束和下一个执行的结束之间的间隔。因此这个延迟是执行结束之间的间隔,而不是执行开始之间的间隔。
ScheduledExecutorService 的关闭
正如 ExecutorService,在你使用结束之后你需要把 ScheduledExecutorService 关闭掉。否则他将导致 JVM 继续运行,即使所有其他线程已经全被关闭。
你 可 以 使 用 从 ExecutorService 接 口 继 承 来 的 shutdown() 或 shutdownNow() 方 法 将ScheduledExecutorService 关闭。参见 ExecutorService 关闭部分以获取更多信息。
4.1.5 ForkJoinPool 合并和分叉
留言发文档。
B 并发队列-阻塞队列
常用的并发队列有阻塞队列和非阻塞队列,前者使用锁实现,后者则使用 CAS 非阻塞算法实现。
4.1.6 BlockingQueue 阻塞队列
阻塞队列 (BlockingQueue)是 Java util.concurrent 包下重要的数据结构,BlockingQueue 提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。并发包下很多高级同步类的实现都是基于 BlockingQueue 实现的。
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。
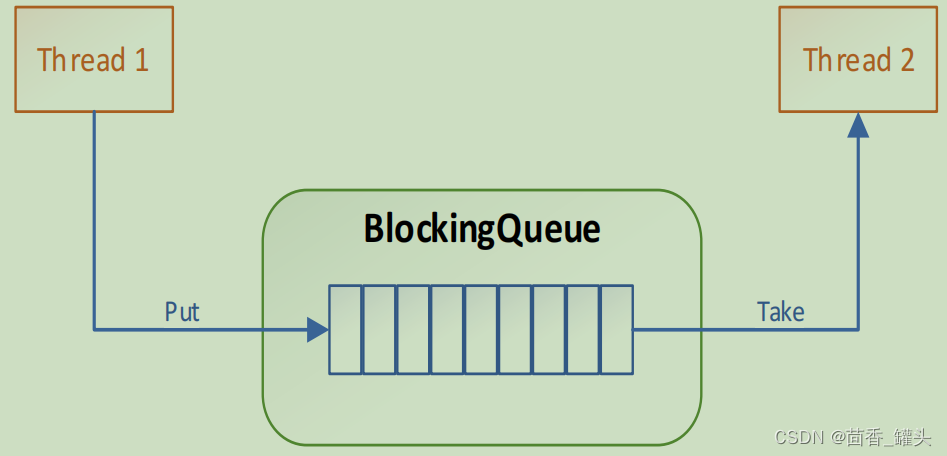
- 一个线程往里边放,另外一个线程从里边取的一个 BlockingQueue。
- 一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,
直到负责消费的线程从队列中拿走一个对象。负责消费的线程将会一直从该阻塞队列中拿出对象。 - 如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
- 无法向一个 BlockingQueue 中插入 null。如果你试图插入 null,BlockingQueue 将会抛出一个NullPointerException.
方法:
BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
四组不同的行为方式解释:
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
BlockingQueue 的实现类:
BlockingQueue 是个接口,你需要使用它的实现之一来使用 BlockingQueue,Java.util.concurrent 包下具有以
下 BlockingQueue 接口的实现类:
4.1.7 实现类ArrayBlockingQueue:
ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了(译者注:因为它是基于数组实现的,也就具有数组的特性:一旦初始化,大小就无法修改)。
4.1.8 DelayQueue
DelayQueue 对元素进行持有直到一个特定的延迟到期。注入其中的元素必须实现
java.util.concurrent.Delayed 接口。
4.1.9 LinkedBlockingQueue
LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
4.1.10 PriorityBlockingQueue
PriorityBlockingQueue 是 一 个 无 界 的 并 发 队 列 。 它 使 用 了 和 类java.util.PriorityQueue 一 样 的 排 序 规 则 。 你 无 法 向 这 个 队 列 中 插 入 null 值 。 所 有 插 入 到PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。
4.1.11 SynchronousQueue
SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点。
4.1.12 DeplayQueue 延时无界阻塞队列
留言发文档, 太多了。
C. 并发(Collection)队列-非阻塞队列
4.1.13 非阻塞队列
4.1.14 非阻塞算法 CAS 悲观锁 乐观锁
4.1.15 ConcurrentLinkedQueue 非阻塞无界链表队列
4.1.16 ConcurrentHashMap 非阻塞 Hash 集合
4.1.17 ConcurrentLinkedQuere
4.1.18 ConcurrentSkipListMap 非阻塞 Hash 跳表集合
妈呀, 东西太多了, 需要的去下载我上传的文档吧。
4.1.2 java.util.concurrent.atomic 包
(多线程的原子性操作提供的工具类)
- 查看 atomic 包文档页下面的介绍,它可以对多线程的基本数据、数组中的基本数据和对象中的基本数据进行多线程的操作(AtomicInteger、AtomicIntegerArray、AtomicIntegerFieldUpDater…)
- 通过如下两个方法快速理解 atomic 包的意义:
- AtomicInteger 类的 boolean compareAndSet(expectedValue, updateValue);
- AtomicIntegerArray 类的 int addAndGet(int i, int delta);
- 顺带解释 volatile 类型的作用,需要查看 java 语言规范。
- volatile 修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最后值。(具有可见性) volatile 没有原子性。
4.1.3 java.util.concurrent.lock 包
(多线程的锁机制)
为锁和等待条件提供一个框架的接口和类,它不同于内置同步和监视器。该框架允许更灵活地使用锁和条件。
本包下有三大接口,下面简单介绍下:
➢Lock 接口:支持那些语义不同(重入、公平等)的锁规则,可以在非阻塞式结构的上下文(包括 hand-over-hand 和锁重排算法)中使用这些规则。主要的实现是 ReentrantLock。
➢ReadWriteLock 接口:以类似方式定义了一些读取者可以共享而写入者独占的锁。此包只提供了一个实现,即 ReentrantReadWriteLock,因为它适用于大部分的标准用法上下文。但程序员可以创建自己的、适用于非标准要求的实现。
➢Condition 接口:描述了可能会与锁有关联的条件变量。这些变量在用法上与使用 Object.wait 访问的隐式监视器类似,但提供了更强大的功能。需要特别指出的是,单个 Lock 可能与多个 Condition 对象关联。为了避免兼容性问题,Condition 方法的名称与对应的 Object 版本中的不同。
5. 必须要看
内容太多了, 可以去我上传的文档里下载,(Java知识点及面试宝典) 很详细,很全。

















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









