




 本文深入解析MapReduce中的Shuffle过程,涵盖Map端和Reduce端的详细步骤,包括split、partition、spill溢写、sort排序、combiner合并、merge过程,以及reduce操作和文件写入HDFS的流程。同时探讨了数据倾斜现象、原因及其解决方案。
本文深入解析MapReduce中的Shuffle过程,涵盖Map端和Reduce端的详细步骤,包括split、partition、spill溢写、sort排序、combiner合并、merge过程,以及reduce操作和文件写入HDFS的流程。同时探讨了数据倾斜现象、原因及其解决方案。
一、MapReduce中的Shuffle过程:
怎样把map task的输出结果有效地传送到reduce输入端。
Shuffle的本意是洗牌、混乱的意思,它会随机地打乱参数list里的元素顺序。
从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。 Shuffle描述着数据从map task输出到reduce task输入的这段过程。
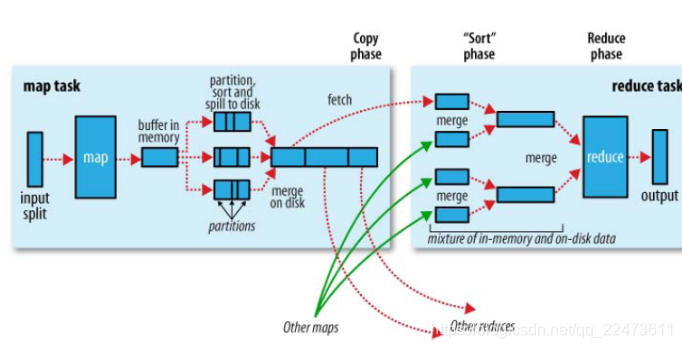
上图表示的是Shuffle的整个过程。在Hadoop这样的集群环境中,大部分map task与reduce task的执行是在不同的节点上。当然很多情况下Reduce执行时需要跨节点去读取其它节点上的map task结果,并存储到本地。如果集群正在运行的job有很多,那么task的正常执行对集群内部的网络资源消耗会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。另外在节点内,相比于内存,磁盘IO对job完成时间的影响也是比较大的,spark 就是基于这点对hadoop做出了改进,将map和reduce的所有任务都在内存中进行,并且中间接过都保存在内存中,从而比hadoop的速度要快100倍以上。从最基本的要求来说,我们对Shuffle过程希望做到:
- 完整地从map task端读取数据到reduce 端。
- 在跨节点读取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
Shuffle实际上包括map端和reduce端的两个过程,在map端中我们称之为前半段,在reduce端我们称之为后半段。
一、Map端:
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner,combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来读取数据。 下面可以将Shuffle过程主要分为四个步骤:(结合WordCount的例子来进行说明)
1、Map端的Shuffle过程主要包括:
1、split过程
对输入文件进行切分
splitSize=max(minSize,min(goalSize,blockSize))
备注:默认blockSize是64M,goalSize=totalSize/partition_num,totalSize原始文件大小,partition_num用户设置的大小;minSize=max(SPLIT_MINSIZE,1) ,SPLIT_MINSIZE默认值是1;
按照上面的策略进行文件的切分,可以得到每个分块的数据,且每个分块对应一个分区Partition,(若存在多个小文件,则每个小文件对应一个分区)
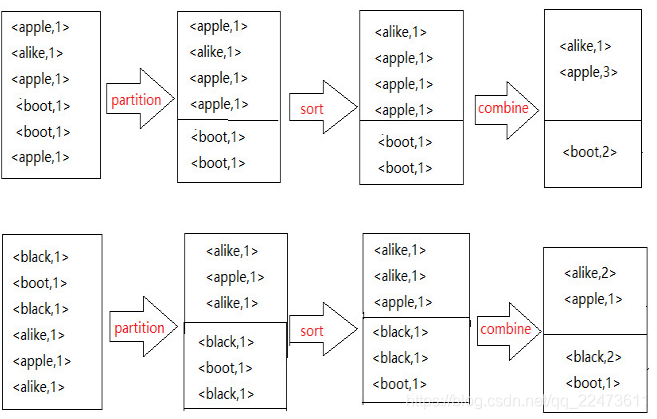
2、partition过程:
partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。
在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“aaa”, value是数值1。
到底当前的“aaa”应该交由哪个reduce去做呢,这个主要有partition来决定
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模。
3、spill溢写过程
这个内存缓冲区是有大小限制的,默认是100MB,spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。 最后将数据写到本地磁盘产生spill文件
3.1、Sort排序
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。
对于WordCount例子,就是简单地统计单词出现的次数,如果在同一个map task的结果中有很多个像“aaa”一样出现多次的key,我们就应该把它们的值合并到一块,这个过程叫reduce也叫combine。Combiner的输出是Reducer的输入。
{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。
3.2、Combiner合并
可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
4、Merge过程
merge是将多个溢写文件合并到一个文件。每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
二、Reduce端的shuffle主要包括三个阶段,copy、merge、sort和reduce。

首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也称为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
简单地说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
1. Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2. Merge阶段。
在reducetask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据进行合并操作。
这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3.sort阶段:
在对数据进行合并的同时,会进行排序操作,由于maptask阶段已经对数据进行了局部的排序,reducetask只需要保证copy的数据的最终整体有效性即可,shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越小,执行速度就越快,缓冲区的大小可以通过参数进行调整,参数:io.sort.mb默认100M
4. Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
五、reduce操作
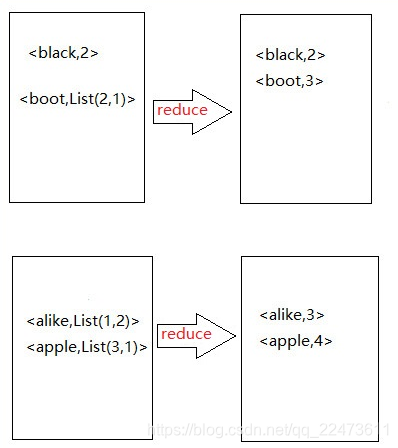
六、文件写入HDFS

一. 数据倾斜的现象
多数task执行速度较快,少数task执行时间非常长,或者等待很长时间后提示你内存不足,执行失败。
二. 数据倾斜的原因
常见于各种shuffle操作,例如reduceByKey, groupByKey, join等操作。
- key本身分布不均匀(包括大量的key为空)
- key的设置不合理
spark使用问题
- shuffle时的并发度不够
- 计算方式有误
三. 数据倾斜的后果
- spark中一个stage的执行时间受限于最后那个执行完的task,因此运行缓慢的任务会拖累整个程序的运行速度(分布式程序运行的速度是由最慢的那个task决定的)。
- 过多的数据在同一个task中执行,将会把executor撑爆,造成OOM,程序终止运行。
一个理想的分布式程序:

发生数据倾斜时,任务的执行速度由最大的那个任务决定:

四. 数据问题造成的数据倾斜
发现数据倾斜的时候,不要急于提高executor的资源,修改参数或是修改程序,首先要检查数据本身,是否存在异常数据。
找出异常的key
如果任务长时间卡在最后最后1个(几个)任务,首先要对key进行抽样分析,判断是哪些key造成的。
选取key,对数据进行抽样,统计出现的次数,根据出现次数大小排序取出前几个
df.select("key").sample(false,0.1).(k=>(k,1)).reduceBykey(_+_).map(k=>(k._2,k._1)).sortByKey(false).take(10)
- 1
- 2
如果发现多数数据分布都较为平均,而个别数据比其他数据大上若干个数量级,则说明发生了数据倾斜。
经过分析,倾斜的数据主要有以下三种情况:
- null(空值)或是一些无意义的信息()之类的,大多是这个原因引起。
- 无效数据,大量重复的测试数据或是对结果影响不大的有效数据。
- 有效数据,业务导致的正常数据分布
解决办法
第1,2种情况,直接对数据进行过滤即可。
第3种情况则需要进行一些特殊操作,常见的有以下几种做法。
- 隔离执行,将异常的key过滤出来单独处理,最后与正常数据的处理结果进行union操作。
- 对key先添加随机值,进行操作后,去掉随机值,再进行一次操作。
- 使用
reduceByKey代替groupByKey - 使用map join。
举例:
如果使用reduceByKey因为数据倾斜造成运行失败的问题。具体操作如下:
- 将原始的
key转化为key + 随机值(例如Random.nextInt) - 对数据进行
reduceByKey(func) - 将
key + 随机值转成key - 再对数据进行
reduceByKey(func)
tip1: 如果此时依旧存在问题,建议筛选出倾斜的数据单独处理。最后将这份数据与正常的数据进行union即可。
tips2: 单独处理异常数据时,可以配合使用Map Join解决。
五. spark使用不当造成的数据倾斜
1. 提高shuffle并行度
dataFrame和sparkSql可以设置spark.sql.shuffle.partitions参数控制shuffle的并发度,默认为200。
rdd操作可以设置spark.default.parallelism控制并发度,默认参数由不同的Cluster Manager控制。
局限性: 只是让每个task执行更少的不同的key。无法解决个别key特别大的情况造成的倾斜,如果某些key的大小非常大,即使一个task单独执行它,也会受到数据倾斜的困扰。
2. 使用map join 代替reduce join
在小表不是特别大(取决于你的executor大小)的情况下使用,可以使程序避免shuffle的过程,自然也就没有数据倾斜的困扰了。
局限性: 因为是先将小数据发送到每个executor上,所以数据量不能太大。
五、MapReduce 实现join

/**
* MapReduce实现Join操作
*/
public class MapRedJoin {
public static final String DELIMITER = "\u0009"; // 字段分隔符
// map过程
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException, ClassCastException {
// 获取输入文件的全路径和名称
String filePath = ((FileSplit) reporter.getInputSplit()).getPath().toString();
// 获取记录字符串
String line = value.toString();
// 抛弃空记录
if (line == null || line.equals("")) return;
// 处理来自表A的记录
if (filePath.contains("m_ys_lab_jointest_a")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 2) return;
String id = values[0]; // id
String name = values[1]; // name
output.collect(new Text(id), new Text("a#" + name));
}
// 处理来自表B的记录
else if (filePath.contains("m_ys_lab_jointest_b")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 3) return;
String id = values[0]; // id
String statyear = values[1]; // statyear
String num = values[2]; //num
output.collect(new Text(id), new Text("b#" + statyear + DELIMITER + num));
}
}
}
// reduce过程
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
Vector<String> vecA = new Vector<String>(); // 存放来自表A的值
Vector<String> vecB = new Vector<String>(); // 存放来自表B的值
while (values.hasNext()) {
String value = values.next().toString();
if (value.startsWith("a#")) {
vecA.add(value.substring(2));
} else if (value.startsWith("b#")) {
vecB.add(value.substring(2));
}
}
int sizeA = vecA.size();
int sizeB = vecB.size();
// 遍历两个向量
int i, j;
for (i = 0; i < sizeA; i++) {
for (j = 0; j < sizeB; j++) {
output.collect(key, new Text(vecA.get(i) + DELIMITER + vecB.get(j)));
}
}
}
}
}技术细节
下面说一下其中的若干技术细节:
(1)由于输入数据涉及两张表,我们需要判断当前处理的记录是来自表A还是来自表B。Reporter类getInputSplit()方法可以获取输入数据的路径,具体代码如下:
String filePath = ((FileSplit)reporter.getInputSplit()).getPath().toString();
(2)map的输出的结果,同id的所有记录(不管来自表A还是表B)都在同一个key下保存在同一个列表中,在reduce阶段需要将其拆开,保存为相当于笛卡尔积的m x n条记录。由于事先不知道m、n是多少,这里使用了两个向量(可增长数组)来分别保存来自表A和表B的记录,再用一个两层嵌套循环组织出我们需要的最终结果。
(3)在MapReduce中可以使用System.out.println()方法输出,以方便调试。不过System.out.println()的内容不会在终端显示,而是输出到了stdout和stderr这两个文件中,这两个文件位于logs/userlogs/attempt_xxx目录下。可以通过web端的历史job查看中的“Analyse This Job”来查看stdout和stderr的内容。


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











