




 本文深入剖析Spark作业提交流程,从源码角度解读yarn-cluster与yarn-client模式下的作业提交细节,涵盖spark-submit脚本执行逻辑、SparkSubmit类工作原理及DAGScheduler与TaskScheduler在任务调度中的关键角色。
本文深入剖析Spark作业提交流程,从源码角度解读yarn-cluster与yarn-client模式下的作业提交细节,涵盖spark-submit脚本执行逻辑、SparkSubmit类工作原理及DAGScheduler与TaskScheduler在任务调度中的关键角色。
以yarn-cluster模式为例源码分析作业提交流程
##spark-yarn-cluster模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--num-executors 2 \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
##spark-yarn-client模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--num-executors 2 \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
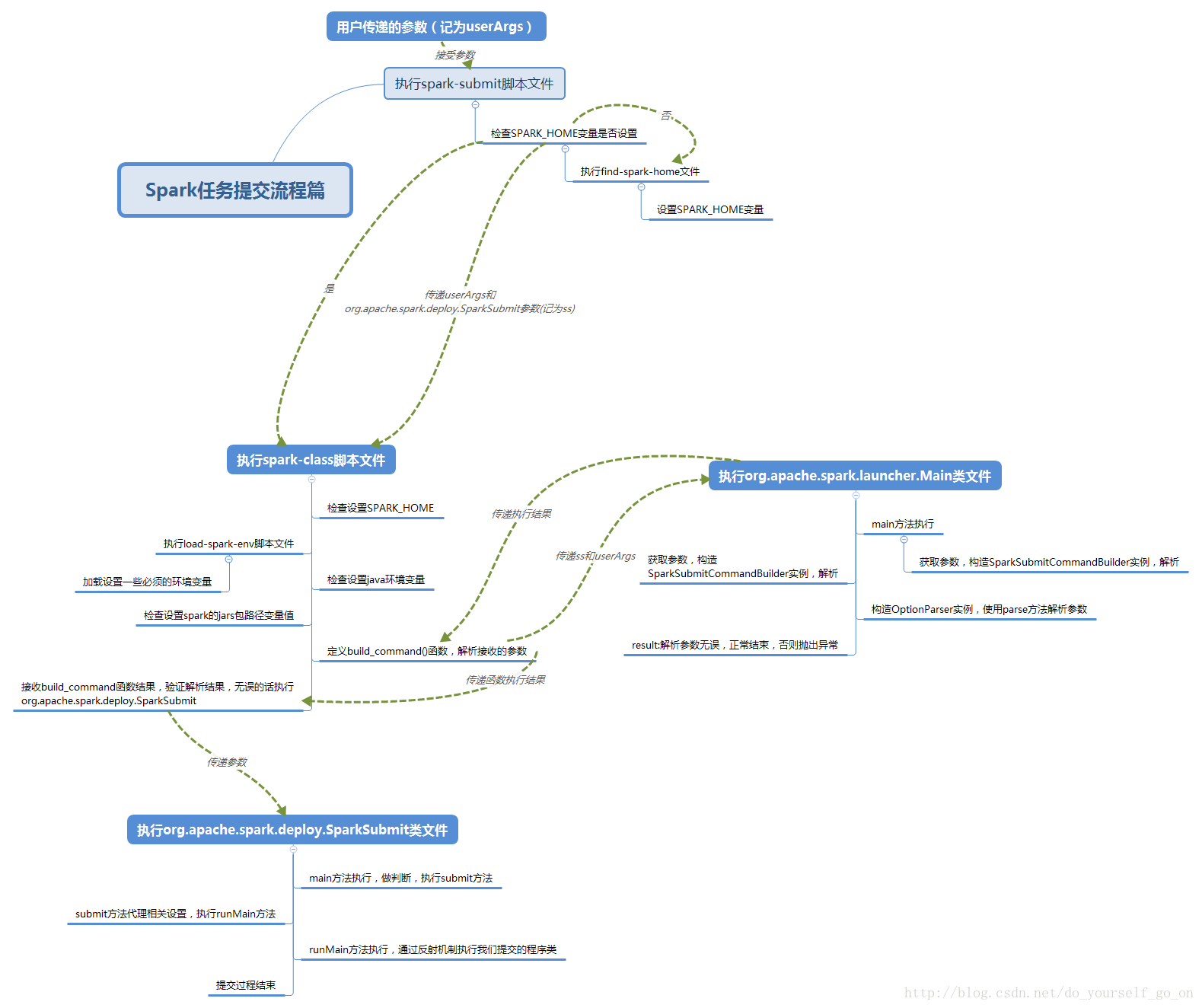
2.1 spark-submit脚本
#!/usr/bin/env bash
# -z是检查后面变量是否为空(空则真) shell可以在双引号之内引用变量,单引号不可
#这一步作用是检查SPARK_HOME变量是否为空,为空则执行then后面程序
#source命令: source filename作用在当前bash环境下读取并执行filename中的命令
#$0代表shell脚本文件本身的文件名,这里即使spark-submit
#dirname用于取得脚本文件所在目录 dirname $0取得当前脚本文件所在目录
#$(命令)表示返回该命令的结果
#故整个if语句的含义是:如果SPARK_HOME变量没有设置值,则执行当前目录下的find-spark-home脚本文件,设置SPARK_HOME值
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
#执行spark-class脚本,传递参数org.apache.spark.deploy.SparkSubmit 和"$@"
#这里$@表示之前spark-submit接收到的全部参数
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"2.2 spark-class脚本
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# 配置一些环境变量,它会将conf/spark-env.sh中的环境变量加载进来:
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary 如果有java_home环境变量会将java_home/bin/java给RUNNER
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
# 这一段,主要是寻找java命令 寻找spark的jar包
# 这里如果我们的jar包数量多,而且内容大,可以事先放到每个机器的对应目录下,这里是一个优化点
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
# 启动程序库将打印由NULL字符分隔的参数,以允许与shell进行其他解释的字符进行参数。在while循环中读取它,填充将用于执行最终命令的数组。
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
# 启动程序的退出代码被追加到输出,因此父shell从命令数组中删除它,并检查其值,看看启动器是否成功。
# 这里spark启动了以SparkSubmit为主类的JVM进程。
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
# 关闭posix模式,因为它不允许进程替换。
# 调用build_command org.apache.spark.launcher.Main拼接提交命令
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
# 某些JVM失败会导致错误被打印到stdout(而不是stderr),这会导致解析启动程序输出的代码变得混乱。
# 在这些情况下,检查退出代码是否为整数,如果不是,将其作为特殊的错误处理。
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
# ${CMD[@]} 参数如下
# /Library/Java/JavaVirtualMachines/jdk1.8.0_172.jdk/Contents/Home/bin/java -cp /Users/lipan/workspace/source_code/spark-2.3.3/conf/:/Users/lipan/workspace/source_code/spark-2.3.3/assembly/target/scala-2.11/jars/* -Xmx1g org.apache.spark.deploy.SparkSubmit --master local --class com.lp.test.app.LocalPi /Users/lipan/Desktop/spark-local/original-spark-local-train-1.0.jar 10
exec "${CMD[@]}"
相对于spark-submit,spark-class文件的执行逻辑稍显复杂,总体如下:
- 检查SPARK_HOME执行环境
- 执行load-spark-env.sh文件,加载一些默认的环境变量(包括加载spark-env.sh文件)
- 检查JAVA_HOME执行环境
- 寻找Spark相关的jar包
- 执行org.apache.spark.launcher.Main解析参数,构建CMD命令
- CMD命令判断
- 执行org.apache.spark.deploy.SparkSubmit这个类。
2.3 org.apache.spark.launcher.Main
Spark-submit提交源码解析
执行spark-submit实际上执行的是$SPARK_HOME/spark-class
spark-class 中:RUNNER="${JAVA_HOME}/bin/java"
##执行java 类 -->相当于启动一个JVM -->就是启动一个进程Process(进程中有独立内存、线程)
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH"(#就是类路径)
org.apache.spark.launcher.Main <=> 等同于执行Main这个类,调用main方法(它就是检查参数、构建CommandBuiler指令)
build_command()构建指令;
最终是要执行 SparkSubmit xxx是命令行参数
##className.equals("org.apache.spark.deploy.SparkSubmit")
它就会启动一个叫SparkSubmit进程
org.apache.spark.deploy.SparkSubmit --xx等参数SparkSubmit 类,对命令行参数进行了封装,准备提交环境,
不是集群模式它会拿到指令中的--class所传的类,
if(isYarnCluster)-->> org.apache.spark.deploy.yarn.Client
利用反射通过类名获取类的信息,利用反射通过类信息获取Main方法,调用Client的main方法: Client的调用只是一个普通方法的调用
SparkSubmit进程(启动一个java虚拟机即启动一个进程名字就叫 SparkSubmit )-->调用 yarn.Client方法,
YarnClient根据yarn的配置进行初始化创建yarn客户端并启动yarnClient.start()启动客户端,
为了与Yarn做关联,获取一个appId,yarn的全局id,根据id可以查询它的所有信息;
Client向yarn的RM提交应用,集群模式通过submitApplication()---launcherBackend.connect() ;
Client的 submitApplication (抽象方法->去找它的实现类YarnClientImpl)向RM提交应用完成之后;
rmClient.submitApplication(request)来跟RM做关联;
submitApplication.createContainerLaunchContext 去启动一个进程执行 ApplicationMaster ;
yarnClient.submitApplication(appContext)
//把上边封装好的指令|类给yarnClient,由yarn来执行 ,
Client把类提交给yarn之后就完成了,这时Client客户端就结束了;RM找一个节点NM来启动ApplicationMaster--java command;
虽然只是不是集群模式它的类是ExecutorLauncher,但底层它同样还是调用的ApplicationMaster.main;
集群模式
集群模式它运行的是Driver,启动用户应用 就是--class提交的类(通过类加载器);
new Thread("Driver").start() Driver只是ApplicationMaster进程中的一个线程起名叫Driver;
之后它运行的是--class.invoke(main)就是你写的那个有sparkContext的main方法的那个类称为Driver类;
向Yarn的RM注册AM,并申请资源;
RM会返回一个资源列表,去进行分配资源,资源是以container的方式;
分配可用资源 (移动数据不如移动计算(计算在Driver,数据在某个节点executor,driver来分配任务task发给哪个节点),本地化级别);
AM建立与NM的关联,向指定的资源NM发送指令;
NM就会启动,它启动它的container容器;
//启动一个进程 JAVA_HOME/bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend //执行器的后台,数据对接收处理,在NM中执行,粗粒度的执行器后台;
所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性;
反向注册就是建立executor和driver之间的关系,告诉driver我有一个executor已经启动了;
向远程的executor引用发送消息说在driver中已经注册好了可以启动了;
RDD中的数据变成一个个分区的数据,一个个分区变成任务
RDD(对数据计算逻辑的 抽象,里边没有数据)提交SparkSubmit类
// 对命令行参数进行封装
-- 1. new SparkSubmitArguments(args)
//命令行参数包含master、deployMode、executorMemory等 ;
在scala中,类{ 类体or构造函数体 },参数中类体,类初始化时都会执行parse(args.asJava)类体中;
parse方法做了正则的匹配 Pattern.compile("(--[^=]+)=(.+)") ==> handle (源码326)方法对传的命令行参数做模式匹配;
SparkSubmit类,appArgs.action.match{ SUBMIT| ... }模式匹配,action在SparkSubmitArguments做了封装 action = Option(action).getOrElse(SUBMIT)
-- 2. submit(SparkSubmit中的方法)
// 准备提交环境
-- 2.1 prepareSubmitEnvironment
-- 2.2 doRunMain(声明了但没有执行) isStandaloneCluster 和 其他模式都会走doRunMain方法
-- 2.3 runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)参数来自提交对环境准备 <--if (args.proxyUser != null)
-- 2.3.1 ClassLoader : Thread.currentThread.setContextClassLoader(loader) //loader类加载器,把类放到集群的节点上去执行;
// childMainClass(Client):org.apache.spark.examples.SparkPi //不是集群模式它会拿到指令中的--class所传的类
// childMainClass(Cluster):org.apache.spark.deploy.yarn.Client // if (isYarnCluster)集群模式
// 反射:通过类名获取类的信息
-- 2.3.2 mainClass = Utils.classForName(childMainClass)
//var mainClass: Class[_] = null,Class为类的全部信息;
// 反射:通过类信息获取Main方法
-- 2.3.3 val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
// 反射:调用main方法
-- 2.3.4 mainMethod.invoke(null, childArgs.toArray)
Client
Client的调用只是一个普通方法的调用;如果是进程:java Client=》JVM=》Process; 如果是线程:Thread.start() ; 普通方法调用: method.invoke
// 对命令行参数进行封装
-- 1. new ClientArguments(argStrings) //在main方法中
-- 2. new Client(args, sparkConf).run() //它会去调用辅助构造方法-->一定会会去调用主构造方法
private val yarnClient = YarnClient.createYarnClient //它去创建yarn客户端准备去跟yarn打交道(要有yarn的server集群)
private val amMemory = if (isClusterMode) //ApplicationMaster的内存
...等等,主要是去构造属性、方法和对象
-- 3. client.run //创建好了对象.run
-- 3.1 submitApplication //this.appId = submitApplication() 提交应用;
launcherBackend.connect() //Backend叫后台
yarnClient.init(yarnConf) 根据yarn的配置进行初始化;
yarnClient.start()启动客户端 ,目的是与yarn做交互;
appId = newAppResponse.getApplicationId()//获取一个appId,yarn的全局id,根据id可以查询它的所有信息;
yarnClient.submitApplication(appContext) //Client向yarn的RM提交应用,由submitApplication(抽象方法->实现类)来完成;
rmClient.submitApplication(request); //跟RM做关联
// commands(Client): JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ExecutorLauncher
//不是集群模式 Spark-shell只能是client模式,不能是集群!!
// commands(Clustor):JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ApplicationMaster
//如果是集群模式,isClusterMode就把类对名字给amClass;启动一个ApplicationMaster进程
//这些commands上边封装好的指令类都提交给yarn,由yarn来执行,这时Client客户端就结束了;
-- 3.1.1 createContainerLaunchContext //要去封装一个指令bin/java javaOpts ++ amArgs(这个参数中Seq(amClass)) ++
启动一个进程执行ApplicationMaster
-- 3.1.2 createApplicationSubmissionContext
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
//它调用的是上边的;
// 向Yarn提交应用
-- 3.1.3 yarnClient.submitApplication(appContext)
//把上边封装好的给yarnClient(相当于这些指令发给它);
在yarn中执行,Client把类提交给yarn之后就完成了ApplicationMaster源码解析
ApplicationMaster master = new ApplicationMaster.run()即runDriver()->startUserApplication()
--->即启动一个Driver线程(通过反射来获取类名).join()还没启动,
向Yarn注册AM--registerAMclient.register().allocateResources()
进行注册和分配,申请资源,看看哪个资源可用 allocateResources资源列表;
allocateResponse.getAllocatedContainers()
//以container的形式把资源给你分配可用资源
--handleAllocatedContainers--runAllocatedContainers() //运行已经分配好的容器
if(launchContainers)--> launcherPool.execute(线程)->.run(ExecutorRunnable.run()),nmClient(即与nodeManager的关联)
nmClient.init(conf) nmClient.start() nmClient.startContainer(container.get, ctx)
//由NM(AM就在这里边)来启动这个容器
CoarseGrainedExecutorBackend
所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性;
case LaunchTask(data) => new Executor().launchTask() //executor启动任务ApplicationMaster
-- 1. main
-- 1.1. new ApplicationMasterArguments(args) //同上,封装了--jar, --class等
-- 1.2. master = new ApplicationMaster(amArgs, new YarnRMClient)
yarnConf
heartbeatInterval心跳周期
RpcEnv : RPC 进程和进程的通信协议
RpcEndpoint : 终端 RpcEndpointRef:终端引用
-- 1.3. master.run
// 集群模式它运行的是Driver;如果不是集群模式运行的就是ExecutorLauncher
-- 1.3.1 runDriver() //isClusterMode
// 启动用户应用 就是提交的类
-- 1.3.1.1 startUserApplication()--->即启动一个Driver线程
// 从命令行参数中获取--class的值,然后获取main方法; 用类加载器加载类 userClass封装类名(从命令行中获取)
-- val mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main", classOf[Array[String]])
-- new Thread("Driver").start() ==> --class.invoke(main)
启动之前:userThread.setContextClassLoader(userClassLoader) //类加载器放进去
userThread.setName("Driver") //真正的Driver是一个线程,只是把这个线程起个名字叫Driver
userThread.start() //启动之后肯定会运行线程的run方法 mainMethod.invoke(main);创建SparkConetext的那个类叫Driver,就是你写的那个main方法
虽然start,但什么时候执行不确定, userClassThread.join() //主线程不能结束,要等待它
rpcEnv = sc.env.rpcEnv构建环境对象
// 向Yarn注册AM
-- 1.3.1.2 registerAM()//client.
allocator = client.register()
allocator.allocateResources() 它们进行注册和分配,申请资源,看看哪个资源可用 allocateResources资源列表;
val allocatedContainers = allocateResponse.getAllocatedContainers() //以container的形式把资源给你,allocatedContainers是列表
// 分配可用资源 (移动数据不如移动计算(计算在Driver,数据在executor,任务task发给哪个节点),本地化级别)
-- handleAllocatedContainers
本地化(计算和数据在同一个进程里)本地化(进程本地化即计算和数据中同一个进程 |节点本地化即一个节点有多个executor,发给另外一个executor|机架本地化,发给另外一个nodemanager)
-- runAllocatedContainers() //运行已经分配好的容器
-- launcherPool.execute(线程) <-- if(launchContainers) private val launcherPool = ThreadUtils.newDaemonCachedThreadPool //ThreadPool线程池 --> val threadPool = new ThreadPoolExecutor(),底层还是调用了jdk的线程池的操作
launcherPool.execute(new Runnable{ run(方法 new ExecutorRunnable).run( 与nmClient(即nodemanager的关联) ) }) //启动一个线程来执行操作,从线程池里边去执行一个线程
-- ExecutorRunnable.run() //nmClient.init(conf) nmClient.start() startContainer() 要去连接NM
-- nmClient.start()
// 启动容器
-- startContainer
// JAVA_HOME/bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend //执行器的后台,数据对接收处理,在NM中执行;
-- val commands = prepareCommand()
-- nmClient.startContainer(container.get, ctx) //由NM(AM就在这里边)来启动这个容器;xtx就是commands指令
CoarseGrainedExecutorBackend 粗粒度的
-- 1. main
-- 1.1. run //var executor: Executor = null //所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性;
SparkEnv.createExecutorEnv() env.rpcEnv.setupEndpoint()
env.rpcEnv.awaitTermination() //主线程不会结束,需要等待它的结束
executor = new Executor() //在里边构建对象,跟CoarseGrainedExecutorBackend关系是很紧密的
case LaunchTask(data) => executor.launchTask() //executor启动任务
-- 1.1.1 env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend //把当前的Executor对象创建出来; setupEndpoint设置,它是个抽象方法=>实现类NettyRpcEnv
override def setupEndpoint(): RpcEndpointRef = {dispatcher.registerRpcEndpoint(name, endpoint)} //把当前对象进行封装成name把它绑定中一起,形成注册效果就可以实现消息对发送和接收;
registerRpcEndpoint完成注册RpcEndpointAddress
NettyRpcEndpointRef
new EndpointData() //往终端里传数据 --> val inbox = new Inbox(ref, endpoint)//收件箱
-->inbox.synchronized {messages.add(OnStart)} //往消息里发送数据,给当前终端CoarseGrainedExecutorBackend发送OnStart消息
当前终端是可以通信的;ThreadSafeRpcEndpoint extends RpcEndpoint; RpcEndpoint终端是有生命周期的:
The life-cycle of an endpoint is: constructor构造方法 -> onStart启动 -> receive* -> onStop关闭
CoarseGrainedExecutorBackend接收到消息就会去调用OnStart
-->rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap 通过URI异步的去安装引用,通过一个地址得到远程对象对引用
通过driverUrl地址建立了两个executor之间的通信,而且是异步发送;
"Connecting to driver: " + driverUrl 找到Driver所在进程(AM),异步的这个操作等同于拿到了与ApplicationMaster的关系;
driver = Some(ref) 起完driver
ref.ask[Boolean](RegisterExecutor()) 发送RegisterExecutor请求,它会去反向注册
driver应该接收消息,它是一个线程不能接收,通过以下方法:
SparkContext 中SchedulerBackend属性 它的实现类CoarseGrainedSchedulerBackend(driver这边的引用),而CoarseGrainedExecutorBackend是executor的后台引用;
它们之间通信,刚刚ref发送了消息,它就接收到--->case RegisterExecutor 在PartialFunction偏函数中(所有的模式匹配的case都是);
反向注册就是建立executor和driver之间的关系;
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
//如果executorDataMap的数据集合中包含executorId,它向executor的引用发送注册失败的消息;else就启动
context.reply(true)
executorRef.send(RegisteredExecutor)//向远程的executor引用发送消息说在driver中已经注册好了可以启动了;
}①脚本启动,执行SparkSubmit里面的main方法;
②反射获取Client类里边的main方法;
③封装并发送指令:bin/java ApplicationMaster
④选择一台NM机器启动AM
sparkContext 构建的对象
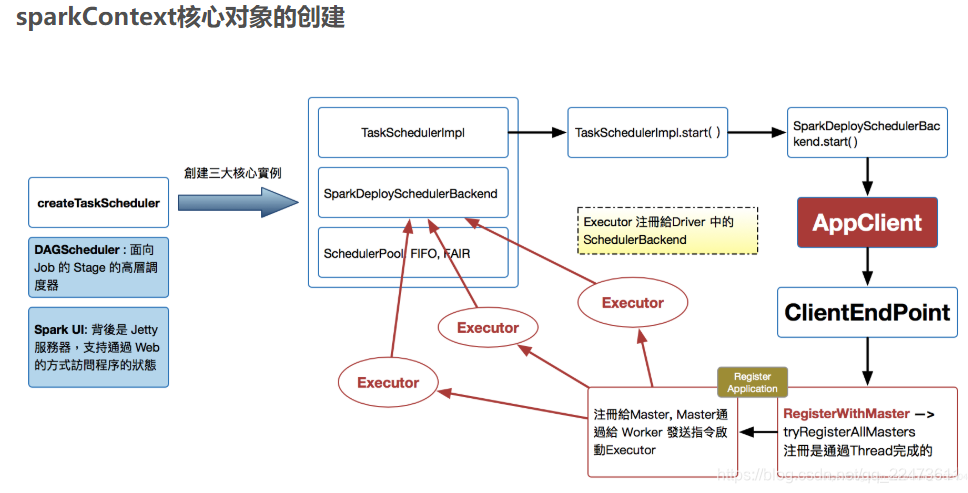
三大顶级核心:DAGScheduler, TaskScheduler, SchedulerBackend
Scheduler整体流程图
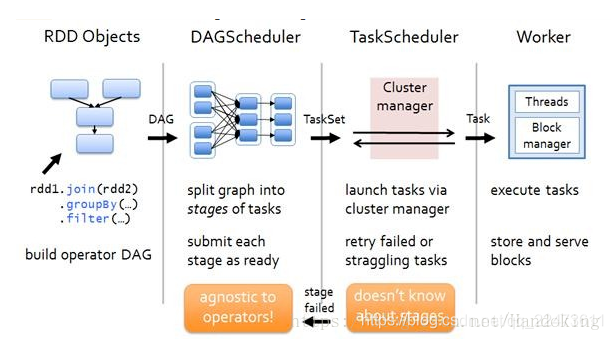
3)针对流程的解释:
1)创建RDD,经过一系列Transformation,最后Action
2)Action会出发SparkContext的runJob方法,交给DAGScheduler处理
3) DAGScheduler将DAG生成Stage
4)将Stage交给TaskScheduler
5)本地或者集群的Executor上运行
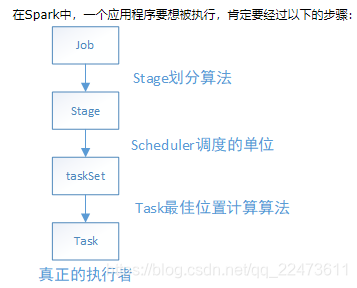
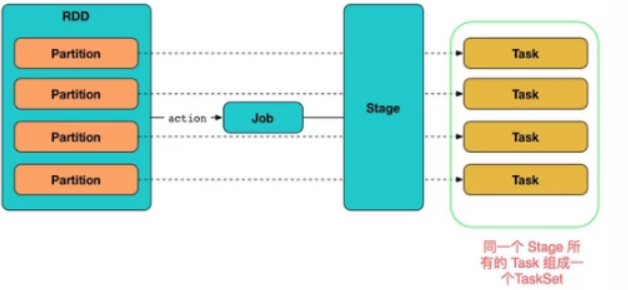
在Driver端,运行一个job时,涉及到DAGSheduler、TaskScheduler的流程如下:
1) Driver(代表一个Application)、调用applicaiton_jar.jar(应用程序入口函数),应用程序的运行过程依赖SparkContext,且需要初始化SparkContext sc,通过sc就可以创建RDD了(因为RDD是调用sc来创建的);
2)初始化SparkContext过程中会初始化DAGScheduler、TaskScheduler、ShedulerBackend;
Scheduler模块分为两大主要部分,DAGScheduler和TaskScheduler。
一、DAGScheduler
DAGScheduler把一个spark作业转换成成stage的DAG(Directed Acyclic Graph有向无环图),根据RDD和stage之间的关系,找出开销最小的调度方法,然后把stage以TaskSet的形式提交给TaskScheduler。
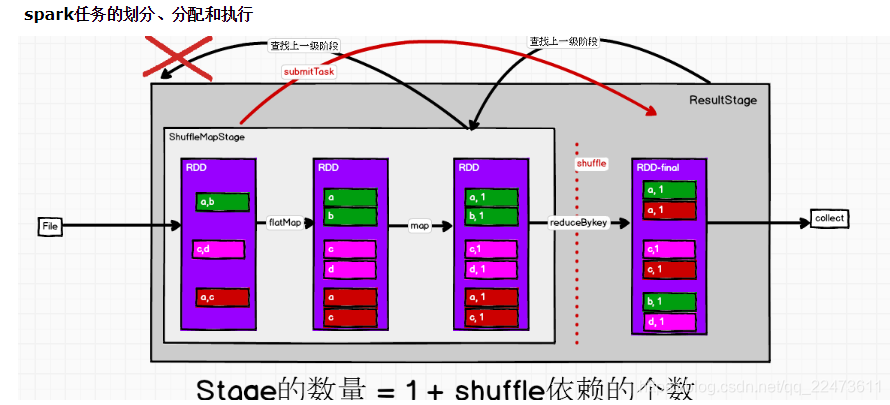
3)应用程序实际上是执行的RDD的transform或者action函数,当RDD#action函数触发时,实际上这样的action函数内部会调用sc.submitJob(...)方法,在SparkContext#submitJob(...)方法内部会根据action创建ResultStage,并找到其依赖的所有ShuffleMapStage。stage之间按照顺序执行,待前一个stage执行完成成功,才能执行下一个stage,所有stage执行成功后,该job才算执行完成。
如何来划分stage,是有相应的stage的划分算法–>就根据rdd是否宽依赖来划分的
4)DAGScheduler主要对application划分stage(宽依赖、窄依赖),创建一批task放到taskset中用于执行 application
一个 stage 里面 所有分区的任务集合 就被包装为一个 TaskSet 交给了 TaskScheduler
stage实际上可以看作为TaskSet,它实际上代表的就是一个独立的Task集合,
我们用户编程使用的 RDD, 每个 RDD都有一个分区数, 这个分区数目创建 RDD 的时候有一个初始值,运行过程中,根据配置的 parallelism 参数 和 shuffle 过程中显示指定的分区数目 来调整个数
[TaskSet] 假设我们rdd有三个分区partition,那么会产生三个task,存放到TaskSet,
二、TaskScheduler
DAGScheduler将调用TaskScheduler来对TaskSet进行作业调度;
taskScheduler就会接收到DAGScheduler的一个通知,从taskSet中推送task任务到worker中的executor进程中去执行任务,在taskscheduler中根据,程序的启动方式,创建一个实现,ShedulerBackend
5)TaskScheduler调度过程是将task序列化通过RPC传递给Executor,Executor上会使用TaskRunner来运行task;
6)TaskScheduler上task如果运行失败,TaskScheduler会重试处理;同样在stage失败后,DAGScheduler也会触发stage重试处理。
需要注意:这里如果stage失败,对当前stage重算,而不是从上一个stage开始,这样也是DAG划分stage的原因。
6. SchedulerBackend,不同的子类对应不同的集群模式
TaskScheduler的核心任务是:
接收DAGScheduler的Task请求,分发Task到集群运行并监控运行状态,并将结果以event的形式汇报给DAGScheduler 。
TaskScheduler的实现:
TaskScheduler是trait,无具体实现,仅仅为对外统一接口。任务调度模块基于两个Trait:TaskScheduler和 SchedulerBackend
TaskScheduler的工作流程图如下:
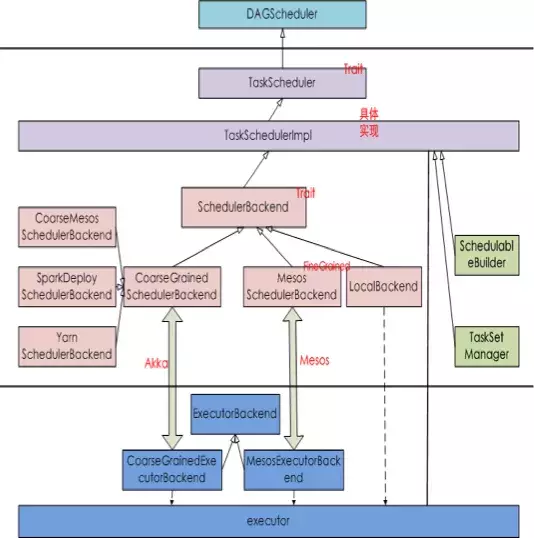
流程图核心过程介绍:
1)Task调度与低层的资源管理器分离,仅仅根据提供的资源调度task,不关心资源的来源。
2)资源调度仅仅关心资源,与多种不同的资源调度系统(YARN/MESOS/Standalone)交互,获得空闲资源。
3)TaskSchedulerImp在接收到submitTasks时,从资源调度系统中获取到空闲资源,然后将空闲资源提交到到task调度系统,调度满足locality要求的task,并将task launch到executor。
三、Scheduler整体流程,源码解析
第一个阶段: Job -> Stage.
-- 1.1 SparkContext.runJob
-- DAGScheduler.runJob() //有向无环图,有放向不能形成一个环,血缘关系形成的一个有向无环图调度器;
-- DAGScheduler.submitJob()
-- eventProcessLoop.post( JobSubmitted()) //它等同往里边放了一个样例类;发送消息JobSubmitted
-- DAGScheduler.handleJobSubmitted() //接收到JobSubmitted消息,这个方法会进行处理job并进行阶段划分 0、 handleJobSubmitted //划分阶段-Stage
private[scheduler] def handleJobSubmitted(...) {
var finalStage: ResultStage = null
try {
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
//下面介绍,生成DAG的
通过createResultStage我们拿到了最DAG的最后一个Stage(finalStage), 最后一个Stage都是ResultStage.
} catch {
…………
}
//构建job对象即一个作业;有多个行动算子即执行了多个作业;
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
finalStage.setActiveJob(job)
submitStage(finalStage) //下面介绍
submitWaitingStages()0、 createResultStage是如何生成DAG的.
Spark是如何划分Stage的:就是遇到宽依赖, 就生成新的Stage. 宽依赖会触发shuffle.
我们来看上边代码的visit函数:
拿到RDD的所有的dependency, 如果是窄依赖那么继续查找依赖的RDD的parent;
如果是宽依赖, 则调用getShuffleMapStage把生成的Stage加到当前stage的parents中.
该函数执行完毕, 则整个DAG就构建完成
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
//取出它的依赖关系,找到shuffle的依赖关系
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId) //有就拿来没有就创建新的
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
//把当前的rdd传到栈里-压栈,---不为空-->弹栈.pop()
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
} 1、计算Task的并行度
首先看DAG Scheduler提交TaskSet的方法,这个方法是submitMissingTasks(stage: Stage, jobId: Int)方法。(这个方法把stage和jobID传进去,stage存的是stage的最后一个RDD,这个RDD可以通过血缘关系将前面的RDD序列化)
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
这里创建了一个partitionsToCompute,通过findMissingPartitions()来计算分区数。
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions)
}
// numPartitions的数量
val numPartitions = rdd.partitions.length
一个Stage的Task的并行度,取决于最后一个RDD的分区数,原因就在这里。
2、计算任务运行的最佳location
现在task的分区数已经确定了,接下来就是如何将任务分配到各个节点上去,根据stage的类型,得到不同的location,通过getPreferredLocs(stage.rdd, id)方法来获取任务的运行location。
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
def getPreferredLocs(rdd: RDD[_], partition: Int): Seq[TaskLocation] = {
getPreferredLocsInternal(rdd, partition, new HashSet)
}
## 这是一个递归方法,递归地调用前面的RDD,并获取最佳location
private def getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation] = {
// If the partition has already been visited, no need to re-visit.
// This avoids exponential path exploration. SPARK-695
if (!visited.add((rdd, partition))) {
// Nil has already been returned for previously visited partitions.
return Nil
}
这里又调用了rdd.preferredLocations(rdd.partitions(partition))方法来获取最佳location。
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}
可以看到,这里使用了getOrElse()来获取最佳location。我们看getPreferredLocations(split)这个方法,它并没有被实现,但是它被HadoopRDD和ShuffledRDD实现了,我们看一下HadoopRDD的实现方法。
override def getPreferredLocations(split: Partition): Seq[String] = {
val hsplit = split.asInstanceOf[HadoopPartition].inputSplit.value
val locs = hsplit match {
case lsplit: InputSplitWithLocationInfo =>
HadoopRDD.convertSplitLocationInfo(lsplit.getLocationInfo)
case _ => None
}
locs.getOrElse(hsplit.getLocations.filter(_ != "localhost"))
}
在这里,获取到了要执行任务的location。
3、创建tasks
回到DAG Scheduler.scala。partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap我们最终得到了需要进行计算的最佳地址taskIdToLocations。
再往下,创建了一个taskBinary = sc.broadcast(taskBinaryBytes),它是一个序列化对象,通过依赖将前面的RDD也一并序列化,并把这个taskBinary广播出去。
再往下,开始创建tasks
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
// 将任务进行封装,进行调度 stage 模式匹配 ShuffleMapStage | ResultStage
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
//最优位置决定计算在哪里算,task和位置进行关联来决定在哪个executor中执行
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
//会计算分区,多少个分区变成多少个任务
//一个阶段中多个分区map转换一个分区形成一个任务
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
}
tasks的创建首先的判断stage的类型,如果是shufflemapstage,则创建ShuffleMapTask,否则创建Resulttask,这里将分区号、stageid,任务树,最佳位置等信息都传入构造方法中,创建出了一个task。
4、TaskScheduler:tasks提交到TaskScheduler,submitTasks的实现类TaskSchedulerImpl;
现在Task的创建工作也完成了,开始提交任务,首先判断Task的数量是否大于0,如果是,则创建一个taskset,将tasks、stageid,location等信息封装进去,然后由taskScheduler.submitTasks进行tasksets的提交。
//任务调度器提交任务<--if (tasks.size > 0), 把任务封装成一个TaskSet集合传进来
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
}
5、schedulableBuilder进行任务调度
taskset提交到TaskSchedulerImpl之后,先创建一个TaskSetManager,然后由SchedulableBuilder创建的schedulableBuilder来进行任务的调度,schedulableBuilder内部有一个 rootPool的数据结构,我们可以把它看成是一个任务树,所有的任务创建时都会写入到这棵任务树中,调度的过程首先是将taskSet和manager放入schedulableBuilder的rootPool中。在往后,会调用 backend.reviveOffers()方法。
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets.foreach { case (_, ts) =>
ts.isZombie = true
}
stageTaskSets(taskSet.stageAttemptId) = manager
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
submitTasks最后一步调用了LocalBackend的reviveOffers函数, 这个函数是提醒LocalBackend可以开始执行任务了.
backend.reviveOffers()会调用driverEndpoint.send(ReviveOffers)方法。
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
case ReviveOffers =>
makeOffers()
这个方法最终会调用makOffers()。
private def makeOffers() {
// Make sure no executor is killed while some task is launching on it
val taskDescs = withLock {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
launchTasks(taskDescs)
}
}
5、TaskScheduler是如何分配Task的
TaskScheduler每次把所有的TaskSet都取出来, 这些TaskSet都按照一定算法进行了排序, 排在前边的TaskSet会被优先分配Executor.
只有workoffer中Executor的空闲cpu个数大于设定的每个Task需要的cpu数量时, 才把当前的Task添加到tasks列表里.
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager, maxLocality: TaskLocality, shuffledOffers: Seq[WorkerOffer], availableCpus: Array[Int], tasks: Seq[ArrayBuffer[TaskDescription]]) : Boolean = { var launchedTask = false
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host if (availableCpus(i) >= CPUS_PER_TASK) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToTaskCount(execId) += 1
executorsByHost(host) += execId
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
}
}
} return launchedTask
} 在启动executors之前,先得到 activeExecutors,从activeExecutors里进行任务的分配,得到了一系列的workOffers,workOffers里封装了executorHost,即任务运行的excutorID,然后调用luanchTasks()方法
6、任务发送给executor
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
spark源码之stage划分,stage、task提交
Spark任务调度 任务的划分、分配、执行
实际上这样的action函数内部会调用SparkContext.submitJob(...)方法内部会根据action创建ResultStage,并找到其依赖的所有ShuffleMapStage。
stage之间按照顺序执行,待前一个stage执行完成成功,才能执行下一个stage,所有stage执行成功后,该job才算执行完成。
第一个阶段: Job -> Stage.
这个阶段主战场在DAGScheduler, 假设我们调用了reduce函数, reduce内部会调用SparkContext.runJob 函数.
在SparkContext.runJob内部,最终通过调用DAGScheduler.runJob函数把Job提交给DAGScheduler.
-- 1.1 SparkContext.runJob
-- DAGScheduler.runJob() //有向无环图,有放向不能形成一个环,血缘关系形成的一个有向无环图调度器;
-- DAGScheduler.submitJob()
-- eventProcessLoop.post( JobSubmitted()) //它等同往里边放了一个样例类;发送消息JobSubmitted
-- DAGScheduler.handleJobSubmitted() //接收到JobSubmitted消息,这个方法会进行处理job并进行阶段划分
我们看一下DAGScheduler.runjob函数:
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)//有向无环图
waiter.awaitResult() match { //...}
首先它先将job提交, 然后创建JobWaiter以阻塞的方式等待job执行结果.
接下来看一下 DAGScheduler.submitJob的过程
它向DAGSchedulerEventProcessLoop post了一个JobSubmitted事件.
eventProcessLoop.post(JobSubmitted())
DAGSchedulerEventProcessLoop接到JobSubmitted事件之后会调用DAGScheduler.handleJobSubmitted函数.
正是这个函数触发了RDD到DAG的转化.
-- 1. handleJobSubmitted // 划分阶段-Stage
private[scheduler] def handleJobSubmitted(...) {
var finalStage: ResultStage = null
try {
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite) //下面介绍,生成DAG的
} catch {
…………
}
//构建job对象即一个作业;有多个行动算子即执行了多个作业;
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
finalStage.setActiveJob(job)
submitStage(finalStage) //下面介绍
submitWaitingStages()
}
通过createResultStage我们拿到了最DAG的最后一个Stage(finalStage), 最后一个Stage都是ResultStage.
如果我们反向的遍历就能够知道整个DAG, 这个稍后我们会具体分析createResultStage的实现.
接着看handleJobSubmitted函数, 在拿到DAG的最后一个Stage后, 通过submitStage把它提交, submitStage向Executor提交Task.
我们按顺序先看createResultStage是如何生成DAG的.
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
//取出它的依赖关系,找到shuffle的依赖关系
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId) //有就拿来没有就创建新的
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
//把当前的rdd传到栈里-压栈,---不为空-->弹栈.pop()
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}
Spark是如何划分Stage的:就是遇到宽依赖, 就生成新的Stage. 宽依赖会触发shuffle.
我们来看上边代码的visit函数:
拿到RDD的所有的dependency, 如果是窄依赖那么继续查找依赖的RDD的parent;
如果是宽依赖, 则调用getShuffleMapStage把生成的Stage加到当前stage的parents中.
该函数执行完毕, 则整个DAG就构建完成.
看完DAG的构建过程, 我们继续沿着submitStage那条线看下去
-- 1.2 submitStage // 提交任务
private def submitStage(stage: Stage) {
...
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
//看看有没有上一级的阶段,即查找ShuffleMapStage
val missing = getMissingParentStages(stage).sortBy(_.id) // 提交阶段,有多少个阶段State
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
//如果上一个阶段为空没有,则submitMissingTasks提交task //如果有阶段就把上一个阶段给提交了
submitMissingTasks(stage, jobId.get) //下面介绍 ,missing表没有上级了
} else {
for (parent <- missing) {
submitStage(parent) //循环遍历提交每一个Stage
//又自己调自己,找它ShuffleMapStage的上一级,为空-->submitMissingTasks()提交任务
}
waitingStages += stage
}
}
}
这个函数非常简单, 先把当前stage的parents提交, 完事儿后在提交自己.
准备提交ResultStage时把它ShuffleMapStage取出来;
我们重点关注一下: submitMissingTasks.
/**
ShuffleMapStage
这种Stage是以Shuffle为输出边界
其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出
其输出可以是另一个Stage的开始,*输出是shuffle所需数据,
ShuffleMapStage的最后Task就是ShuffleMapTask
在一个Job里可能有该类型的Stage,也可以能没有该类型Stage。
比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,
直接就输出了,那么task只有resultTask,stage也只有一个;
如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println),
这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,
输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。
如果job中有多次shuffle,
那么每个shuffle之前都是一个stage。
ResultStage
这种Stage是直接输出结果
其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出
输出是result,
ResultStage的最后Task就是ResultTask
在一个Job里必定有该类型Stage。
*/
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
...
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
val tasks: Seq[Task[_]] = try { //构建任务集合{对stage进行操作}
// 将任务进行封装,进行调度 stage 模式匹配 ShuffleMapStage | ResultStage
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
//最优位置决定计算在哪里算,task和位置进行关联来决定在哪个executor中执行
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
//会计算分区,多少个分区变成多少个任务
//一个阶段中多个分区map转换一个分区形成一个任务
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,taskBinary, part, locs, stage.internalAccumulators)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
/**
* 一个ResultTask包含了task的定义(这个task要干什么),以及在那个partition(part)执行该task
*/
new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
} if (tasks.size > 0) {
//下面介绍
taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
...
}
}
首先先找出该stage中所有未执行过的partition, 然后把序列化后的task(taskBinary), partition(part)等信息封装成task.
ShuffleMapStage转化成ShuffleMapTask, ResultStage转化成ResultTask
ShuffleMapTask的处理过程会比较复杂一下, 因为会涉及到shuffle的过程.
这个我们后续分析Executor如何执行是再详说.
函数最后我们看到新生成的tasks封装成TaskSet提交给TaskScheduler.
到此我们分析了RDD如何转化成DAG, DAG是如何生成Task并提交的.
接下来分析Executor如何处理Task.
Executor如何处理Tasks
第一个类就是TaskScheduler, 它主要负责Task的调度工作.
第二个类是SchedulerBackend, 作用是向TaskScheduler申请任务, 并分配给Executor去执行.
SchedulerBackend可以有不同的实现. 支持本地单机运行的是LocalBackend, 支持Mesos集群运行的是MesosSchedulerBackend, etc.
下面我们分析以本地单机运行为例解释任务执行的过程.
文章上一部分分析到DAGScheduler调用TaskScheduler的submitTasks方法提交Task,
那我们接着来看submitTasks的实现类TaskSchedulerImpl;
//任务调度器提交任务<--if (tasks.size > 0), 把任务封装成一个TaskSet集合传进来
override def submitTasks(taskSet: TaskSet) {
...
backend.reviveOffers()
}
submitTasks最后一步调用了LocalBackend的reviveOffers函数, 这个函数是提醒LocalBackend可以开始执行任务了.
我们继续看reviveOffers的实现:
-- 1.2.3 启动任务:launchTasks
def reviveOffers() {
/** 向TaskSchedulerImpl申请Task */
val offers = Seq(new WorkerOffer(localExecutorId, localExecutorHostname, freeCores))
for (task <- scheduler.resourceOffers(offers).flatten) { //下面介绍
freeCores -= scheduler.CPUS_PER_TASK
executor.launchTask(executorBackend, taskId = task.taskId, attemptNumber = task.attemptNumber, task.name, task.serializedTask)
// Task开始真正执行. launchTasks(scheduler.resourceOffers(workOffers))
查找任务集 resourceOffers 看看有没有可用的资源executor,
拿到之后 launchTasks()[TaskDescription] ser.serialize(task)把任务序列化,
找到executor向它的终端发送消息--启动task,把得到的任务发送过去;
反向注册目的是启动一个Executor之后告诉Driver我准备好了-->可以发任务了;
}
}
首先, 它先向scheduler申请task. 然后把tasks提交给Executor.
在申请Task的时候, 把自己空闲的cpu个数发送给Scheduler, 以便让Scheduler按资源分配任务.
我们来看Scheduler是如何分配Task的.
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
val shuffledOffers = Random.shuffle(offers)
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet( taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
} if (tasks.size > 0) {
hasLaunchedTask = true
} return tasks
}
TaskScheduler每次把所有的TaskSet都取出来, 这些TaskSet都按照一定算法进行了排序, 排在前边的TaskSet会被优先分配Executor.
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager, maxLocality: TaskLocality, shuffledOffers: Seq[WorkerOffer], availableCpus: Array[Int], tasks: Seq[ArrayBuffer[TaskDescription]]) : Boolean = { var launchedTask = false
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host if (availableCpus(i) >= CPUS_PER_TASK) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToTaskCount(execId) += 1
executorsByHost(host) += execId
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
}
}
} return launchedTask
}
在resourceOfferSingleTaskSet函数中,
我们可以知道只有workoffer中Executor的空闲cpu个数大于设定的每个Task需要的cpu数量时, 才把当前的Task添加到tasks列表里.
以ResultTask为例:
runTask(),
shuffle前把数据写到文件里-->rdd.iterator读取数据func(context, rdd.iterator(partition, context))
-->ShuffleRDD中 compute.getReader.read() 读取的是shuffle之前往里写的数据
-->ShuffleMapTask阶段的最后一个RDD。runTask().getWriter 由它来写
总得来说任务调度的过程是:
Backend向Scheduler发出work offer, worker offer中记录着自己的基本信息, 自己的空闲资源, Scheduler根据worker offer中executor的空闲资源为其分配合适的任务.
当Backend拿到Task之后, 依次把Task提交给Executor.
TaskRunner继承了Runnable, 所以每个Task都是单独的线程去执行.
RDD读取file数据(按一行一行的读取),放到3个分区;发现0号分区不是想要的比如统计wordcount,分解产生了一个新的rdd(所有的转换算子等同于产生了一个新的rdd,rdd是不可变数据集),把一行一行数据变成一个个的flatMap;
转换结构如(a, 1)这样的结构map;reduceBykey打乱重组,产生shuffle过程
有向无环图的调度器,运行并且提交job作业(会进行简单的判断,jobWaiter传到样例类一旦发生特殊事件就产生特殊的方法 handlerJobSubmit完成了整个过程的阶段划分resultStage); 把当前作业当成一个整体,形成了一个完整的阶段称为resultStage;
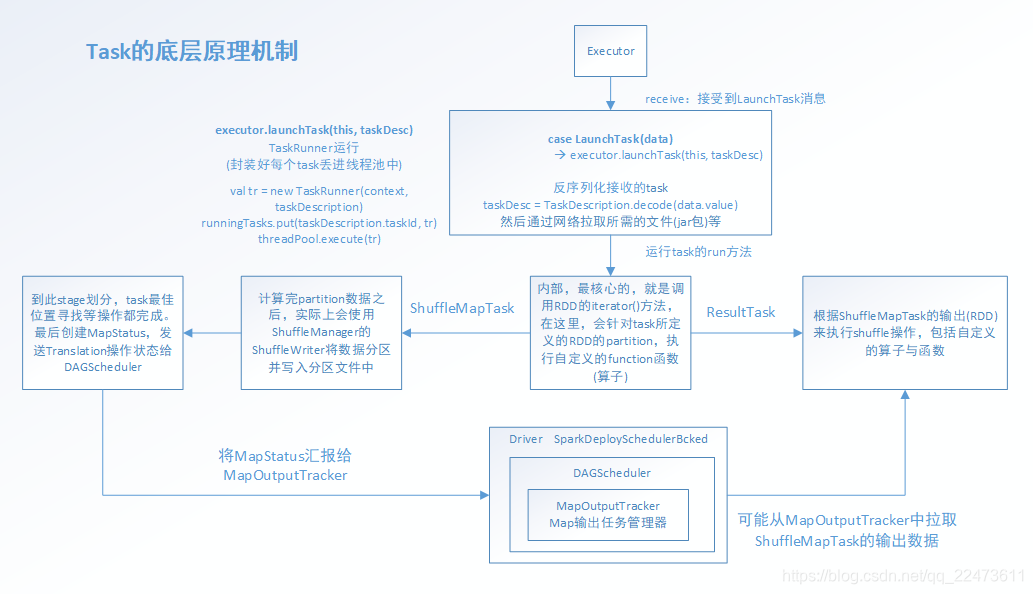
四、流程总结
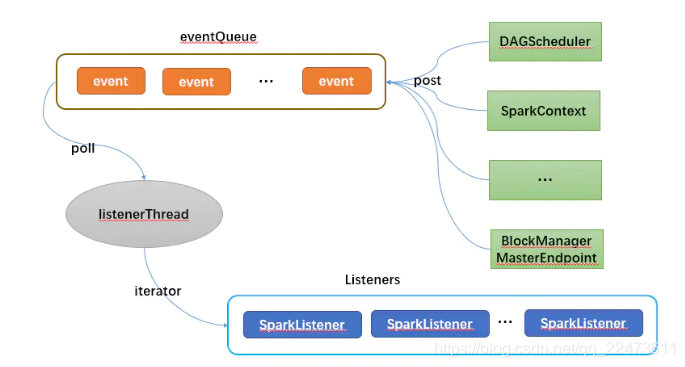
用一张图总结下的 Spark 的事件总线大致的流程:


















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











